Amazon SageMakerでIcebergテーブル書き込みパイプラインを作成してみる
2025.10.08
- AWS
- クラウド
- データエンジニアリング
Amazon SageMaker には、Visual ETL flows というGUIのETLパイプライン構築ツールがあります。
今回は Visual ETL flows を利用し、CSVファイルからIcebergテーブルへの書き込みを行うETLパイプラインを作成してみます。
手順
バケット作成
S3バケットを作成し、以下のようにフォルダを用意します。
bucket/
├ files/
└ iceberg_database/
└ employees/
※files/はファイルアップロード用、iceberg_database/はIcebergテーブルのデータ格納用
ファイルアップロード
ファイルアップロード用フォルダ(files/)にCSVファイルをアップロードします。
CSVファイルのデータは以下の通りです。
1001,John,Doe,john.doe@example.com,Engineering,75000
1002,Jane,Smith,jane.smith@example.com,Marketing,65000
1003,Emily,Jones,emily.jones@example.com,Sales,70000
1004,Michael,Brown,michael.brown@example.com,HR,60000
1005,Jessica,Johnson,jessica.johnson@example.com,Finance,80000
テーブル作成
クエリエディタで以下のSQLを実行し、Icebergテーブルを作成します。
CREATE TABLE employees (
employee_id int,
first_name string,
last_name string,
email string,
department string,
salary int
)
LOCATION 's3://req-iceberg-demo-bucket/iceberg_database/employees/'
TBLPROPERTIES ('table_type' = 'ICEBERG');
ETLフロー作成
「Build」→「Visual ETL flows」を開き、フローの新規作成をクリックします。
編集画面で、「Add nodes」をクリックし、「Data sources」で「Amazon S3」を選択します。
S3のノードをクリックし、以下のように設定します。
- S3 URI:ファイルを格納したフォルダのURI
- Format:CSV
- Multiline:Enabled
- Header:Disabled
- Infer Schema:Enabled
- Recursive file lookup:Disabled
設定したら、「Update node」をクリックします。
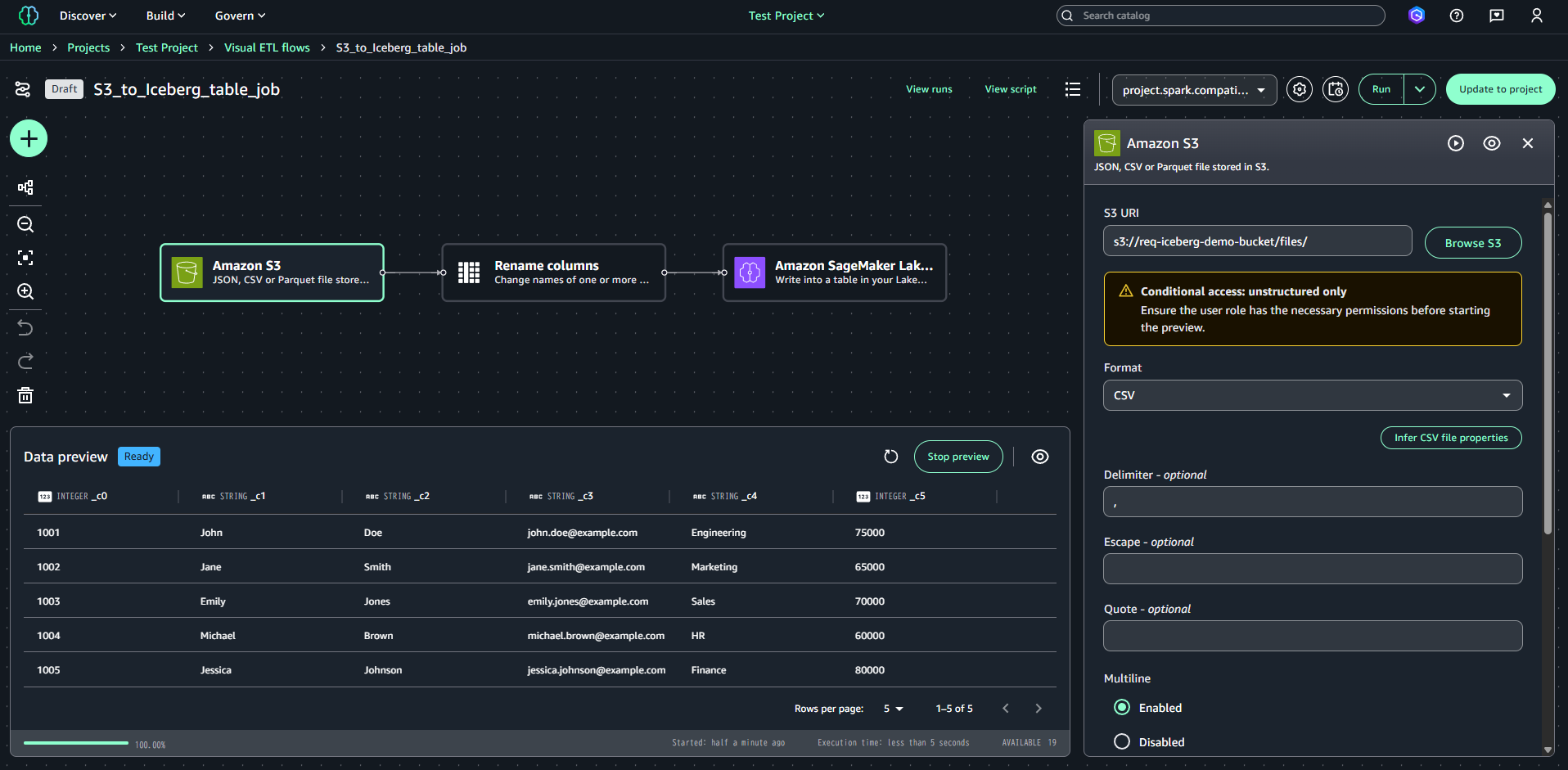
下部にプレビューが表示されており、対象ノードの出力を確認することができます。
現在の状態ではカラム名が正しく設定できていないため、「Add nodes」→「Transforms」→「Rename Columns」を選択し、列の変換設定を追加します。
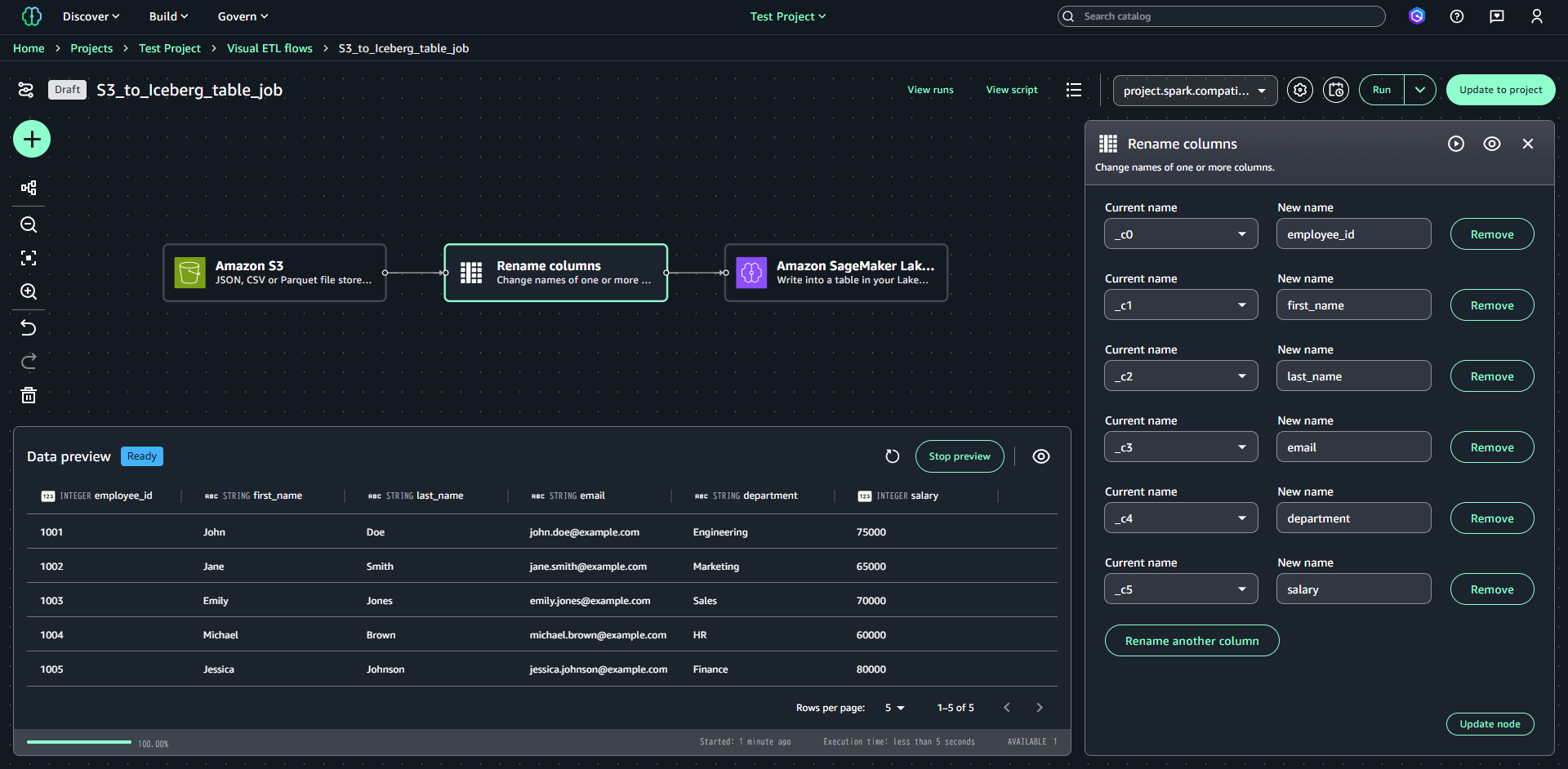
列の変換設定は以下の通りです。
- c0:employeeid
- c1:firstname
- c2:lastname
- _c3:email
- _c4:department
- _c5:salary
「Add nodes」→「Data targets」→「Amazon SageMaker Lakehouse」をクリックし、テーブルへの書き込み設定を行います。
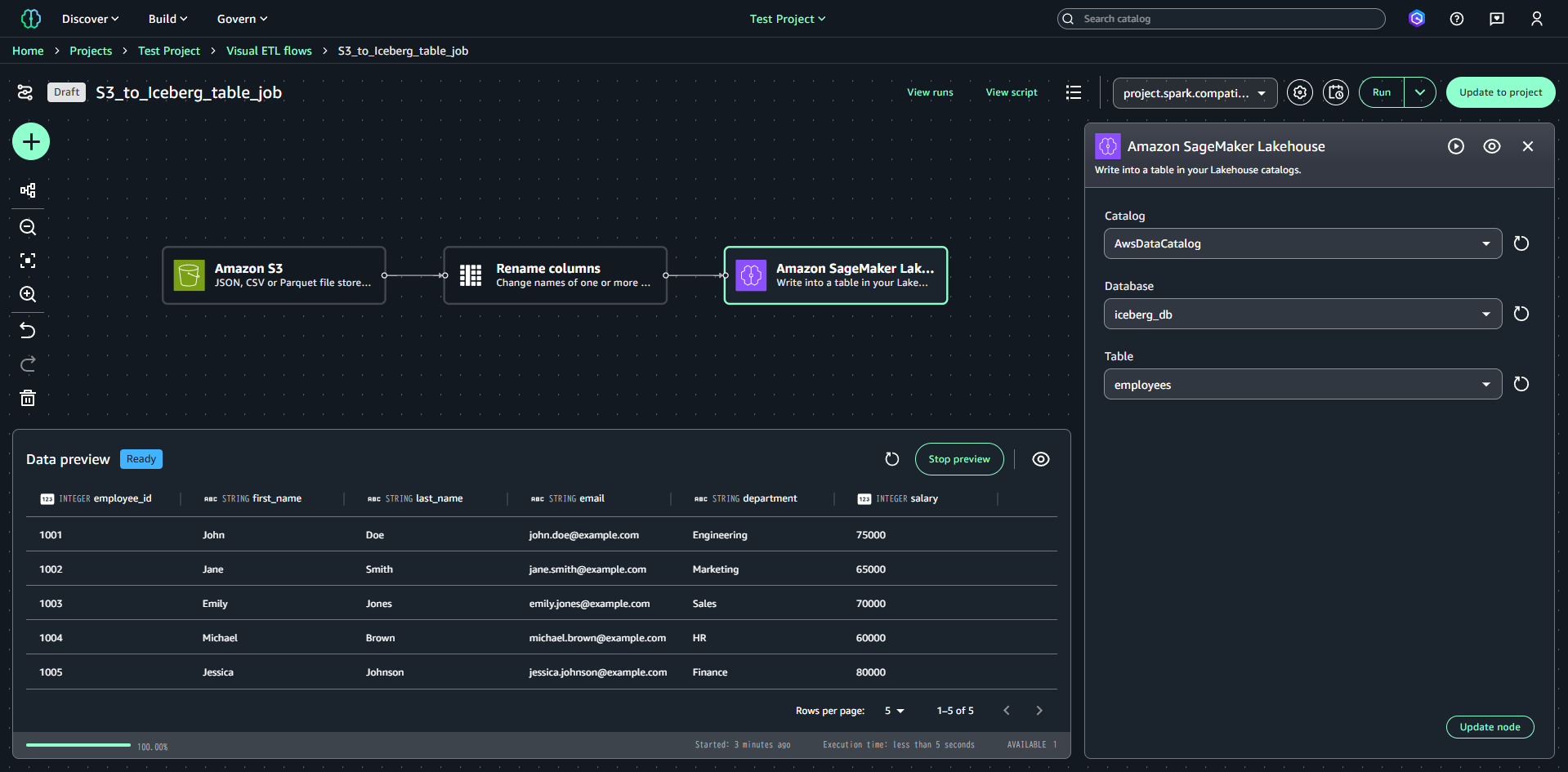
設定は以下の通りです。
- Catalog:対象のカタログ(AwsDataCatalog)
- Database:対象のデータベース(iceberg_db)
- Table:対象のテーブル(employees)
※S3 Tablesの場合も同様
ETLフロー実行
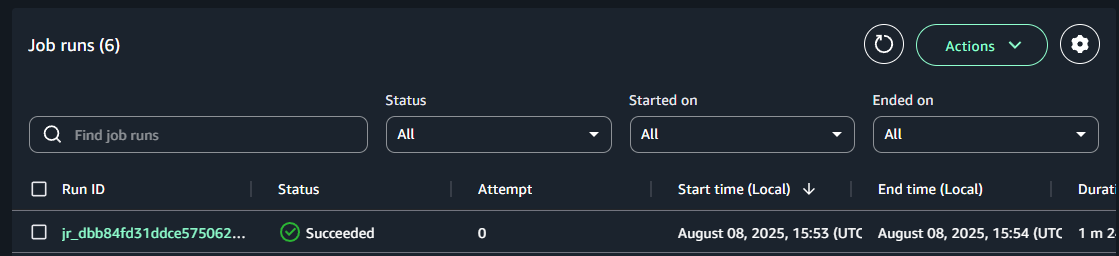
画面右上の「Run」をクリックし、ジョブを実行します。
ジョブの実行状態は「View runs」から確認可能です。ジョブが正常終了すると、Statusが「Succeeded」と表示されます。
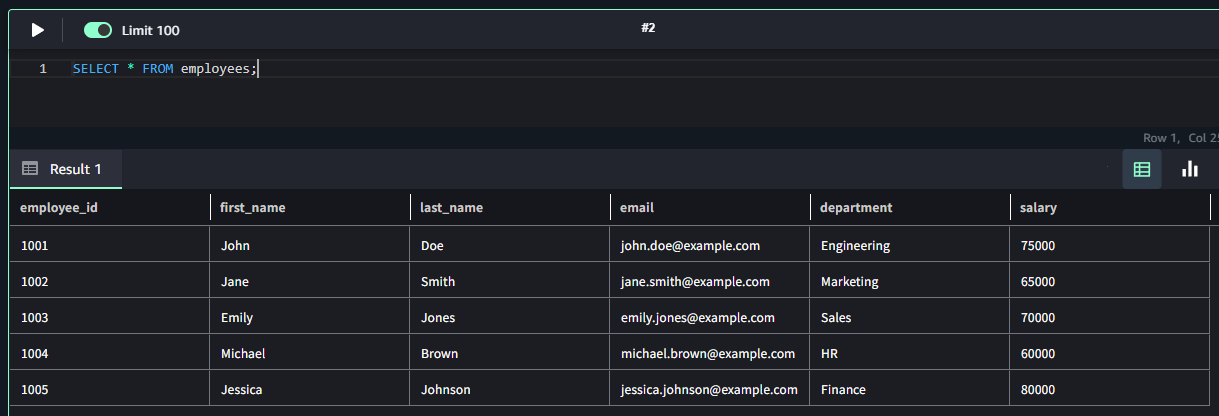
クエリエディタで確認すると、データが取り込まれていることが確認できます。
注意点
Icebergテーブル書き込みにあたり、以下の注意点があります。
- 対象フォルダにファイルが複数ある場合、すべてのファイルが取り込みの対象になる
- データ取り込みは追記方式(ジョブを動かすたびにファイルの全データが追加される)
データ取り込み方式を選択できず、Icebergテーブルの仕様上主キー制約も設定できません(Icebergテーブルには主キー制約が存在しない)。そのため、重複を排除しながらデータを取り込みたい場合、以下のようなアプローチでユーザ側で重複排除処理を実装する必要があります。
- 冪等なID設計による一意性の担保
- 追記+重複削除(重複を許容したうえで、クエリで一意な行を抽出)
まとめ
SageMaker におけるIcebergテーブル書き込みパイプラインの作成方法についてご紹介しました。
Visual ETL flows はこちらの記事で解説しているように様々なデータソースや変換機能を利用でき、Icebergテーブル書き込みパイプラインを柔軟に構築することができます。一方で、書き込みが追記のみに限定されており、重複排除処理はユーザ側で実装しなければならないという注意点もあります。ユースケースに合わせて、適切にパイプラインを構築することが重要です。
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

