Generative AI Use Cases (GenU) でRAG機能を使ってみる
2025.12.03
- AWS
- クラウド
- 生成AI
GenUでは、RAG機能を有効化することで社内ナレッジ等のドキュメントに基づいてチャットを行うRAGチャットを利用することができます。本記事では、Bedrock Knowledge Bases を利用したRAG機能の利用方法についてご紹介します。
準備
GenUの導入手順でブートストラップまで実行した後、以下の手順でRAGの設定を行います。
設定ファイル編集
packages/cdk/cdk.json を開き、ragKnowledgeBaseEnabledをtrueに変更して保存します。
{
"context": {
"ragKnowledgeBaseEnabled": true
}
}
※既存リソースを指定しなかった場合、ナレッジベースが新規作成されます。
デプロイ
以下のコマンドでデプロイします。
# 通常デプロイ
npm run cdk:deploy
# 高速デプロイ (作成されるリソースを事前確認せずに素早くデプロイ)
npm run cdk:deploy:quick
デプロイが完了すると、Outputs最下部にGenUログイン用のURLが表示されます。
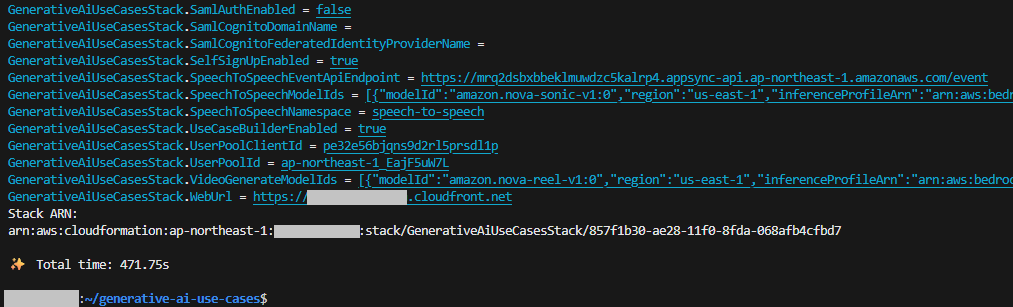
URLにアクセスすると、ログイン画面が表示されます。

アカウントを作成してサインインすると、アプリのホーム画面が表示されます。
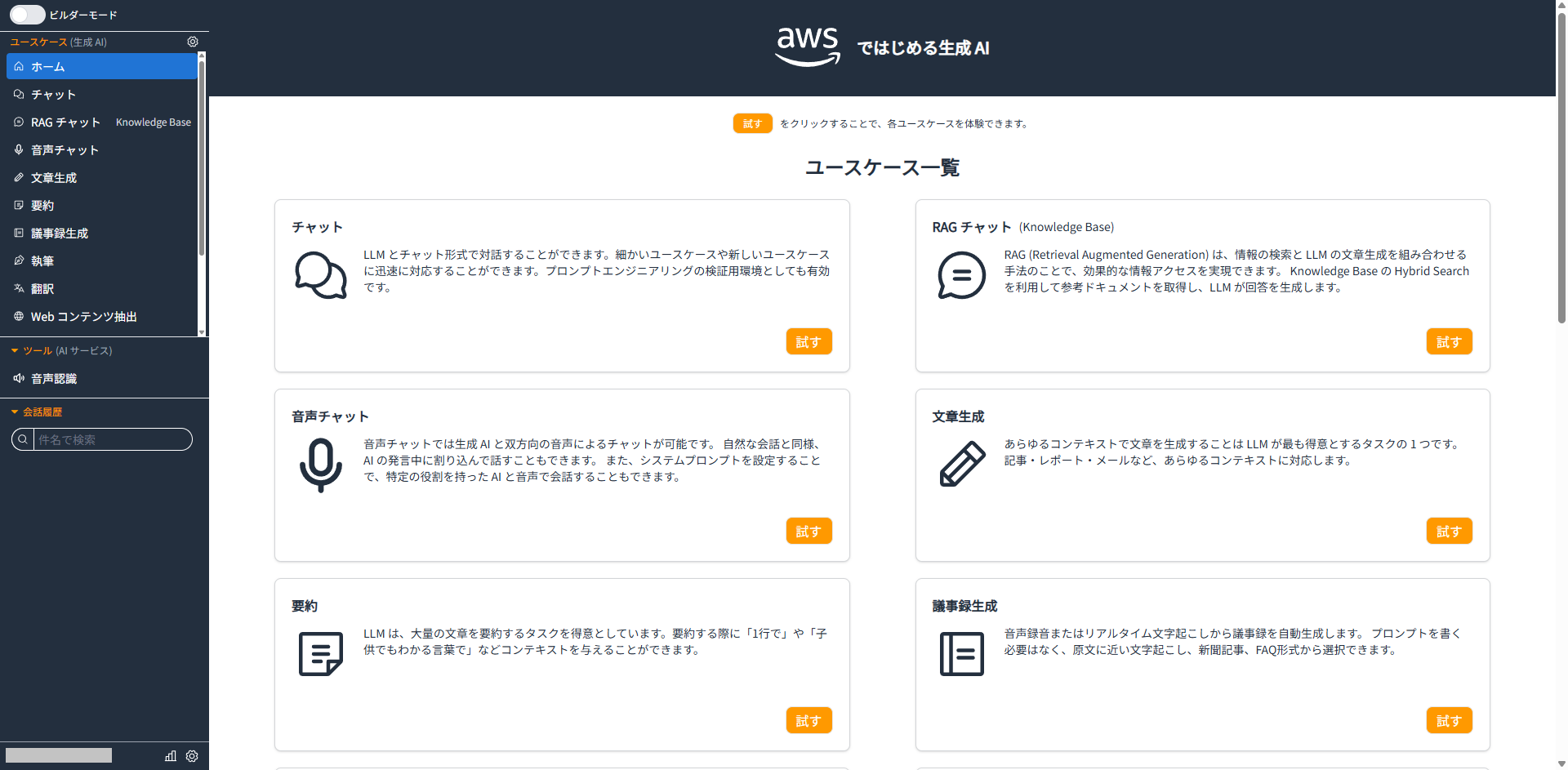
RAGデータ同期
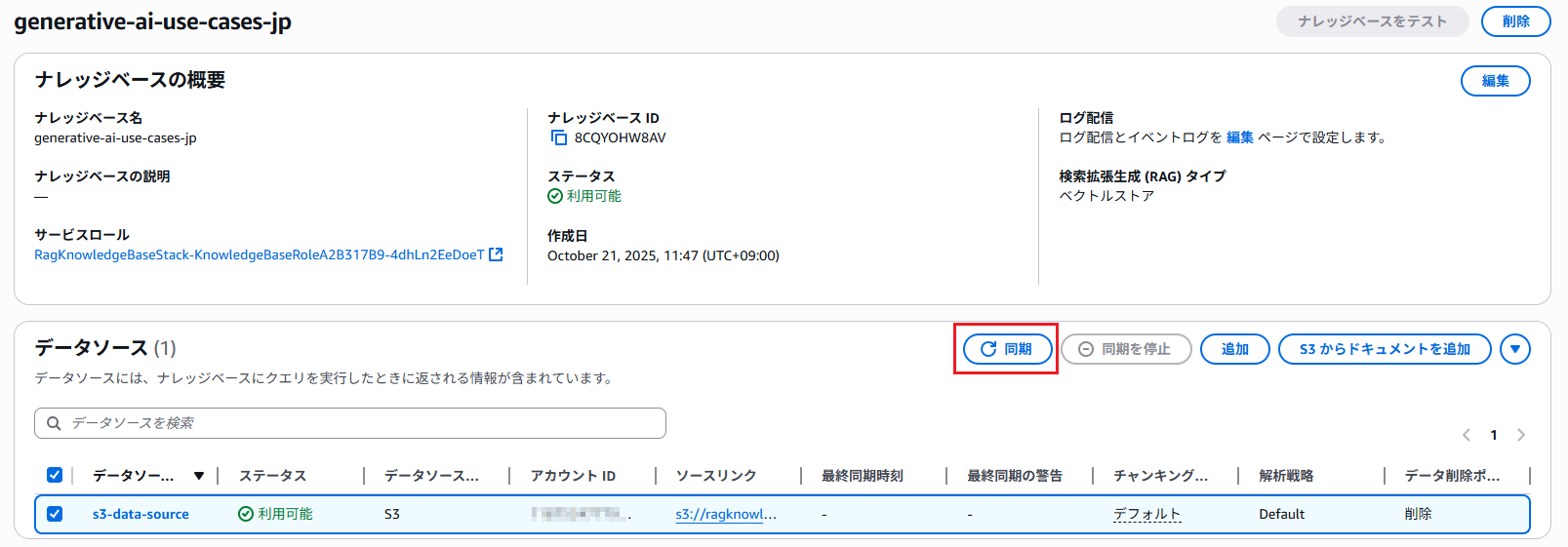
Amazon Bedrock のコンソールで「ナレッジベース」→「generative-ai-use-cases-jp」を開きます。
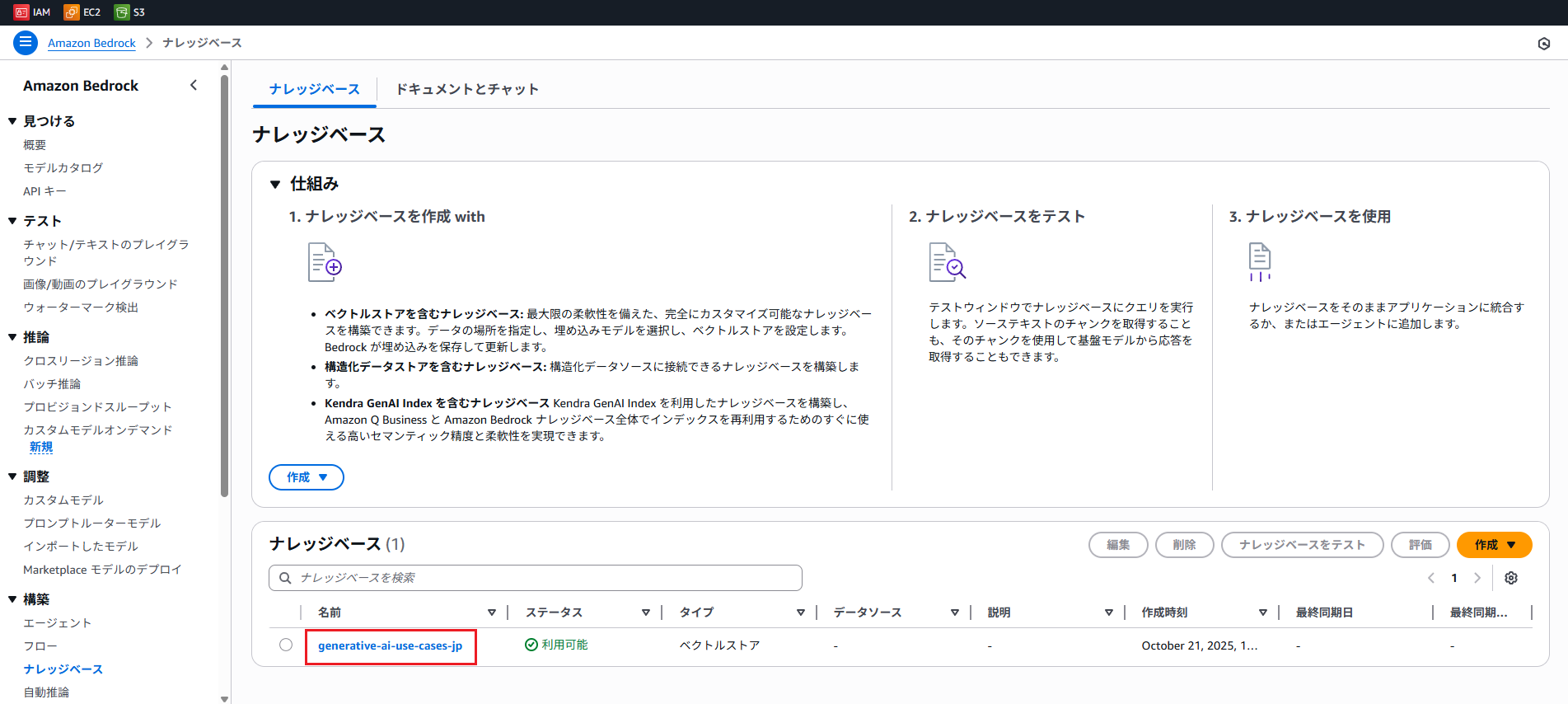
データソース一覧の「s3-data-source」のソースリンクを開きます。
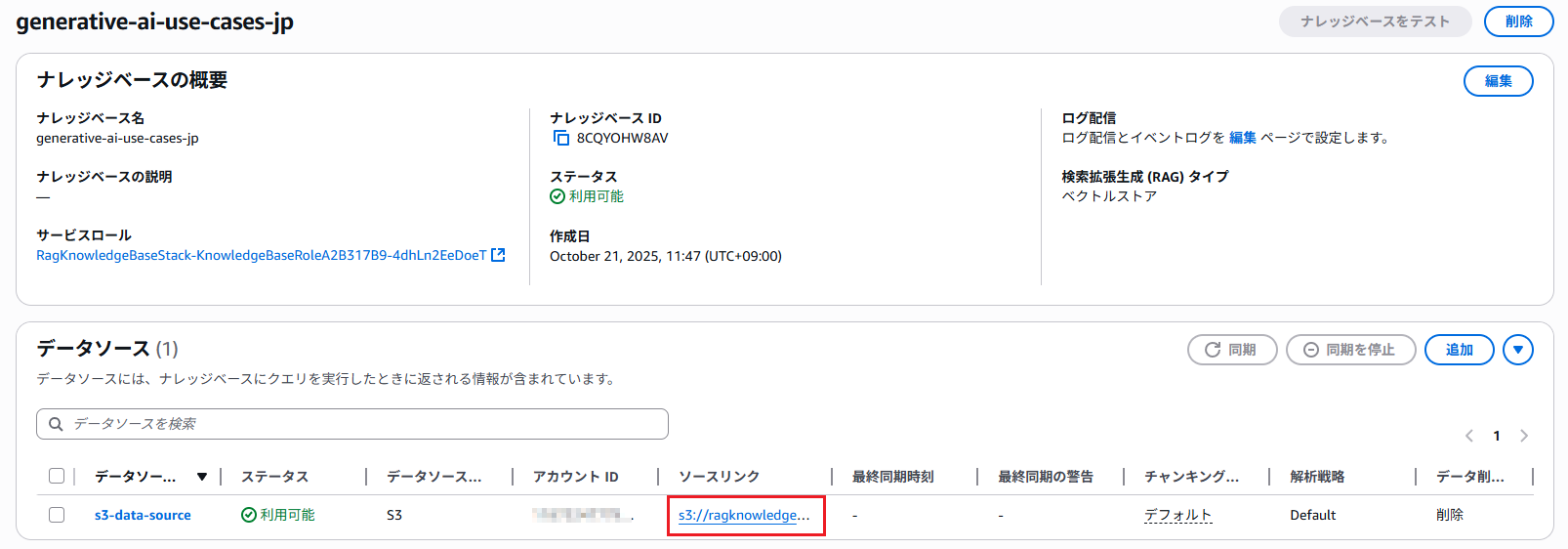
S3バケットが開くため、RAGに使用したいドキュメントをアップロードします。今回は試しにRe:Qのデータエンジニアリングサービスの事業紹介資料をアップロードします。(他はデフォルトで用意されているBedrockとNovaの紹介資料)
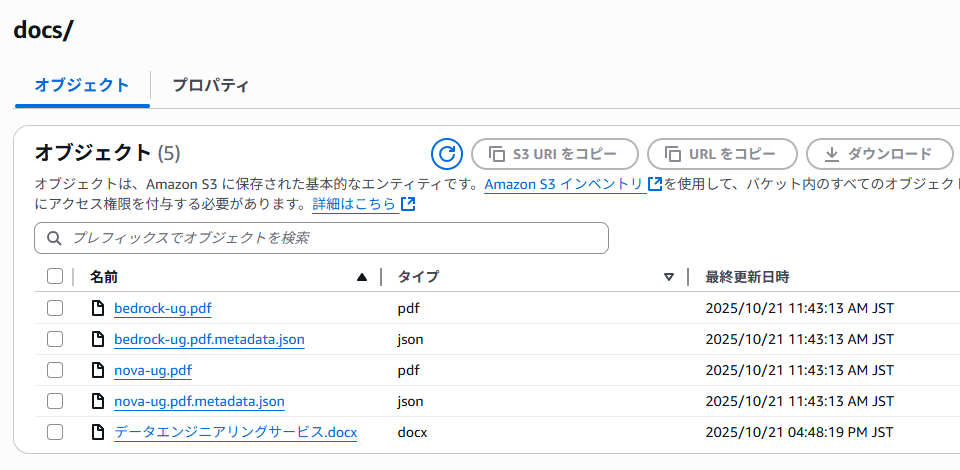

ドキュメントのアップロード後、「s3-data-source」を選択した状態で「同期」をクリックします。
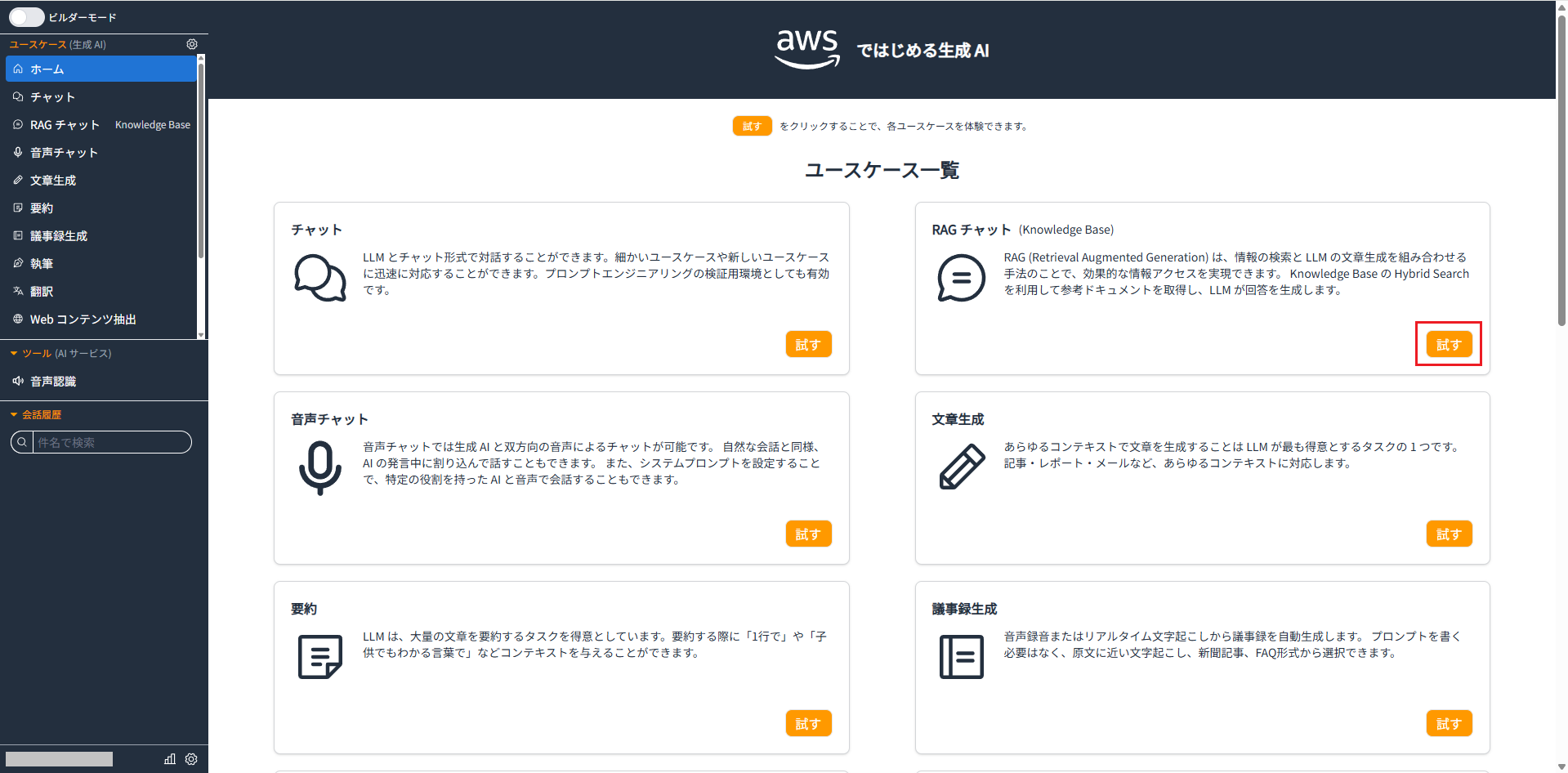
同期後、ユースケース一覧のRAGチャットを開きます。
RAGチャットで、同期したドキュメントに関する質問をしてみます。
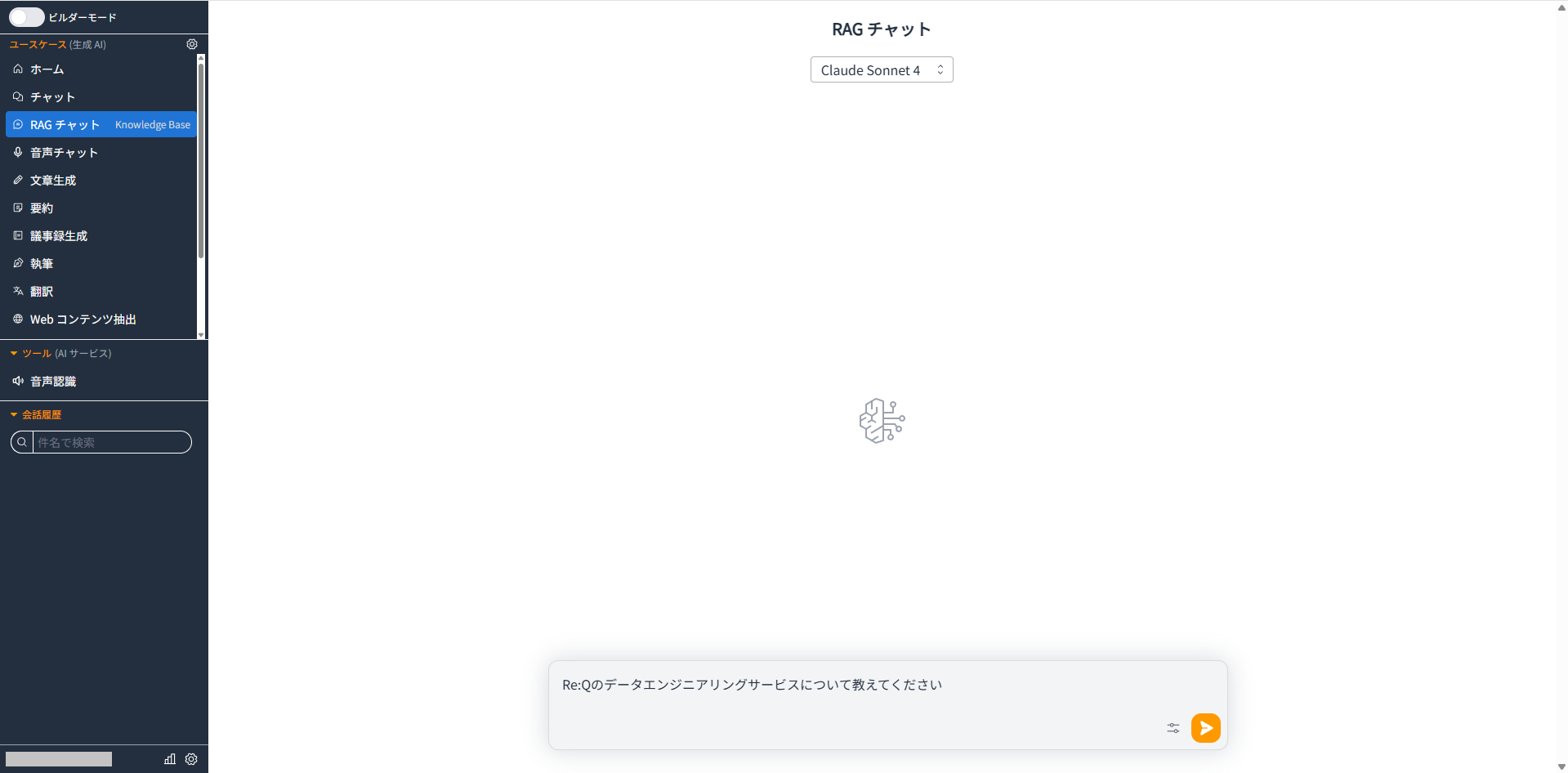
ドキュメントに記載された情報をもとに回答が返されました。

リンクをクリックすると、回答時に参照したドキュメントを確認できます。
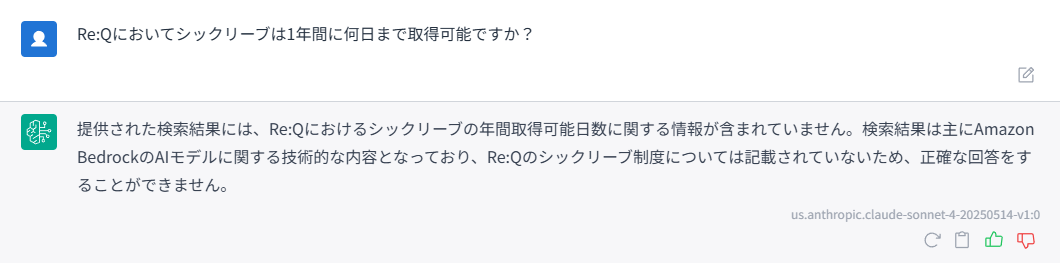
ドキュメントにない情報について質問した場合、検索結果に十分な情報がない旨を回答できていればOKです。
さいごに
GenUでRAG機能を利用する方法についてご紹介しました。
事前にナレッジベースの設定等しなくても、設定ファイルでオプションを有効化してデプロイするだけで良いので非常に楽ですね。GenUでRAGをしてみたいという方はぜひ試してみてください。
参考
RELATED ARTICLE関連記事
2025.12.10
Generative AI Use Cases (GenU) のセキュリティ機能検証
- AWS
- クラウド
- 生成AI
2025.12.08
Generative AI Use Cases (GenU) x Microsoft Entra IDでSSO構築
- AWS
- クラウド
- 生成AI
2025.12.05
Generative AI Use Cases (GenU) x MCPでチャットを強化
- AWS
- クラウド
- 生成AI
2025.12.04
Bedrock AgentCore RuntimeでAIエージェントを簡単デプロイ
- AWS
- Python
- クラウド
- 生成AI
2025.12.01
Generative AI Use Cases (GenU) 解説:導入からアップデート方法まで
- AWS
- クラウド
- 生成AI
RELATED SERVICES関連サービス

Careersキャリア採用


この記事をシェアする

