Streamlit in Snowflake 入門ガイド:アプリ作成の基本を丁寧解説
2025.06.23
- Snowflake
- クラウド
- データエンジニアリング
Snowflake では Streamlit in Snowflake というサービスを提供しており、Streamlitアプリを簡単に作成・共有することができます。本記事では「Streamlit が気になっているけれど触ったことがない」「使い方がよくわからない」という方を対象に、基本から丁寧に解説します。
Streamlit とは?
Streamlit はウェブアプリケーションを簡単に作成・共有することができるオープンソースのPythonライブラリです。ボタン、スライダー、チャート、ファイルのアップロード機能など多数のUIウィジェットが用意されており、数行のコードでそれらを利用することができます。
Streamlit の大きな特徴は以下の3つです:
- APIがシンプルで使いやすい
- UIの実装が簡単
- デプロイが簡単
HTML, CSS, JavaScriptといったフロント部分の開発やルーティング、リクエストのハンドリングといったバックエンド部分の対応も必要なく、高品質なアプリケーションをスピーディーに構築・展開できることが最大の強みとなっています。
Streamlit in Snowflake
Streamlit in Snowflake は Snowflake における Streamlit の組み込みサービスであり、Streamlitアプリを Snowflake 上で作成・共有することが可能です。
活用のメリット
Streamlit in Snowflake を活用する主なメリットとしては以下が挙げられます。
- ストレージと計算リソースは Snowflake が管理するため、ユーザが別途リソースを用意する必要がない。
- Snowflake 内部で処理が完結するため、セキュリティを高めると同時に運用が効率化される。
- Snowflake の Role-based Access Control (RBAC) に基づくアクセス管理が可能。
- Snowpark 等の Snowflake のフレームワークや機能を利用することができる。
ただし、以下のような制限もあるため注意が必要です。
制限
公式ドキュメントに記載されている制限は以下の通りです。
- Streamlitの一部機能がサポートされていない(ファイルアップローダー、カメラ入力、ページ設定など)
- 外部リソースの読み込み制限
- データ取得制限(1回のクエリで取得できる最大データ量は32MB)
- サーバ側の暗号化を使うステージはサポートしていない
- キャッシュ機能が完全にはサポートされていない
アプリ作成(Snowsight)
Snowflake では、Snowsight(Snowflake のWeb UI)から簡単にアプリを作成することができます。
メニューの「プロジェクト」→「Streamlit」を開き、「+Streamlitアプリ」をクリックします。
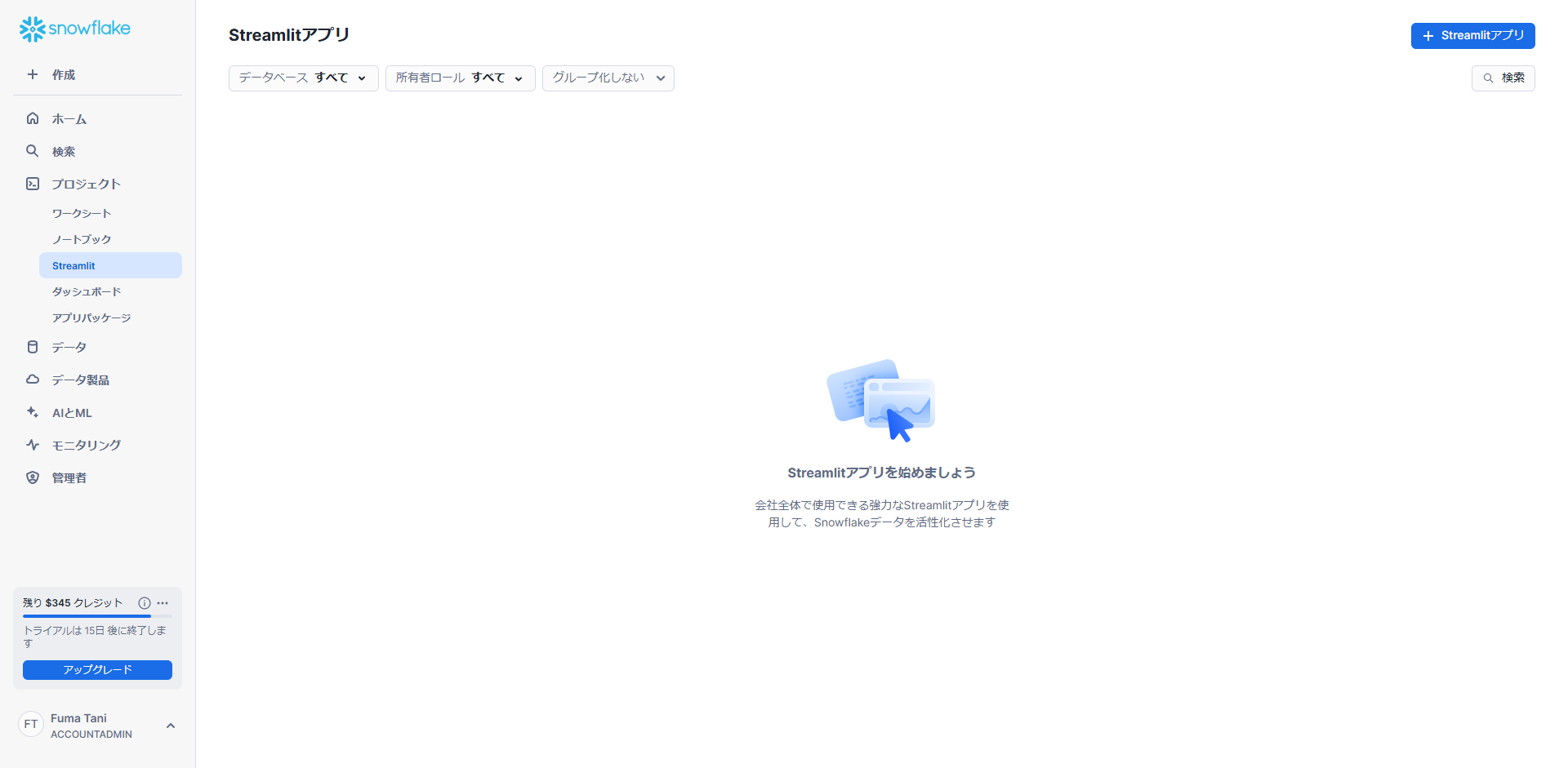
アプリの作成画面が開くため、アプリのタイトル、保管場所となるデータベースとスキーマ、ウェアハウスを指定して「作成」をクリックします。
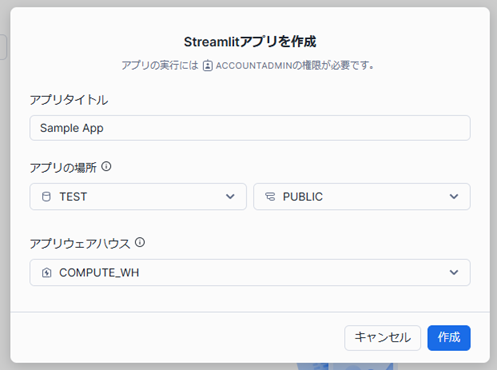
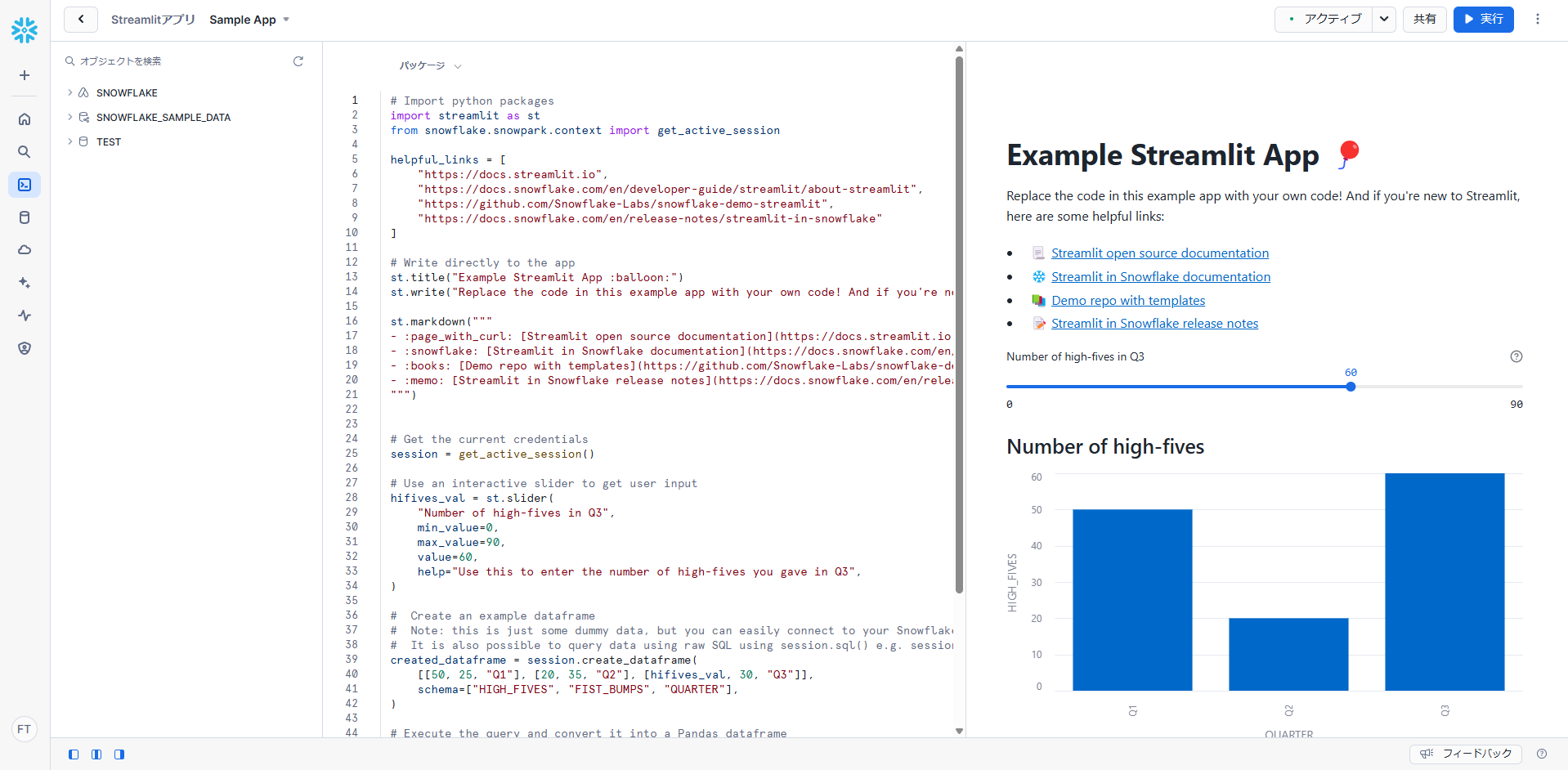
少し待つと、サンプルプログラムの編集画面とアプリのプレビューが表示されます。
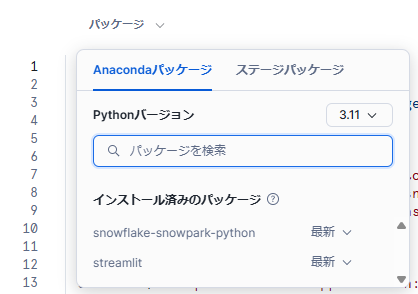
外部パッケージを利用する場合、編集画面上部の「パッケージ」から追加を行います。
こちらで作成した全国人口統計データをもとに、以下のプログラムを作成しました。
import streamlit as st
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark.functions import col
# タイトル
st.title("全国人口統計データ確認アプリ")
st.write("1920年から記録されている日本の全国人口統計データ確認用アプリ")
# セッション取得
session = get_active_session()
# データ取得
snow_df = session.table('TEST.PUBLIC.POPULATION_PREPARED')
snow_df = snow_df.filter(col("PREFECTURES") == '全国').select("YEAR", "POPULATION", "MAN_POPULATION", "WOMAN_POPULATION").sort("YEAR")
snow_df = snow_df.with_column_renamed(col("YEAR"), "年").with_column_renamed(col("POPULATION"), "人口(総数)").with_column_renamed(col("MAN_POPULATION"), "人口(男)").with_column_renamed(col("WOMAN_POPULATION"), "人口(女)")
df = snow_df.to_pandas()
# 全国人口推移グラフ
st.subheader("全国人口推移")
st.line_chart(
data=df,
x="年",
color=["#ff4500", "#0000ff", "#008000"]
)
# 選択した都道府県のデータを表示
st.subheader("都道府県別人口推移")
target_prefecture = st.selectbox(
"表示したい都道府県を選択してください。",
("北海道", "青森県", "岩手県", "宮城県", "秋田県", "山形県", "福島県", "茨城県", "栃木県", "群馬県", "埼玉県", "千葉県", "東京都", "神奈川県", "新潟県", "富山県", "石川県", "福井県", "山梨県", "長野県", "岐阜県", "静岡県", "愛知県", "三重県", "滋賀県", "京都府", "大阪府", "兵庫県", "奈良県", "和歌山県", "鳥取県", "島根県", "岡山県", "広島県", "山口県", "徳島県", "香川県", "愛媛県", "高知県", "福岡県", "佐賀県", "長崎県", "熊本県", "大分県", "宮崎県", "鹿児島県", "沖縄県")
)
snow_df = session.table('TEST.PUBLIC.POPULATION_PREPARED')
snow_df = snow_df.filter(col("PREFECTURES") == target_prefecture).select("YEAR", "POPULATION", "MAN_POPULATION", "WOMAN_POPULATION").sort("YEAR")
snow_df = snow_df.with_column_renamed(col("YEAR"), "年").with_column_renamed(col("POPULATION"), "人口(総数)").with_column_renamed(col("MAN_POPULATION"), "人口(男)").with_column_renamed(col("WOMAN_POPULATION"), "人口(女)")
df = snow_df.to_pandas()
st.line_chart(
data=df,
x="年",
color=["#ff4500", "#0000ff", "#008000"]
)
Snowpark を利用してテーブルからデータを取得し、全国と都道府県別の人口推移グラフを表示するプログラムとなっています。
実行すると、思い通りのアプリが作成されました。
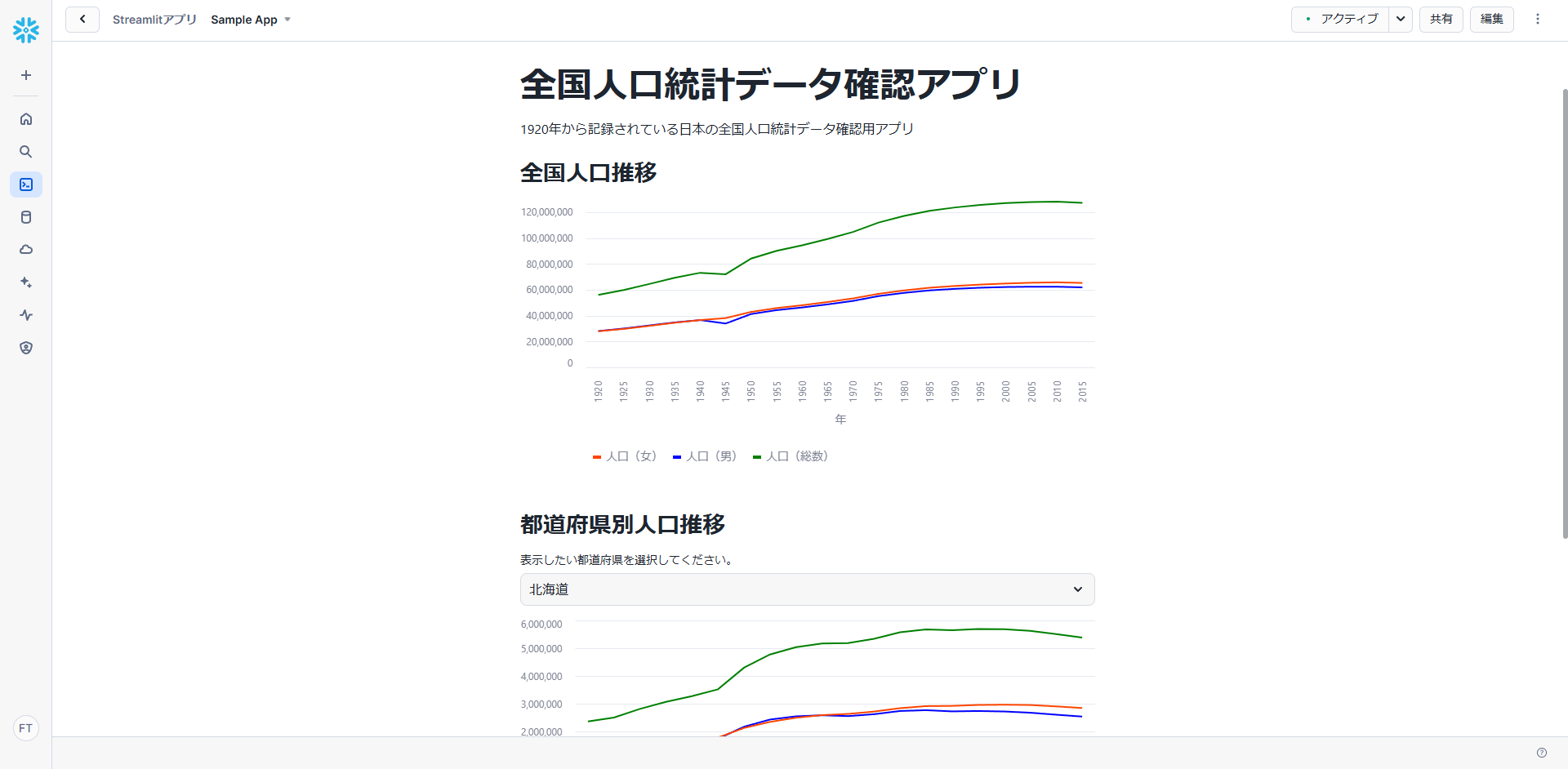
都道府県別人口推移では、プルダウンから都道府県を選択することで動的に対象の都道府県の人口推移グラフが表示されます。
「共有」ボタンを押すとウィンドウが表示され、共有対象のロールの設定とアクセス用リンクの取得を行うことができます。
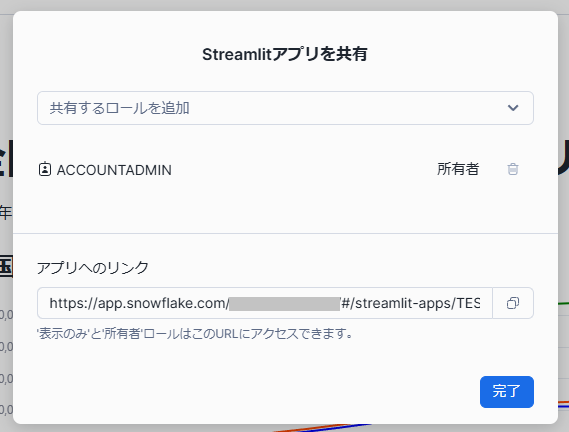
※アプリを表示するためには Snowflake アカウントが必要です。
アプリ作成(ローカルからデプロイ)
Snowsight 上で直接アプリを作成することは可能ですが、以下の課題があります。
- 編集できるのはメインのPythonファイルのみで、追加資材(Pythonプログラムから読み込むデータファイルなど)をアップロードして使用することができない
- 複数ページにできない
ローカルからデプロイすることで、上記の課題を解決することができます。
プログラム作成
今度は、機械学習でよく用いられるアヤメの分類データ(Iris dataset)をもとに機械学習モデルを作成し、そのモデルを用いたアヤメの分類アプリを作成します。
はじめに、以下のPythonプログラムを実行しモデルの学習と保存を行います。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from joblib import dump
def main():
# データのロード
iris = load_iris()
X, y = iris.data, iris.target
# モデルの学習
model = RandomForestClassifier()
model.fit(X, y)
# 学習済みモデルの保存
dump(model, "model.joblib")
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"Error: {e}")
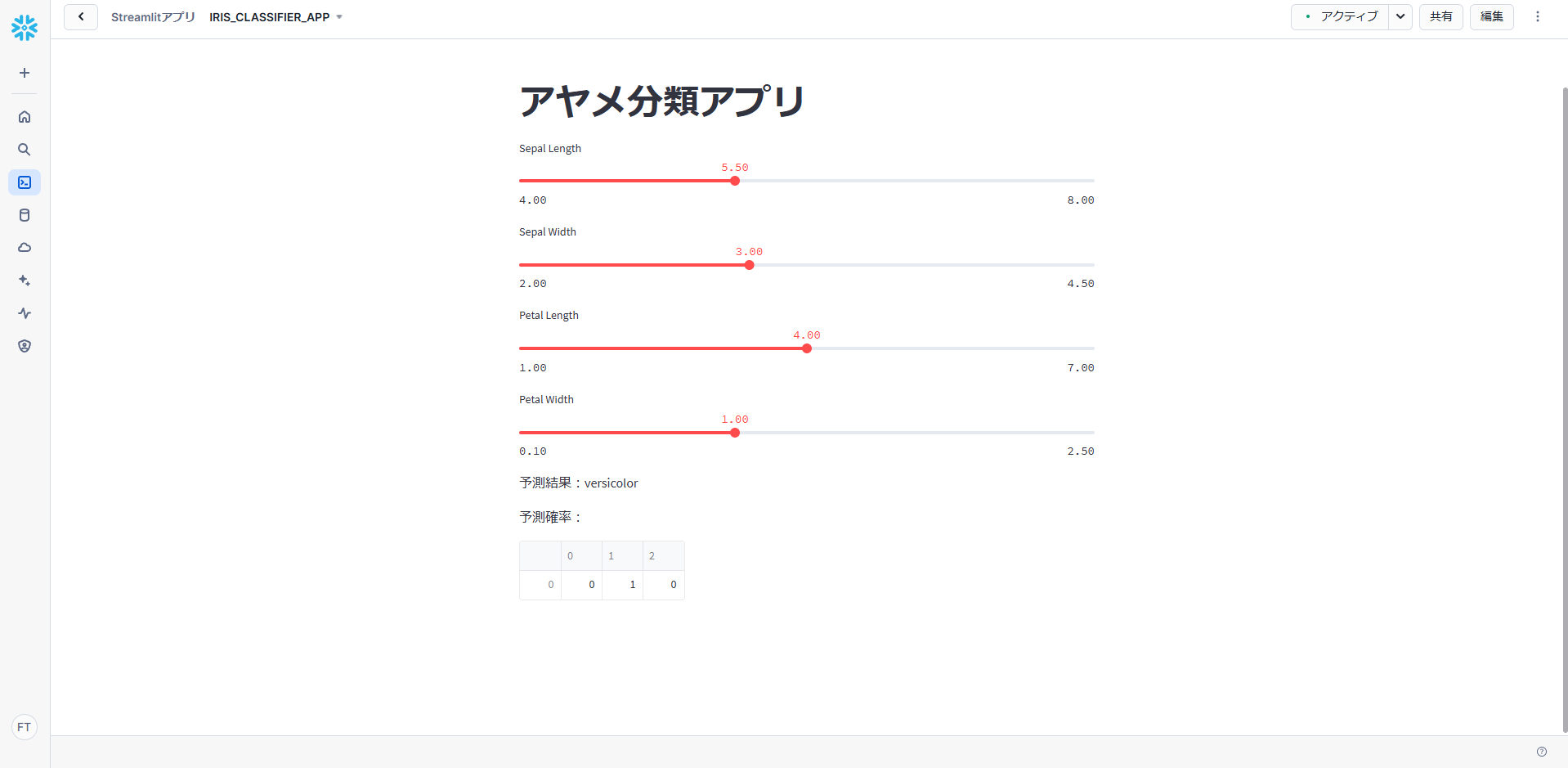
model.joblib ファイルが作成されたら、以下のプログラムを app.py として保存します。
from sklearn.datasets import load_iris
import streamlit as st
from joblib import load
import numpy as np
iris = load_iris()
# 学習済みモデルの読み込み
model = load("model.joblib")
# アプリタイトル
st.title("アヤメ分類アプリ")
# ユーザー入力を受け取る
sepal_length = st.slider("Sepal Length", 4.0, 8.0, 5.5)
sepal_width = st.slider("Sepal Width", 2.0, 4.5, 3.0)
petal_length = st.slider("Petal Length", 1.0, 7.0, 4.0)
petal_width = st.slider("Petal Width", 0.1, 2.5, 1.0)
# 予測の実行
input_data = np.array([[sepal_length, sepal_width, petal_length, petal_width]])
prediction = model.predict(input_data)
prediction_proba = model.predict_proba(input_data)
# 結果の表示
st.write(f"予測結果: {iris.target_names[prediction[0]]}")
st.write("予測確率:")
st.write(prediction_proba)
一度、ローカル環境で以下のコマンドを実行し動作確認してみます。
streamlit run app.py
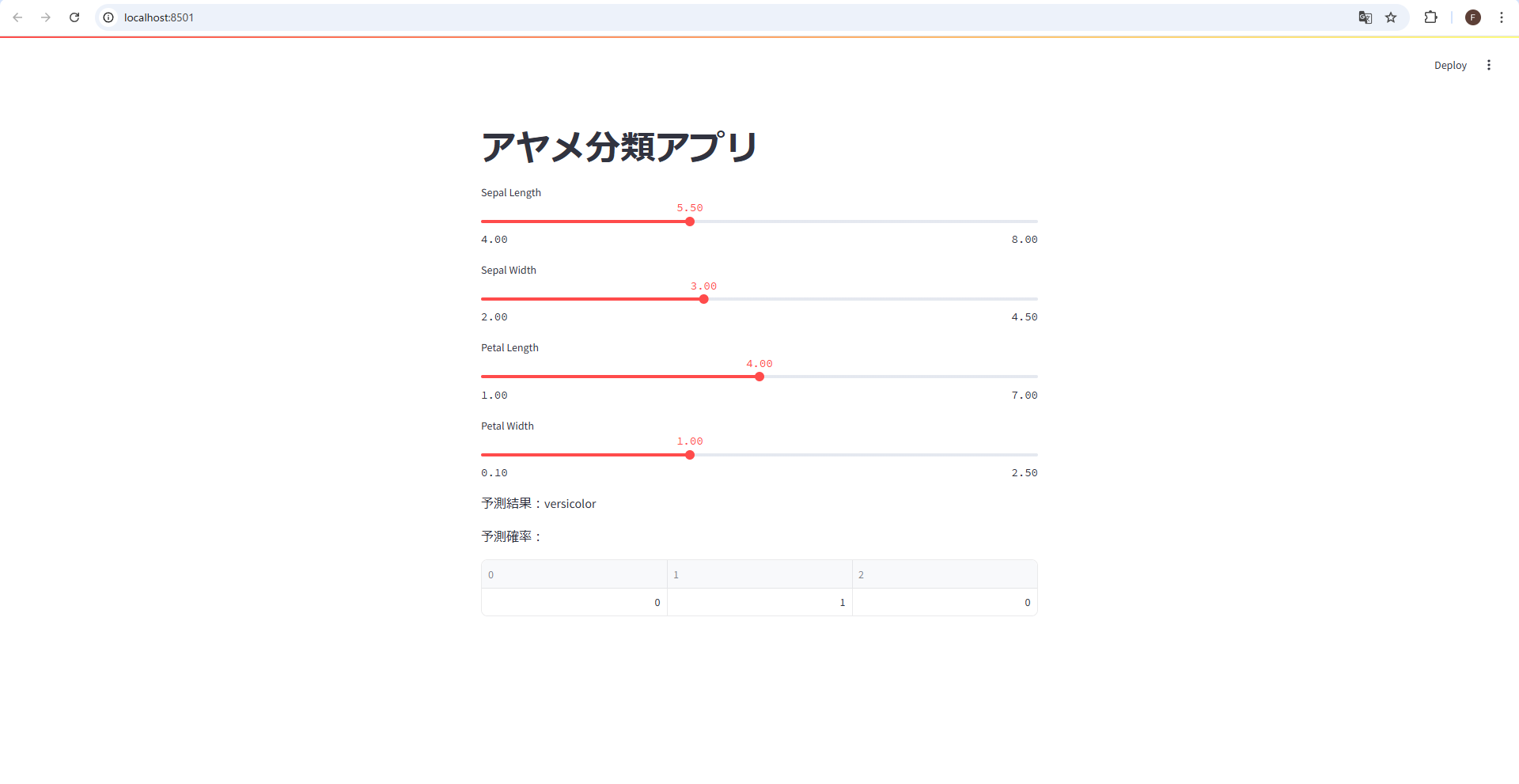
問題なく動作していることが確認できたら、プログラムで利用するライブラリの依存関係を記載した以下のファイルを environment.yml として保存します。
name: app_env
channels:
- snowflake
dependencies:
- scikit-learn
- joblib
- numpy
ステージ作成
メニューの「+作成」をクリックし、「ステージ」→「Snowflakeによる管理」をクリックします。
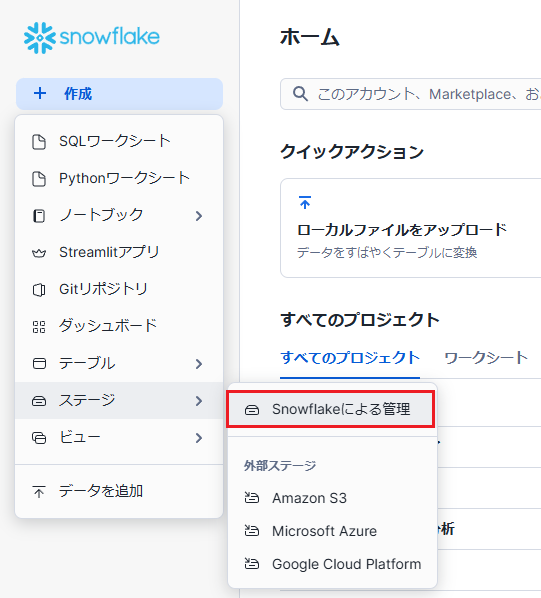
ステージ作成ウィンドウが開くため、ステージ名とスキーマ、暗号化(クライアント側の暗号化)の設定を行い「作成」をクリックします。
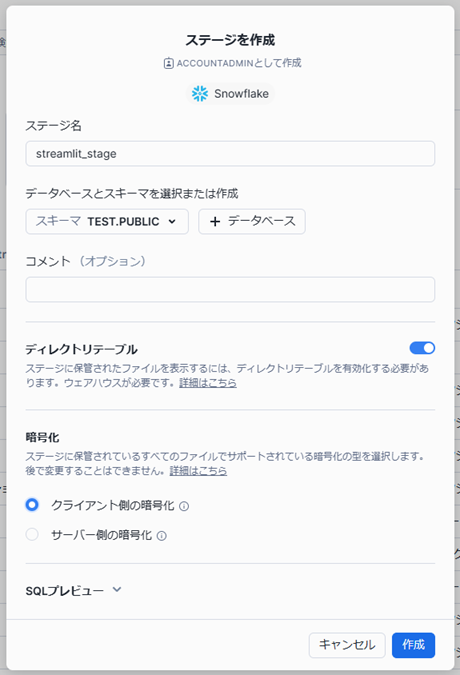
指定した場所にステージが作成されます。
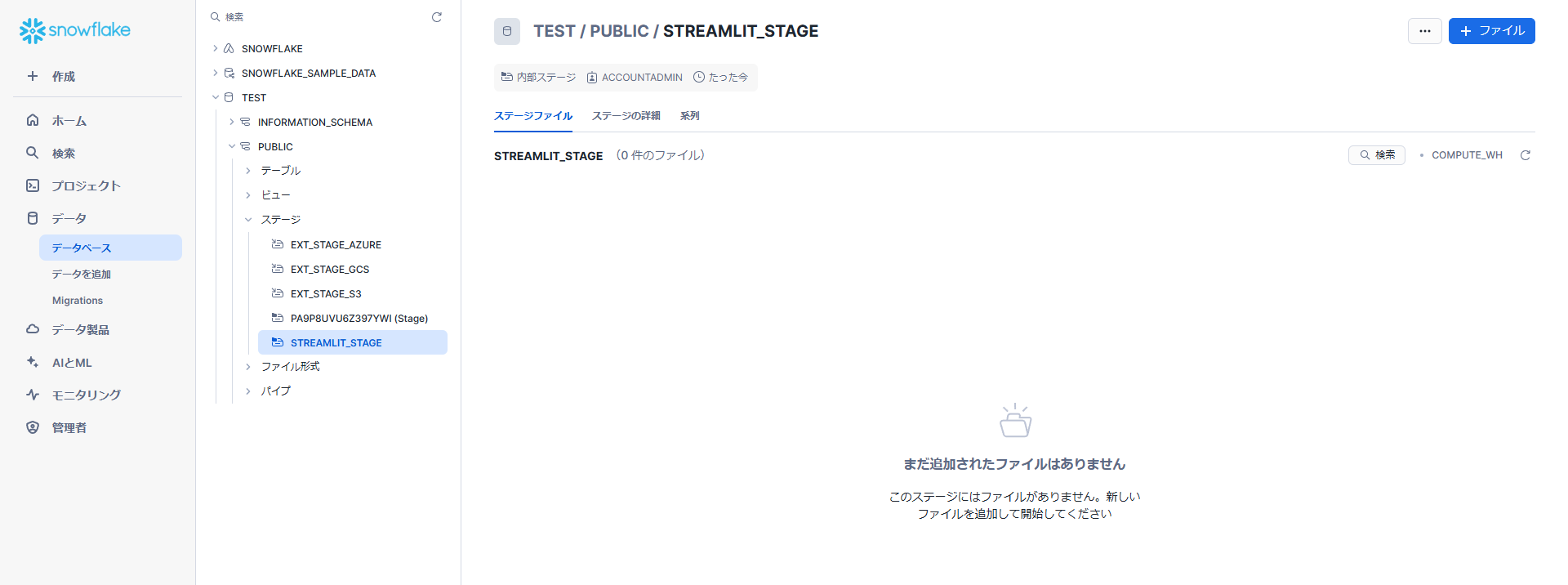
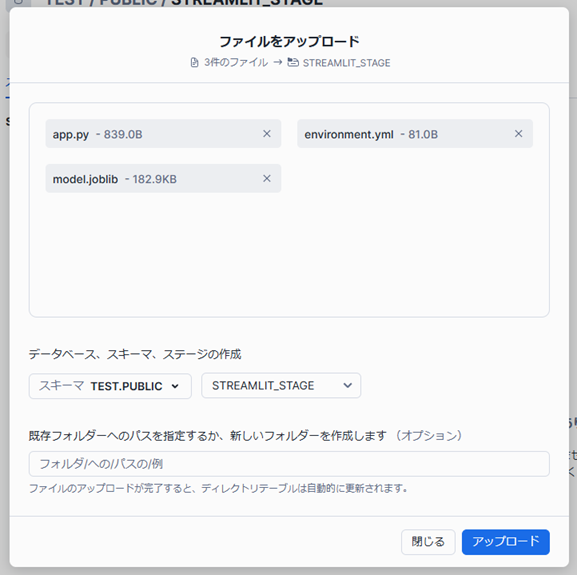
ステージ詳細画面の「+ファイル」でファイルのアップロードを行います。以下の3つのファイルをアップロードします。
- app.py
- environment.yml
- model.joblib
デプロイ
ワークシートを開いて以下のSQLを実行し、作成したステージ(STREAMLIT_STAGE)をROOT_LOCATIONとしてアプリをデプロイします。
CREATE OR REPLACE STREAMLIT iris_classifier_app
ROOT_LOCATION = '@TEST.PUBLIC.STREAMLIT_STAGE'
MAIN_FILE = 'app.py'
QUERY_WAREHOUSE = COMPUTE_WH;
問題なくデプロイされると、Streamlitアプリ一覧に作成したアプリが表示されます。
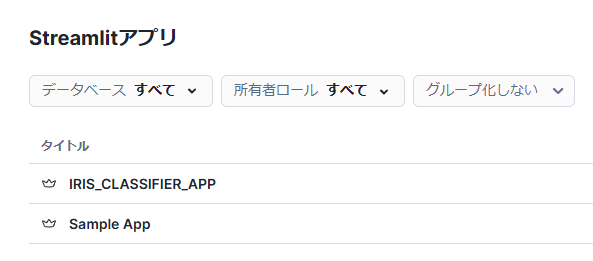
アプリをクリックすると、ローカルで確認したときと同じようにアプリが表示されます。
注意点
便利な Streamlit in Snowflake ですが、以下のような注意点もあります。
1. アプリ起動中は常に課金される
アプリを起動している間はウェアハウスが立ち上がったままとなり、クレジットが消費されていきます。
プログラムを編集しながら動作確認をしていると、その間ずっと課金されてしまいます。
2. Snowpark DataFrameのキャッシュ化ができない
Streamlitはインタラクションが発生するたびにプログラム全体が実行されるため、データロードの関数などはキャッシュ化をしておきたいところですが、2025年4月時点で以下のような実装には対応していません。(UnevaluatedDataFrameErrorになります)
@st.cache_data
def load_data(table):
df = session.table(table)
return df
df.to_pandas()でキャッシュ化可能な形に直せば問題ないですが、Snowpark DataFrame のまま扱うことはできません。
3. 共有方法が限定的
アプリの共有先は以下の2パターンとなっています。
- リンクを知っている「View only」または「Owner」ロール
- 明示的に指定したロール
共有対象のユーザは Snowflake アカウントを持っているユーザに限られており、Snowflake アカウントを持っていない一般ユーザにアプリを共有することはできません。
まとめ
Streamlit in Snowflake により、Snowflake の基盤を活用したStreamlitアプリを簡単に作成・共有することができます。Snowflake 内で処理が完結するだけでなく、RBACによるアクセスコントロールや Snowpark を利用したデータ処理が行えるため、Snowflake と連携したアプリをササッと作って共有したいという場合にうってつけです。
一方で、課金やキャッシュ化、共有方法などで注意が必要な点もあるため、ユースケースに応じて適切に利用することが重要です。
参考
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

