Visual ETL flowsでETL処理を試してみる
2025.07.14
- AWS
- クラウド
- データエンジニアリング
Amazon SageMaker の Visual ETL flows は、ブラウザ上でドラッグ&ドロップだけで高度なデータ変換やパイプライン構築を行うことができる機能です。直感的なユーザーインターフェースを通して、文字列からタイムスタンプへの変換や列の追加、テーブルへの書き込みなどを簡単に設定することができます。
利用手順
Amazon SageMaker の「Build」→「Visual ETL flows」を開きます。
開いた画面で、「Create visual ETL flow」をクリックします。
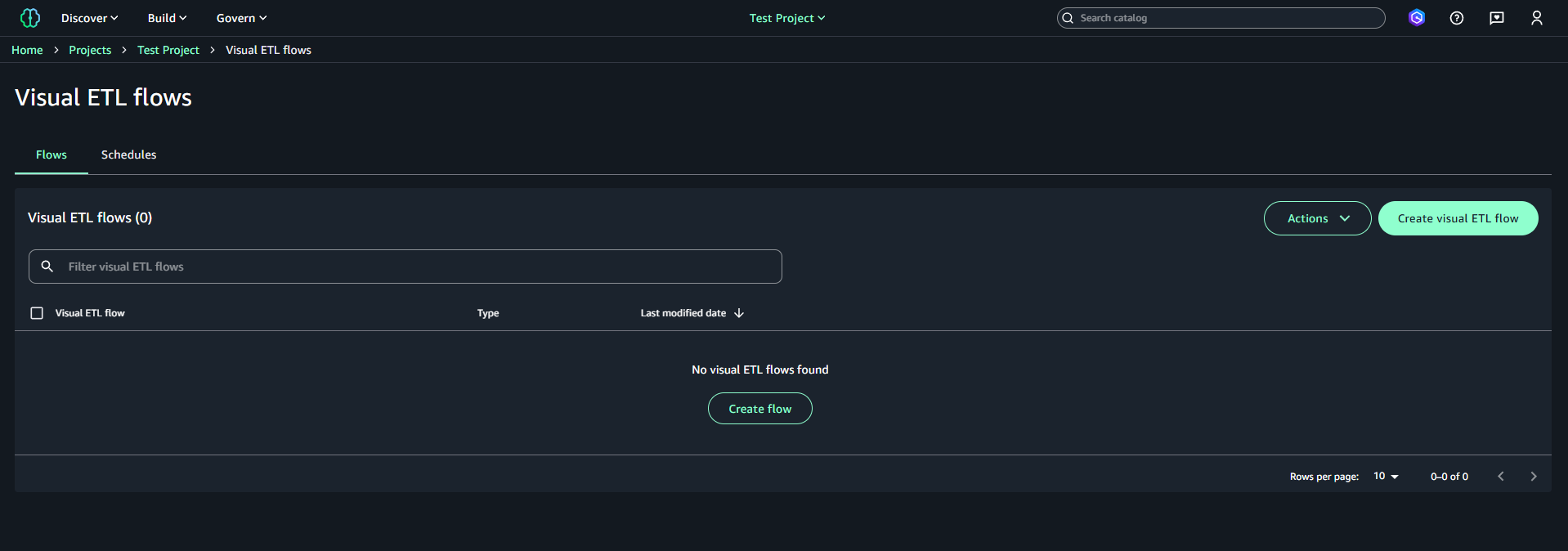
データアクセスについての選択画面が表示されます。今回はデータを直接扱いたいため、「Data managed using full-table access (compatibility)」を選択して「Continue」をクリックします。
説明には適当な内容を記載して「Submit」をクリックします。
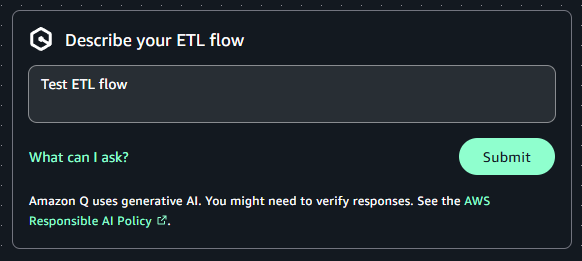
編集画面に移ります。編集画面には、サンプルのETLフローが表示されています。
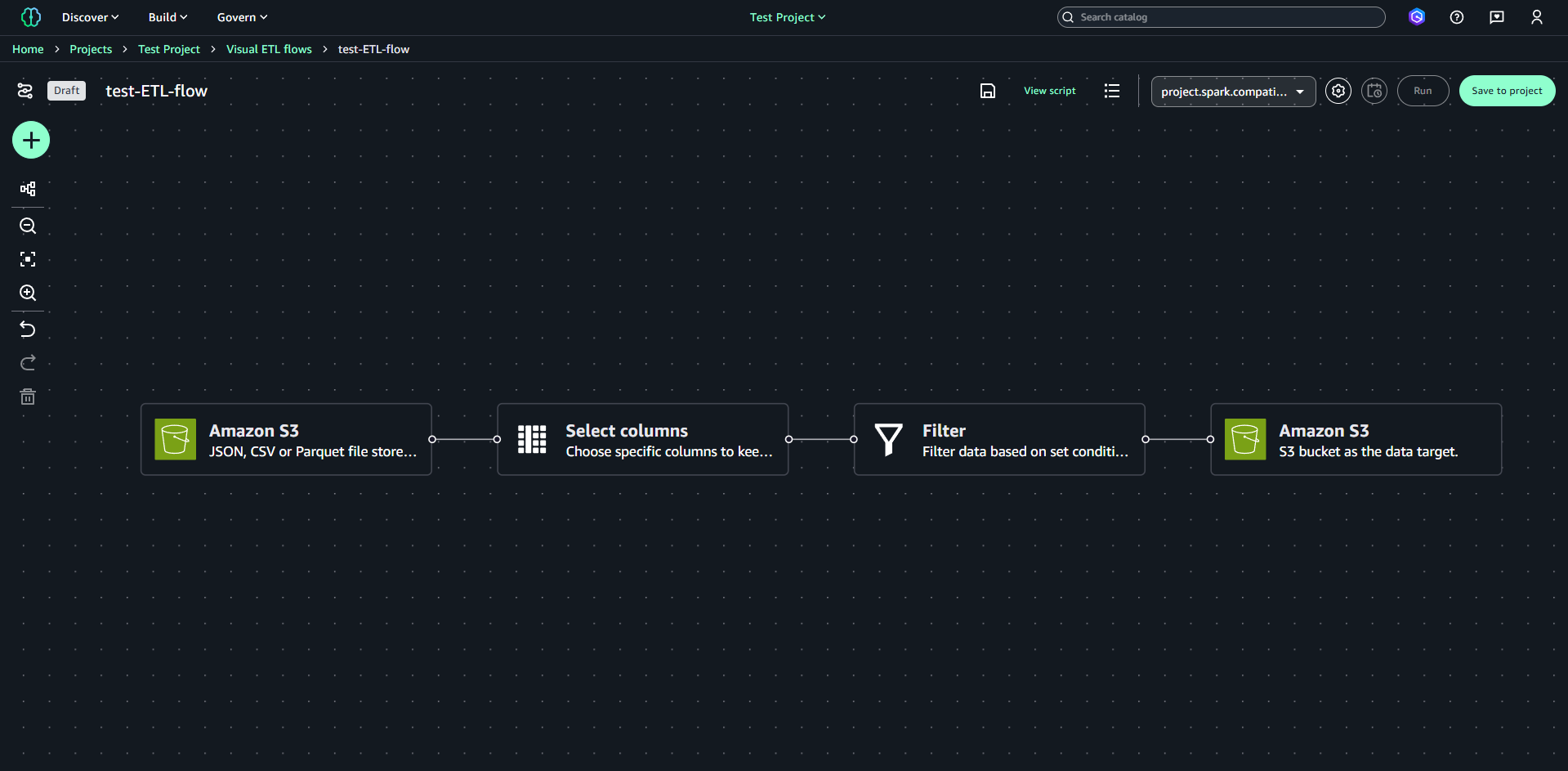
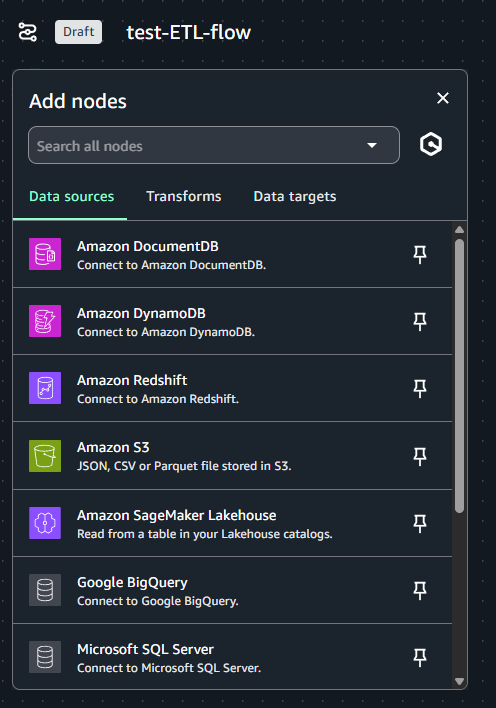
ノードの追加は、左側の「+」をクリックして表示される「Add nodes」から追加可能です。
SageMaker Lakehouse 内のデータに加え、DynamoDB や BigQuery、Oracle、Snowflake などサポートされている各種データソースを利用することができます。データターゲットについても同様です。
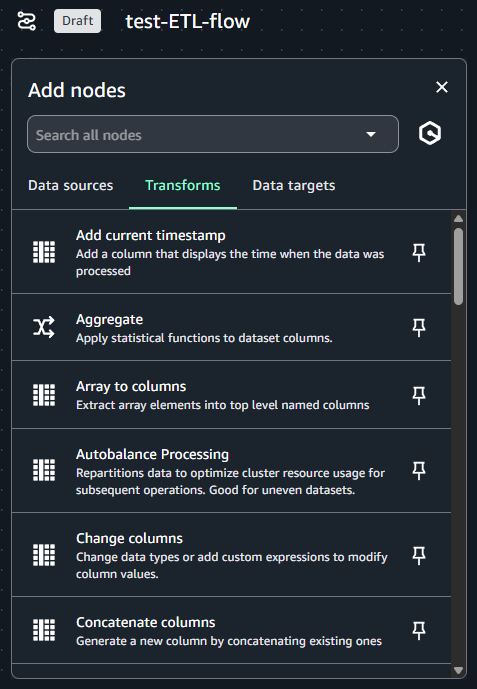
Transforms にはタイムスタンプの追加、集約、配列のフラット化、データ型変換など様々な変換機能が用意されています。
今回、例として Lakehouse のテーブルデータを BigQuery に挿入するETLフローを作成します。使用するテーブルデータはこちらをもとに作成したものです。
はじめに、GCP側で BigQuery のテーブルを作成しておきます。
-- population テーブル作成
CREATE OR REPLACE TABLE tani_test.population (
`都道府県コード` STRING,
`都道府県名` STRING,
`元号` STRING,
`和暦_年` STRING,
`西暦_年` STRING,
`注` STRING,
`人口_総数` INTEGER,
`人口_男` INTEGER,
`人口_女` INTEGER
);
最初のノードは「Amazon SageMaker Lakehouse」を配置し、Lakehouse のテーブルを指定します。
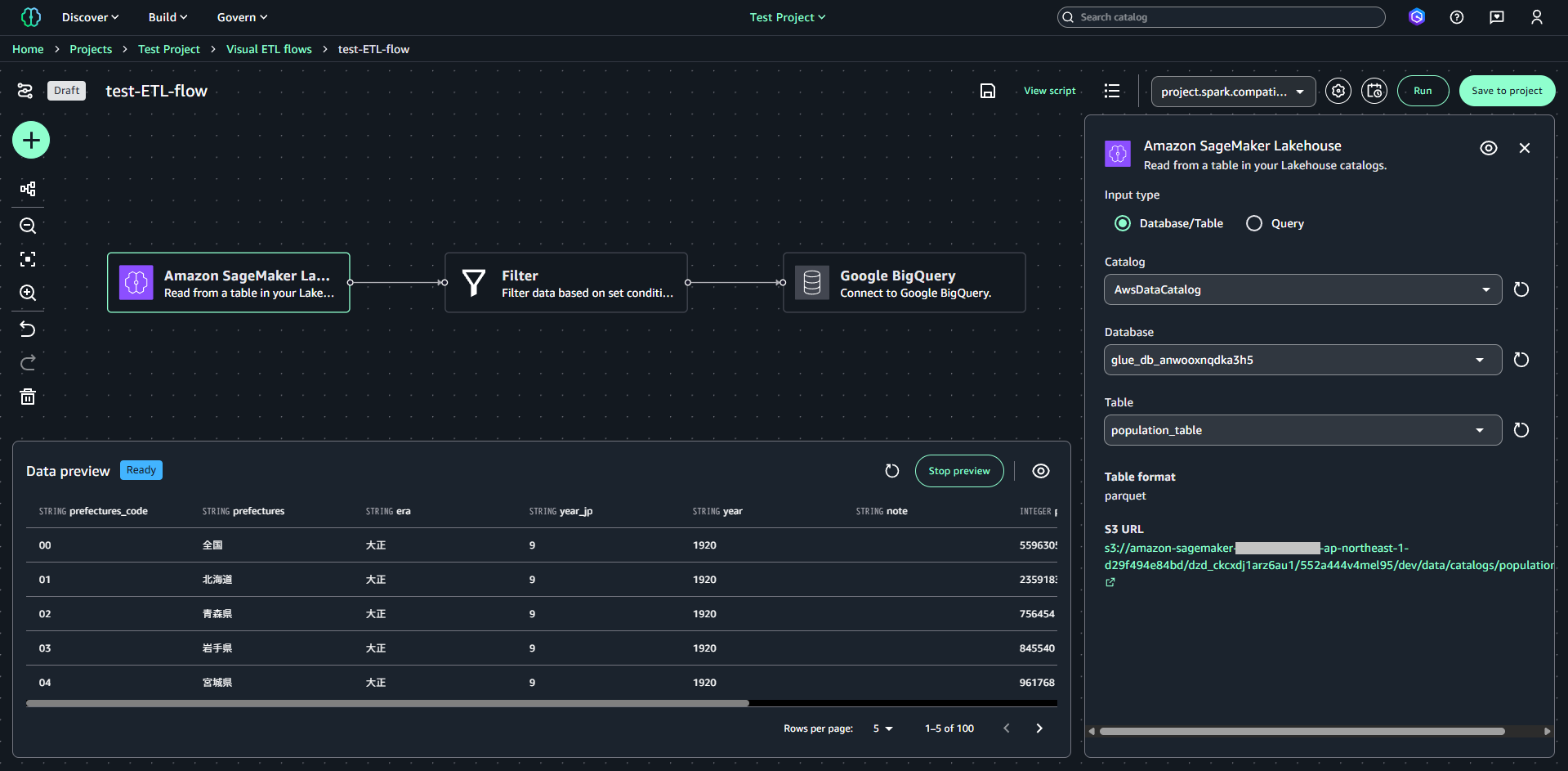
2つ目のノードは「Filter」を配置します。今回使用する人口統計データのテーブルには都道府県名がnullの不要なデータが含まれているため、prefectures != nullという条件を指定します。
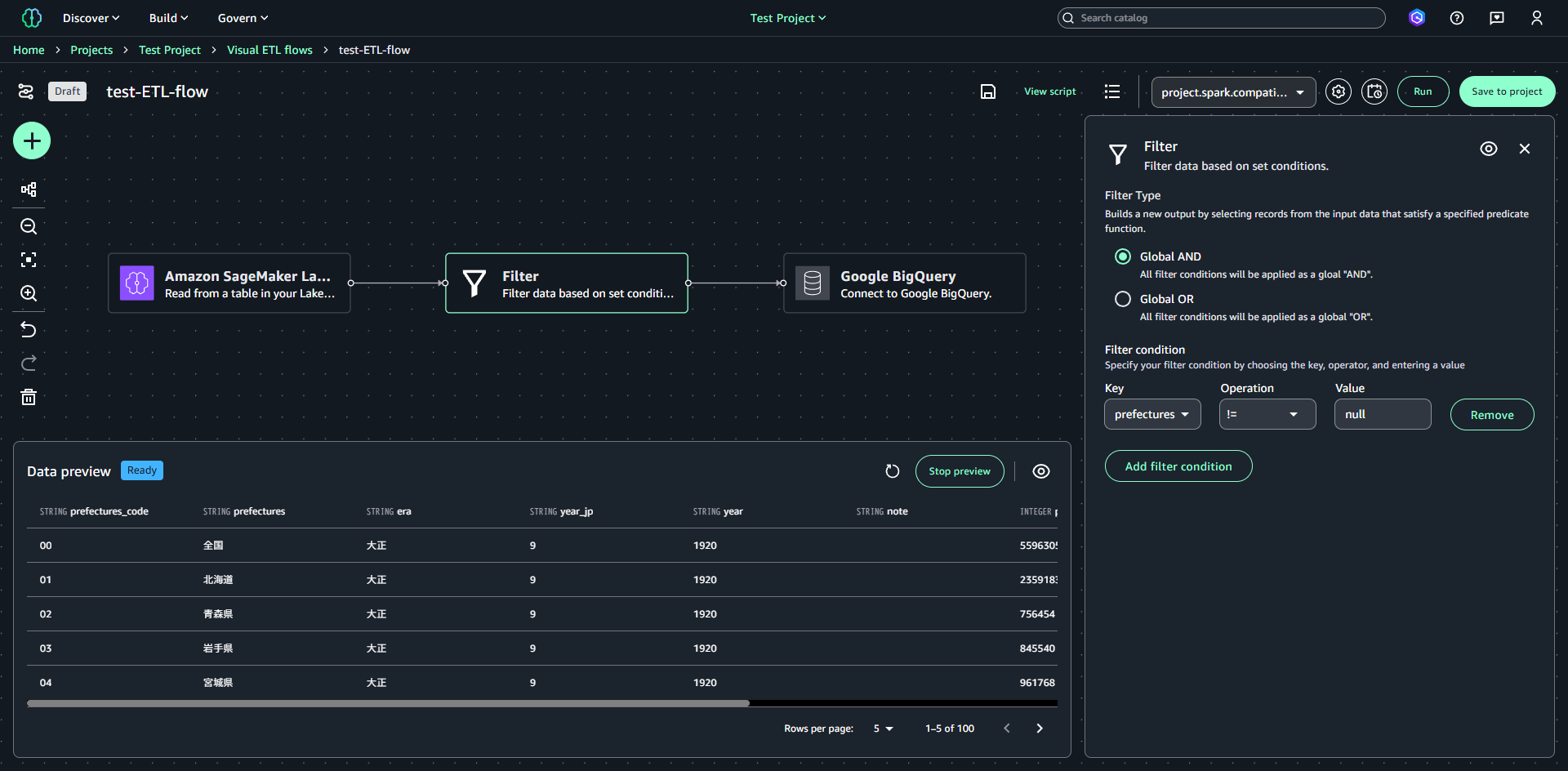
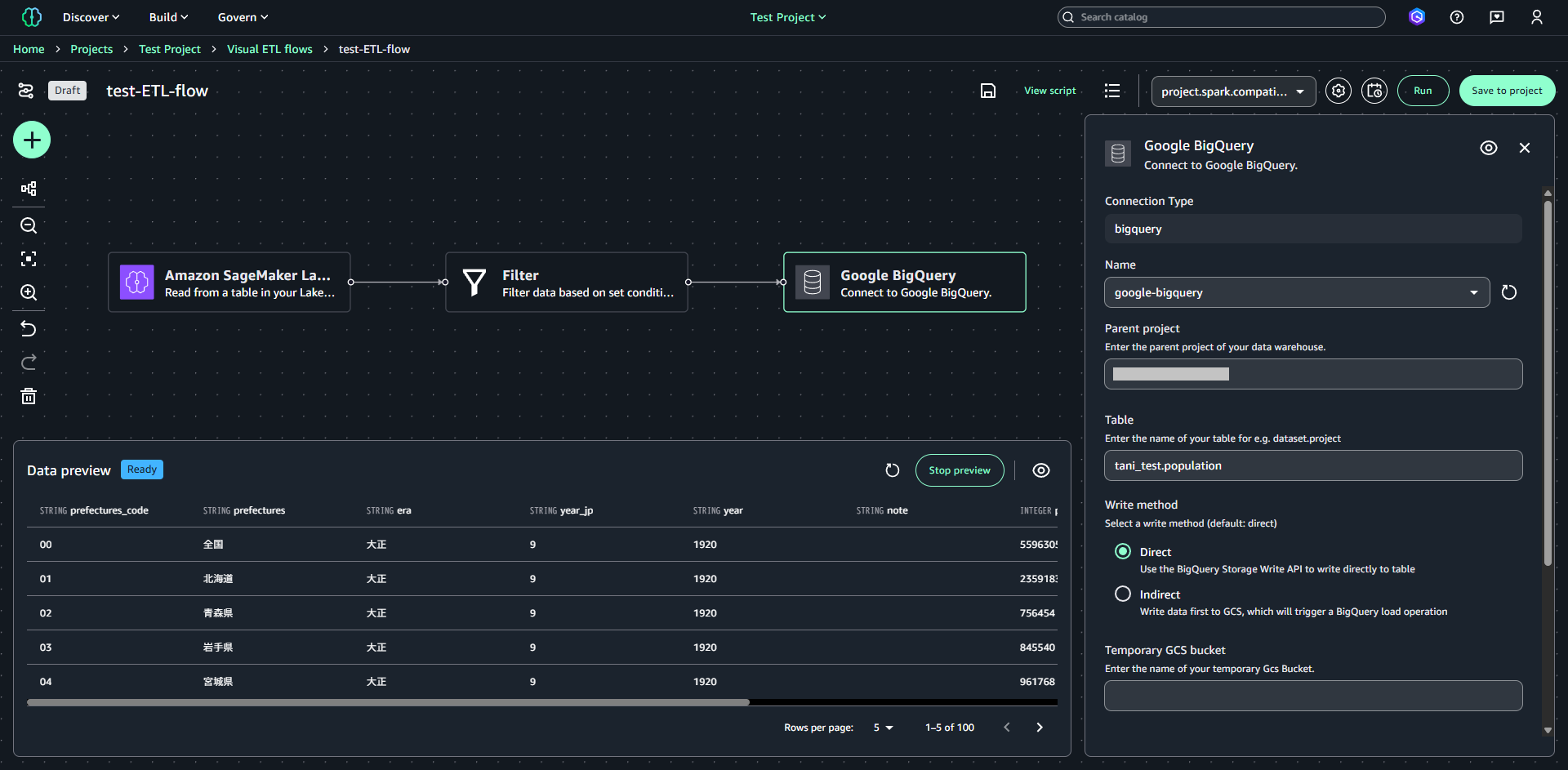
3つ目のノードは「Google BigQuery」を指定します。Nameの部分で作成済みのBigQueryカタログを指定し、データ取り込み先のテーブルと書き込み方式、モードを設定します。
※今回の検証では書き込み方式は Direct、モードは Overwrite(上書き)を指定しています。
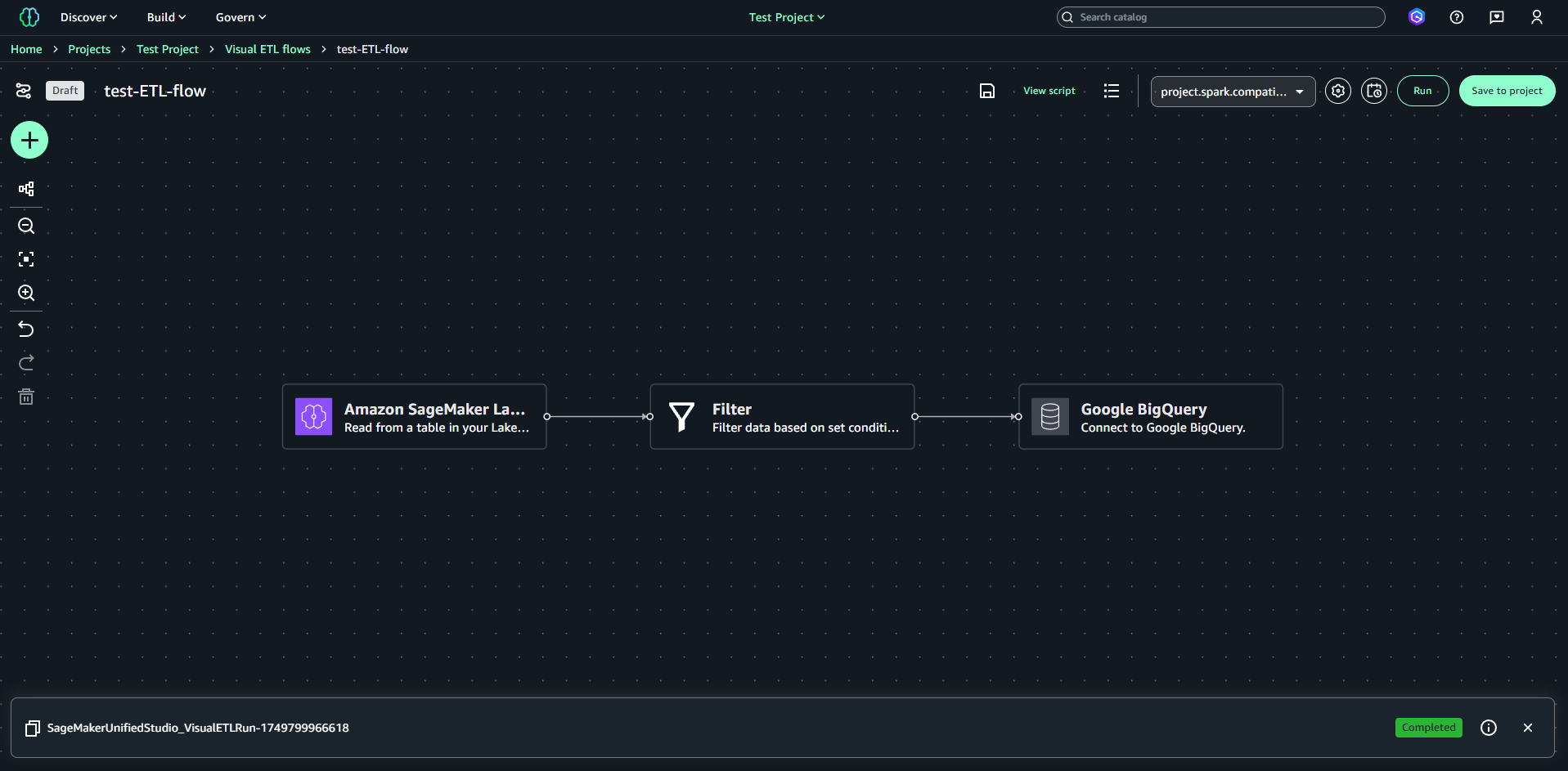
上記設定で右上の「Run」をクリックするとETLフローの実行が始まります。実行が完了すると、画面下部のステータスが「Completed」となります。
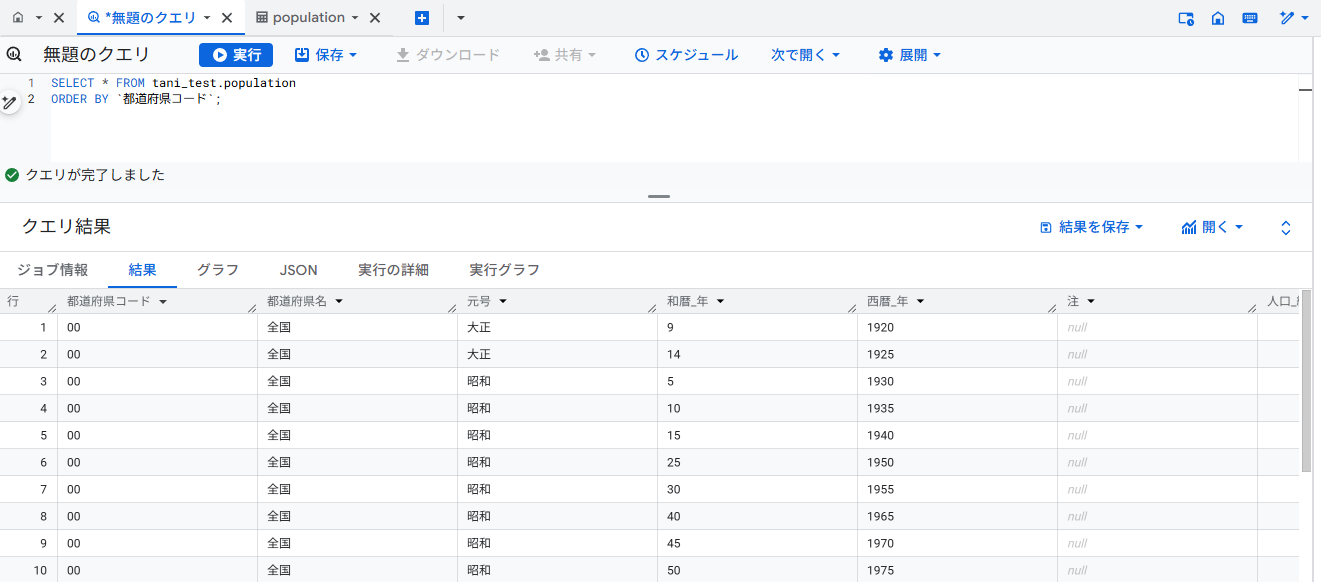
実行後に BigQuery のテーブルを確認すると、データが期待通りの形で挿入されていることが確認できます。
補足
- S3を利用する場合、
datazone_usr_role_xxxxxxxxxxxxxx_xxxxxxxxxxxxxxに対象バケットへのアクセスに必要な権限を付与しておく必要があります。 - ETLフロー編集画面上部の「設定」で実行環境の細かい設定(ワーカータイプ、ワーカー数、タイムアウト時間、セッションパラメータ等)が可能です。
- ETLフロー編集画面上部の「スケジュール」で実行スケジュールを設定可能です。
さいごに
Visual ETL flows の基本的な使い方についてご紹介しました。
Visual ETL flows は名前の通り、ETLフローを視覚的に構築し、直感的なUIで簡単に設定できる便利な機能です。データコネクタも複数用意されており、AWS内外のデータソースと連携できます。機械学習の前処理でETLフローをささっと構築したい場合など、ぜひ活用してみてください。
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

