【AWS re:Invent 2025参加レポート】個別セッションレポート「Warner Music Group: Apache Iceberg on AWS & Snowflake」
2025.12.30
- AWS
- クラウド
- データエンジニアリング

AWS re:Invent 2025で参加した個別セッションで、オープンテーブルフォーマットであるIcebergを活用した革新的なデータアーキテクチャ構築の事例発表がありました。
レイクハウスの普及とともに年々注目を集めているIcebergですが、世界的企業のデータ分析基盤実現にどのように役立てられているのか?気になる発表の内容をまとめます。
おさらい:Iceberg
Icebergは、大規模データセット向けのオープンテーブルフォーマットです。クエリエンジンとデータの間に位置する「抽象化レイヤー」として機能し、以下のような強力な機能を提供します。
- ACID特性:トランザクションの整合性を確保
- タイムトラベル:過去の時点のデータに遡って確認が可能
- パーティション進化:データの管理構造を柔軟に変更可能
- 柔軟性と効率性:データのコピーを複数持つ必要がなく、一貫したアクセスを実現
加えて、Icebergは以下のような特徴から幅広く利用されています。
- プロジェクトに勢いがあり、頻繁にアップデートされている
- 様々なクエリエンジンと統合し、エコシステムが形成されている
- 特定のベンダーやエンジンにロックインしない
相互運用可能なデータアーキテクチャの構築
Warner Music Group(以下WMG)は、75年の歴史を持ち、数多くのレーベルを抱えるレコード会社です。膨大なデータと数多くのシステムやアプリケーションをもつWMGが、いかにして複雑なマルチプラットフォーム環境を統合したのかが語られました。
マルチプラットフォーム環境における課題
WMGは非常に分権化された組織であり、各レーベルが独自にテクノロジーを選択してきた歴史があります。その結果、以下のようなマルチエンジン・マルチプラットフォーム環境が生まれていました。
- Snowflake:BI、マーケティング、アナリストチームが可視化・分析目的で利用
- Databricks:MLチームが機械学習目的で利用
WMGの社内ツール「Opus」は、独自のAPIでSnowflakeから直接データを取得していましたが、Databricks上のデータメッシュにあるデータが必要になりました。
しかし、APIは非常に多くのSnowflakeテーブルを利用しているため改修が難しく、BI/アナリストチームはSnowflakeを好んで使用しているため、Databricksへの移行も難しい状況となっていました。
Icebergによるデータへのエンジンの持ち込み
WMGはこの課題を解決するために、Icebergをプラットフォーム間の仲介役として採用しました。
従来であれば、データを一方から他方へコピー(ETL)する必要がありましたが、WMGはIcebergを活用して「データがある場所にSnowflakeを連れて行く」というアプローチを取りました。Icebergを共通言語とすることで、データを物理的に移動させることなく、SnowflakeからDatabricks(S3上のIcebergテーブル)のデータをシームレスに読み書きすることが可能になりました。
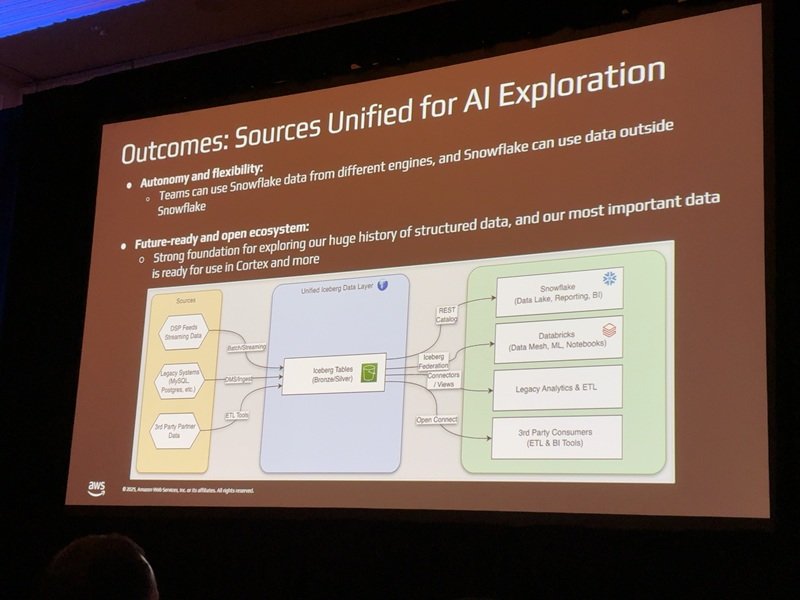
実現した驚異的な成果
このアーキテクチャの導入により、WMGは劇的な改善を実現しました。
- コスト削減:コピーやメタデータ管理のオーバーヘッドが減り、EC2利用料を70%削減
- 信頼性の向上:データレイヤーをプラットフォームに依存しない形にすることで、データの断片化を防止
- インサイト提供の高速化:複雑なインフラ構築に時間を取られることなく、AIや機械学習などの高度な分析にリソースを集中できるようになった
まとめ
WMGの事例は、Icebergが単なる技術的なフォーマットではなく、「組織の自律性」と「データの標準化」を両立させるための戦略的ツールであることを示しています。
SnowflakeやAWS、そしてNetflix、Apple、Amazonといった大手企業が強力に推進するIcebergは、今やデータプラットフォーム間の「API」としての役割を担いつつあります。今後、AIや機械学習のワークロードがさらに多様化する中で、Icebergの存在はますます大きなものになっていきそうです。
RELATED ARTICLE関連記事
2025.12.05
【AWS re:Invent 2025参加レポート】個別セッションレポート「ベクトル、ハイブリッド、AI技術で高度なエンタープライズ検索を構築」
- AWS
- クラウド
- 生成AI
2025.12.05
【AWS re:Invent 2025参加レポート~4日目~】Infrastructure Innovations with Peter DeSantis and Dave Brownまとめ
- AWS
- クラウド
- 生成AI
2025.12.04
【AWS re:Invent 2025参加レポート~3日目~】Agentic AI Keynote with Dr. Swami Sivasubramanianまとめ
- AWS
- クラウド
- 生成AI
2025.12.03
【AWS re:Invent 2025参加レポート~2日目~】Opening Keynote with Matt Garman まとめ
- AWS
- インフラ
- クラウド
- 生成AI
2025.12.02
【AWS re:Invent 2025参加レポート~1日目~】AWS re:Inventとは?会場の様子を交えて紹介!
- AWS
- インフラ
- クラウド
- セキュリティ
- データエンジニアリング
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

