Snowflake入門:データ取り込みから可視化まで
2025.04.18
- Snowflake
- クラウド
- データエンジニアリング
Snowflake を使い始めたばかりで使い方がよくわからない、データの取り込みや分析はどうやってすればよいの?という方を対象に、基本操作をハンズオン形式でシンプルに解説します。
本記事を読むことで、Snowflake へのデータ取り込み、テーブル作成からダッシュボードによる可視化までの一連の操作方法を知ることができます。
データ準備
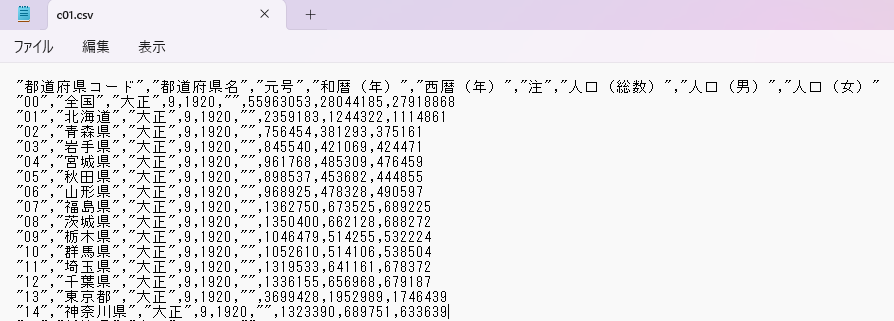
はじめに、取り込み元のデータとして政府が公開している人口統計データをダウンロードしておきます。
中身は以下のようなCSVデータで、全国と都道府県の人口統計データが記録されています。
データベース作成
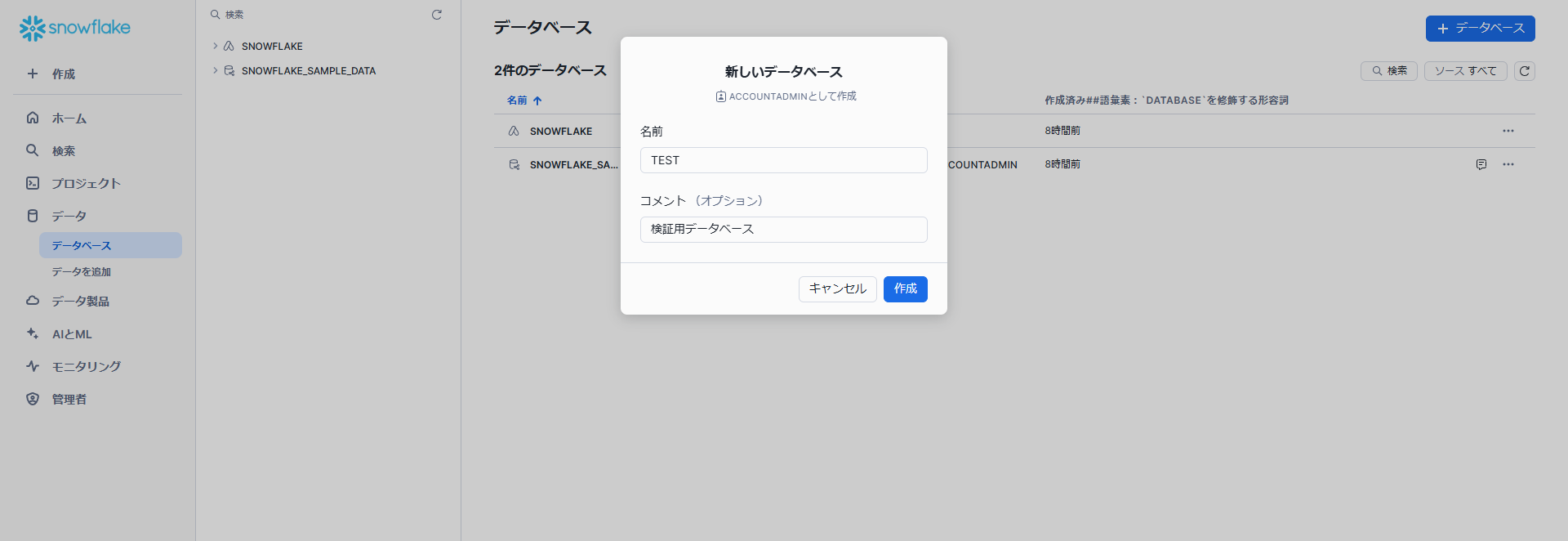
メニューの「データ」→「データベース」を開き、「+データベース」ボタンをクリックします。
新しいデータベースの名前を入力し作成をクリックします。
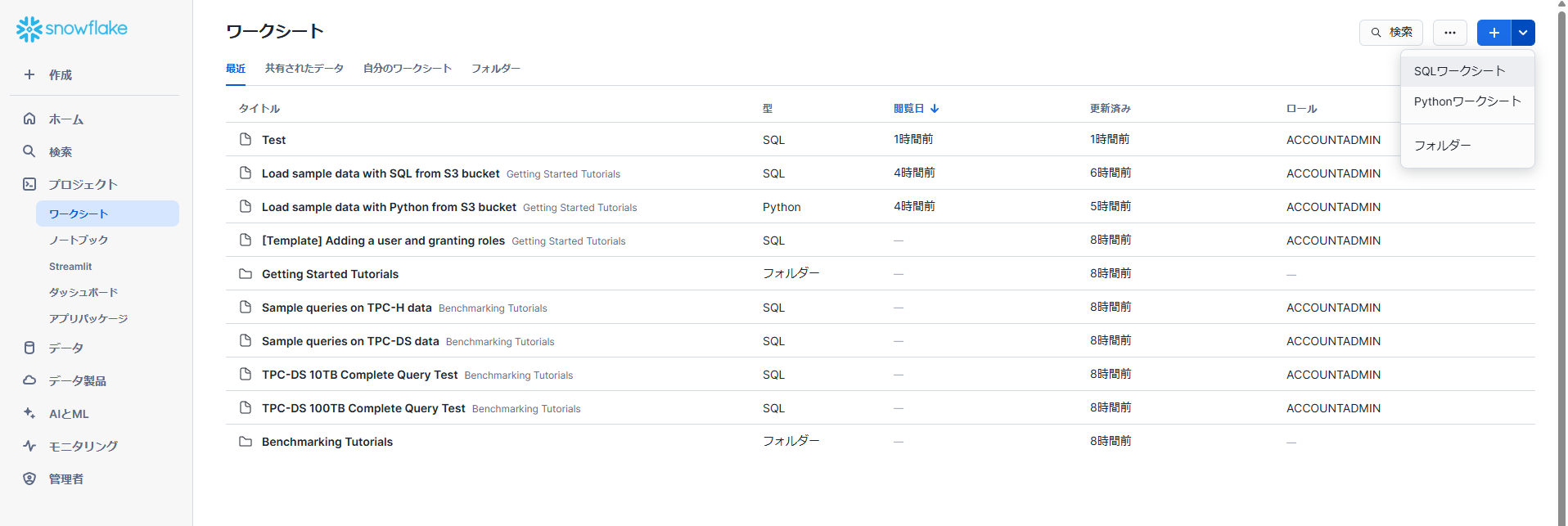
「プロジェクト」→「ワークシート」を開き、右上のボタンで「SQLワークシート」をクリックします。
新規作成されたワークシートが開きます。
ワークシート名はタブ部分をダブルクリックするか、一覧の表示から変更できます。
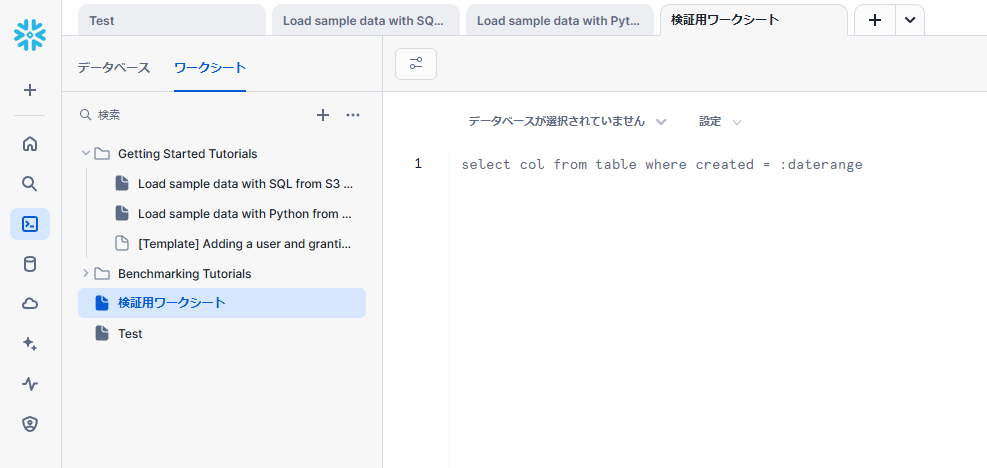
データベースをTEST、スキーマをPUBLICとして設定します。
※データベース、スキーマを設定しておくことで、SQL文中で明示的にデータベースとスキーマを指定する必要がなくなるので便利です。
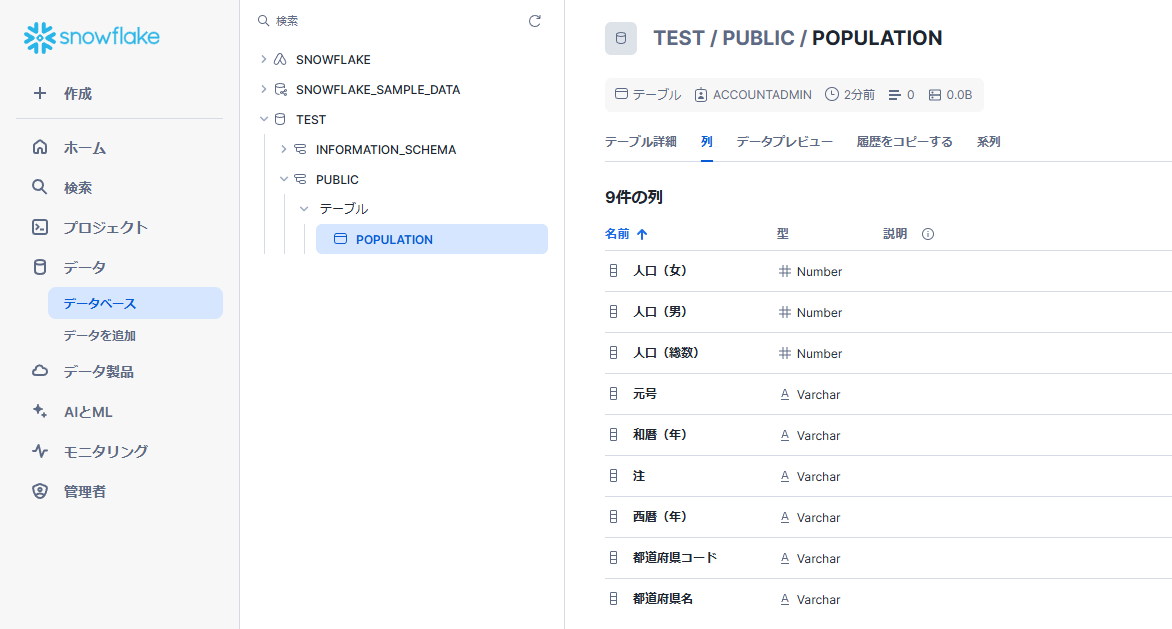
以下のSQLを実行し、populationテーブルを作成します。
CREATE OR REPLACE TABLE population (
"都道府県コード" STRING,
"都道府県名" STRING,
"元号" STRING,
"和暦(年)" STRING,
"西暦(年)" STRING,
"注" STRING,
"人口(総数)" INTEGER,
"人口(男)" INTEGER,
"人口(女)" INTEGER
);
データベースから作成されたテーブルを確認できます。
データロード
先ほどダウンロードした人口統計データのファイルを Snowflake にアップロードします。
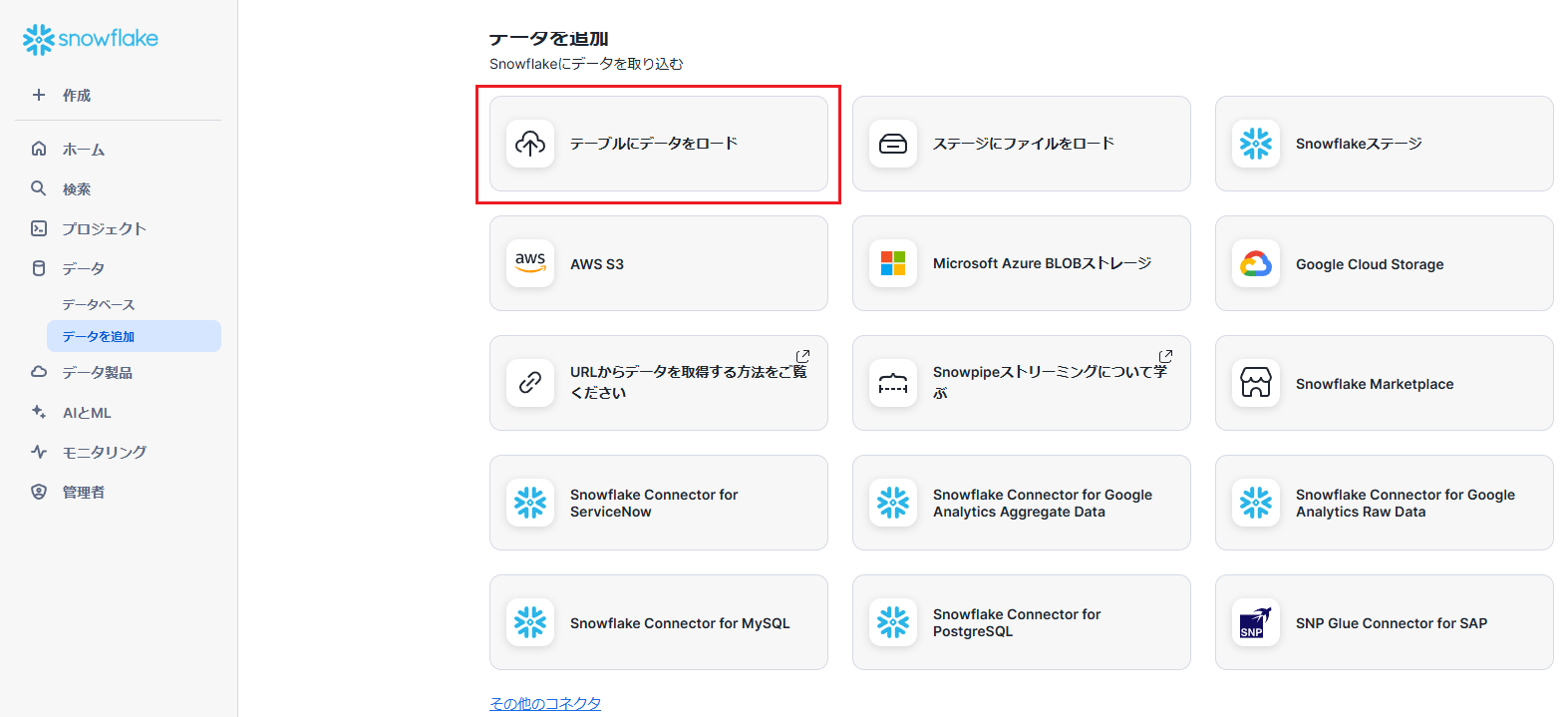
「データ」→「データを追加」から「テーブルにデータをロード」を選択します。
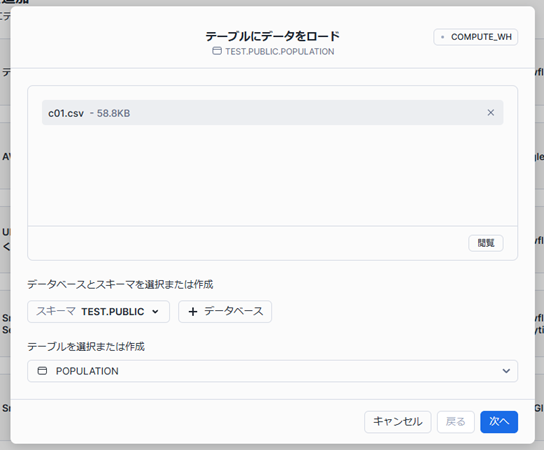
ファイルをアップロードし、ロード対象のデータベースとスキーマ、テーブルを選択して「次へ」をクリックします。
※ファイルの文字コードは UTF-8 にしておきます。
ロードの画面が開いたら、左側でロードの設定を行います。今回はファイル形式を Delimited Files (CSV or TSV) とし、ヘッダー行を含むため「最初の行をスキップ」としました。残りはデフォルト設定のままです。
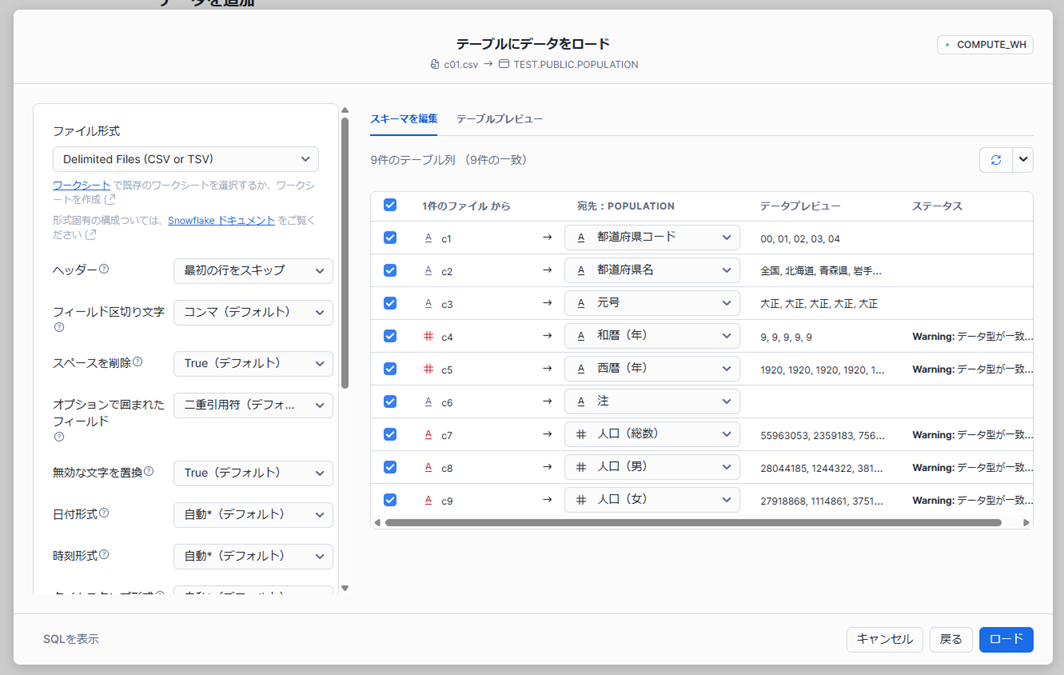
設定が正しくできていないかファイルを正常に読み込めない場合は右側がエラー表示になります。その場合、ファイルに異常がないか、設定が適切にできているかを再度確認しましょう。設定が完了したら「ロード」をクリックします。
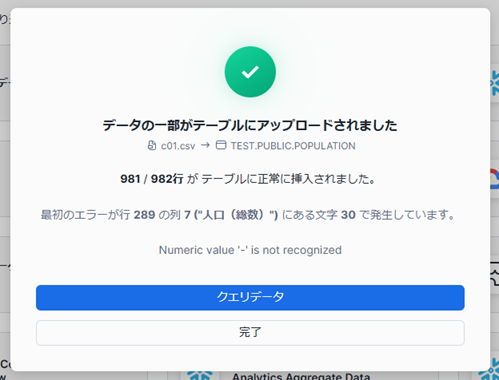
ロードに失敗しました。。
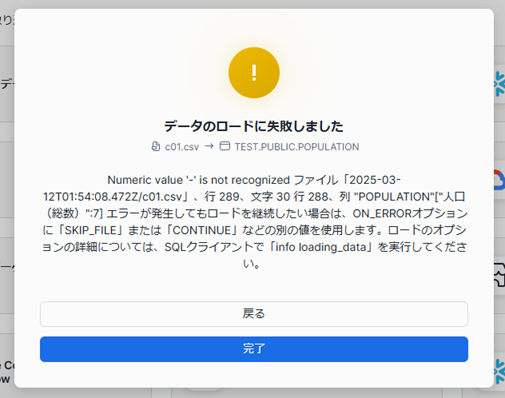
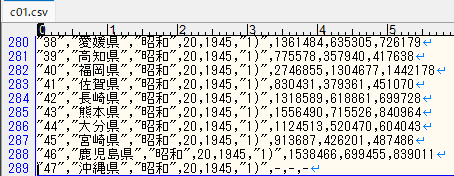
エラー箇所を確認したところ、沖縄県で人口が「-」になっている所がありました。
そのままでは読み込めないデータが含まれているので、設定に戻りロード時にエラーが発生した場合の設定を「ファイルから有効なデータのみをロード」に変更します。
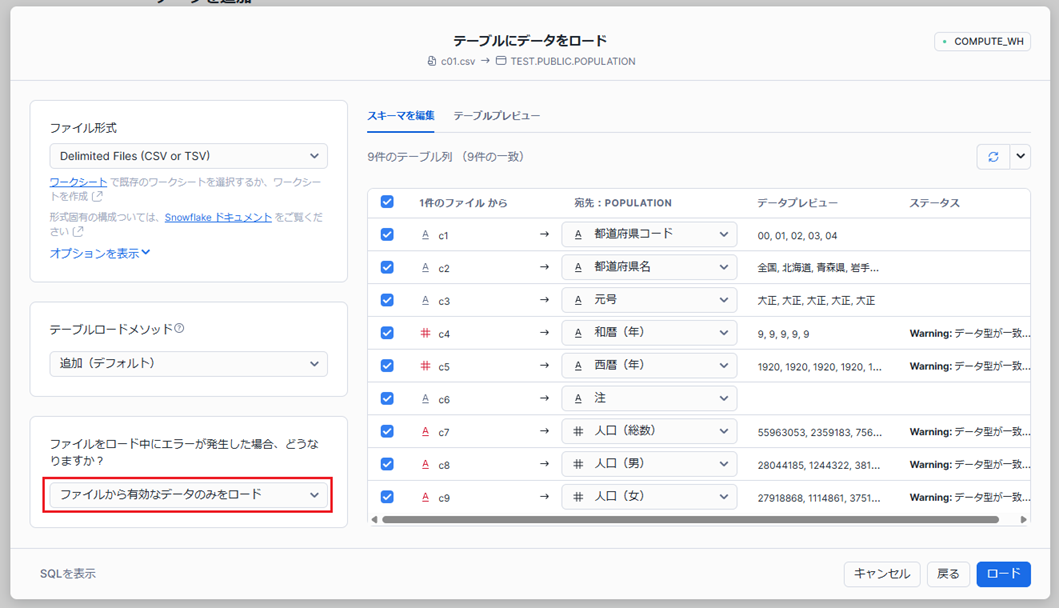
再度ロードを実行すると、今度は正常にデータが挿入されました。
テーブルデータにもデータが入っていることが確認できます。
クエリ実行、分析
無事にデータを取り込むことができたので、クエリの実行と分析を行っていきます。
以下のSQLを実行し、カラム名を日本語から英語に変換したpopulation_renamedテーブルを作成します。
CREATE TABLE population_renamed (
prefectures_code STRING,
prefectures STRING,
era STRING,
year_jp STRING,
year STRING,
note STRING,
population INTEGER,
man_population INTEGER,
woman_population INTEGER
) AS SELECT * FROM population;
テーブルが作成されました。
以下のSQLを実行し、注釈などの余分なデータを除いたpopulation_preparedテーブルを作成します。
CREATE TABLE population_prepared
AS SELECT * FROM population_renamed
WHERE prefectures_code RLIKE '\\d{2}';

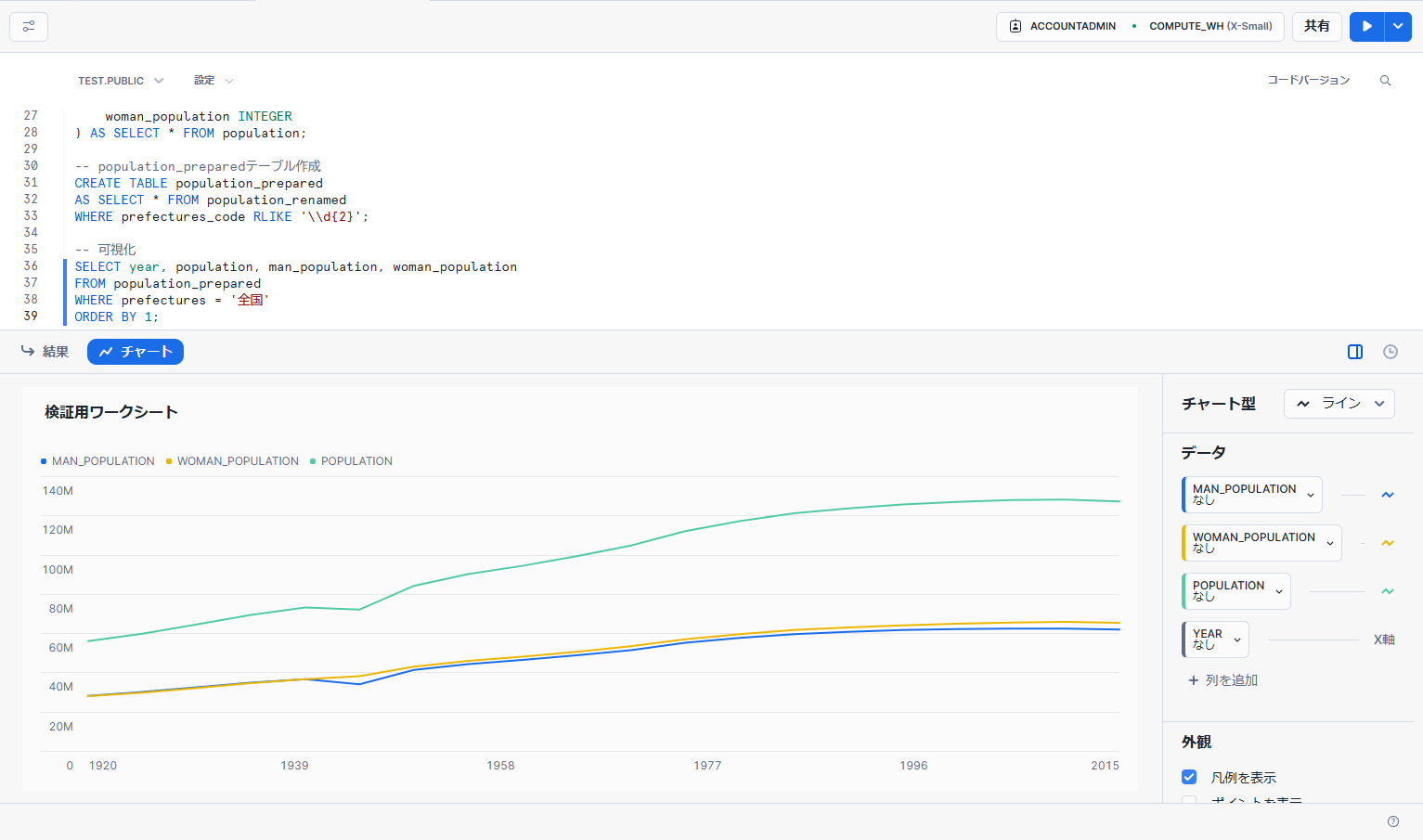
年ごとの全国人口推移を可視化するため、以下のSQLを実行します。
SELECT year, population, man_population, woman_population
FROM population_prepared
WHERE prefectures = '全国'
ORDER BY 1;
ワークシート下部の「チャート」をクリックし、以下のように設定します。
- チャート型:ライン
- データ
- MANPOPULATION(用途:ライン、集計:なし)
- WOMANPOPULATION(用途:ライン、集計:なし)
- POPULATION(用途:ライン、集計:なし)
- YEAR(用途:X軸、バケット化:なし)
上記の設定を行うと、左側に人口推移を表した折れ線グラフが表示されます。
作成したチャートは、ワークシートを開きなおしてもそのまま表示されます。ただし、新しいSQLを実行した場合は結果とチャートが上書きされてしまい表示できなくなるのでご注意ください。
ダッシュボード作成
可視化まで完了したので、作成したワークシートをもとにダッシュボードを作成してみます。
ワークシート名にカーソルを合わせてメニューを開き、「移動」→「新しいダッシュボード」をクリックします。
ポップアップが開くため、ダッシュボード名を入力し「ダッシュボードを作成」をクリックします。
以上でダッシュボードの作成は完了です! 右上の「実行」を押すと最新のデータに基づいてグラフが更新されます。
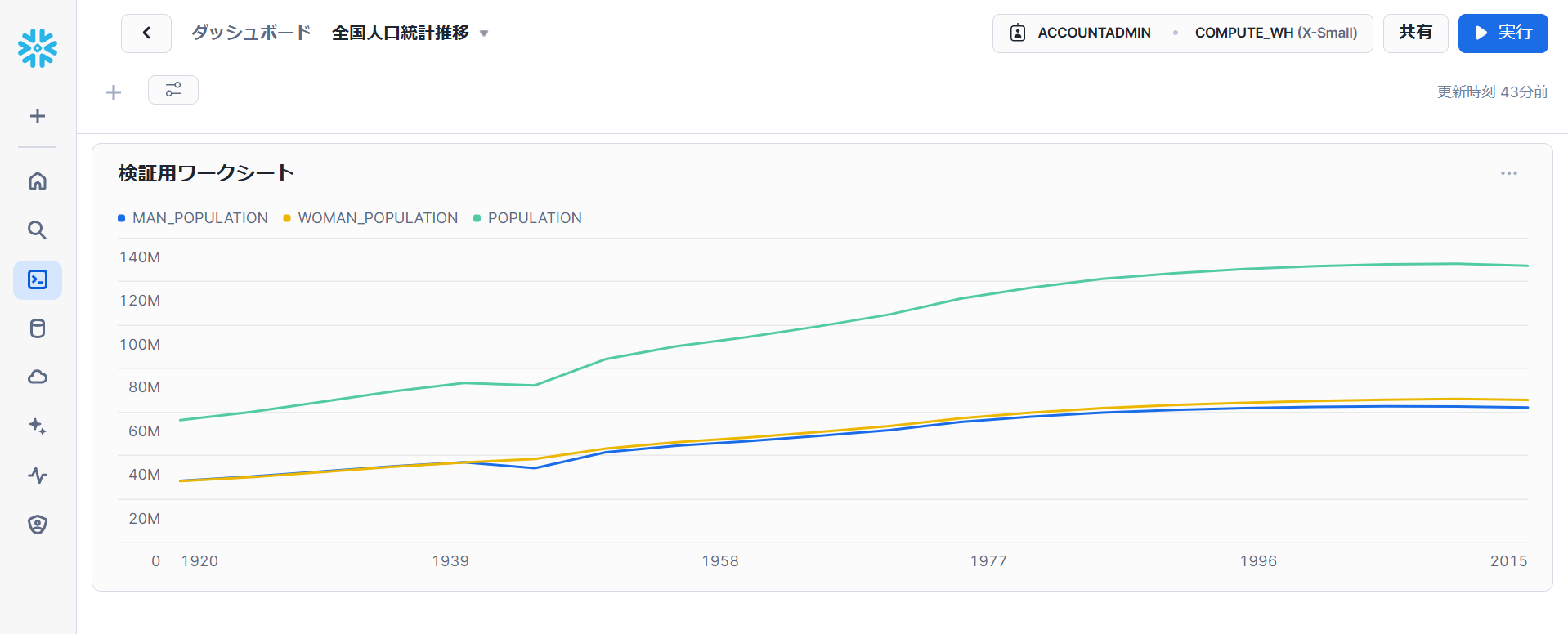
※ワークシートを使用してダッシュボードを作成した場合、もとのワークシートは一覧から削除されて利用できなくなるため注意が必要です。グラフのメニューから「クエリを編集」でクエリにアクセスすること自体は可能です。
さいごに
Snowflake の基本操作についてご紹介しました。
今回はローカルファイルを直接アップロードして取り込む方法をご紹介しましたが、AWS/GCP/Azure上のファイルを取り込んだり、ストリーミングデータを取り込んだりすることも可能です。また、ワークシートもSQLだけではなく、Pythonを利用してプログラムと組み合わせた高度な処理を行うこともできます。本記事でご紹介した以外にも様々な機能があるので、ぜひご自身でもいろいろと触って試してみてください。
参考
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

