Vertex AI RAG Engine を使ってみる:導入からプログラム実装と注意点
2025.06.05
- GCP
- クラウド
- データエンジニアリング
- 生成AI
Vertex AI RAG Engine は、Google Cloud 上でRAG機能を提供するフルマネージドサービスです。AWS の Amazon Bedrock Knowledge Bases と同様のサービスであり、LLMに情報を与えて回答を強化するRAGの仕組みそのものを提供します。アプリケーション画面やユーザ管理の仕組みはユーザ側で用意する必要があります。
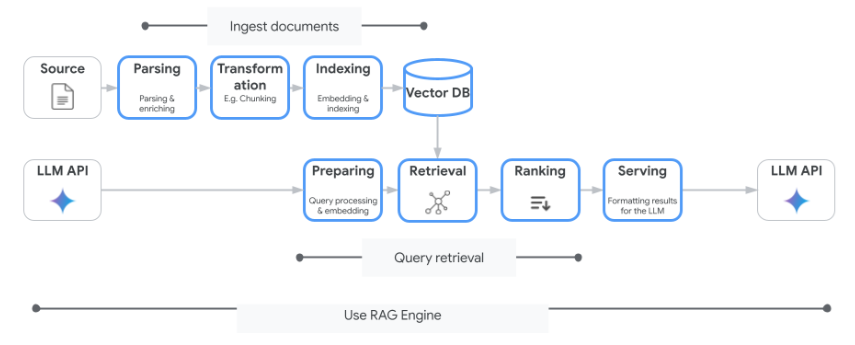
RAGコーパスと呼ばれるナレッジベースにインデックス化されたデータが格納され、それに対して問い合わせを行った結果をもとにLLMが回答を生成するという仕組みです。
以降で早速、Vertex AI RAG Engine の導入からプログラム実装までの具体的な手順について見ていきましょう。
導入
事前準備
最初に、以下のAPIを有効化しておきます。
- Vertex AI API
- Cloud Storage API
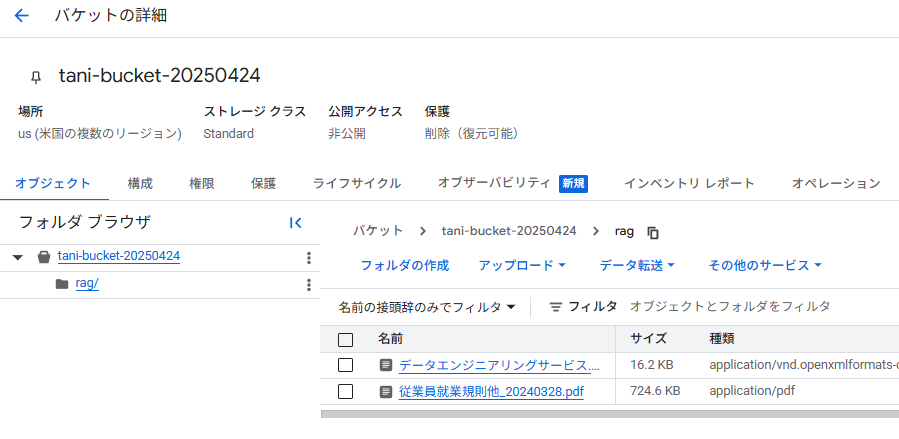
Cloud Storage からデータを取り込む場合
Cloud Storage にバケットを作成し、ファイルを入れておきます。
Google Drive からデータを取り込む場合
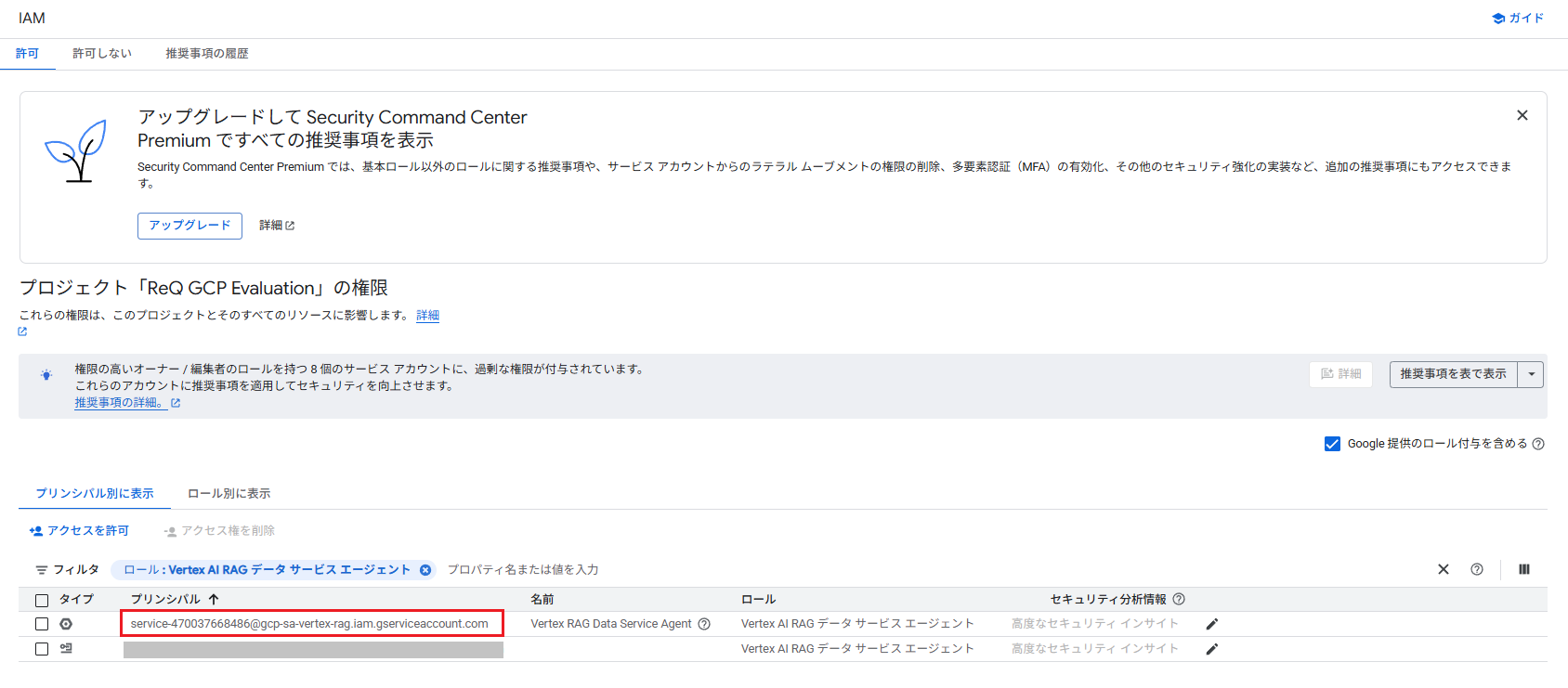
IAMコンソールに移動し、公式ドキュメントに沿って設定を行います。
「Google 提供のロール付与を含める」にクリックを入れ、一覧から「Vertex AI RAG データ サービス エージェント」のサービスアカウントを検索します。
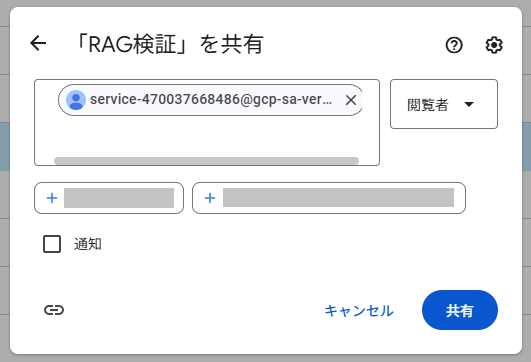
対象フォルダで「共有」をクリックし、サービスアカウントと共有します。権限は「閲覧者」とします。
アプリケーション実装
Cloud Shell を開いて以下のコマンドを実行し、仮想環境の作成までを行います。
# workspace 作成
mkdir -p workspace/rag_engine
cd workspace/rag_engine/
# 仮想環境の作成と有効化
python -m venv env
source env/bin/activate
Vertex AI SDK for Python をインストールします。
pip install --upgrade google-cloud-aiplatform
Pythonプログラムは以下を使用します。ご自身で利用する際は、プロジェクトIDや対象ロケーション、RAGコーパスなど適宜修正してください。
import vertexai
from vertexai import rag
from vertexai.generative_models import GenerativeModel, Tool
# Vertex AI API の初期化
vertexai.init(
project="my-project", # プロジェクトID
location="us-central1", # 対象ロケーション
)
def list_rag_corpora():
return rag.list_corpora()
def create_rag_corpus():
embedding_model_config = rag.RagEmbeddingModelConfig(
vertex_prediction_endpoint=rag.VertexPredictionEndpoint(
publisher_model="publishers/google/models/text-multilingual-embedding-002" # 埋め込みモデル
)
)
rag_corpus = rag.create_corpus(
display_name="test_corpus", # RAGコーパスの名前
backend_config=rag.RagVectorDbConfig(
rag_embedding_model_config=embedding_model_config
),
)
def import_files_to_rag_corpus(rag_corpus_name):
paths = ["gs://tani-bucket-20250424/rag"] # データソースのパス
rag.import_files(
rag_corpus_name,
paths,
# Optional
transformation_config=rag.TransformationConfig(
chunking_config=rag.ChunkingConfig(
chunk_size=512,
chunk_overlap=100,
),
),
max_embedding_requests_per_min=1000, # Optional
)
def direct_rag_retrieval(rag_corpus_name, query):
rag_retrieval_config = rag.RagRetrievalConfig(
top_k=4, # Optional
filter=rag.Filter(vector_distance_threshold=0.5), # Optional
)
response = rag.retrieval_query(
rag_resources=[
rag.RagResource(
rag_corpus=rag_corpus_name,
)
],
text=query,
rag_retrieval_config=rag_retrieval_config,
)
print(response)
def create_rag_model():
rag_retrieval_config = rag.RagRetrievalConfig(
top_k=4, # Optional
filter=rag.Filter(vector_distance_threshold=0.5), # Optional
)
# Create a RAG retrieval tool
rag_retrieval_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_resources=[
rag.RagResource(
rag_corpus="projects/my-project/locations/us-central1/ragCorpora/4611686018427387904", # RAGコーパス
)
],
rag_retrieval_config=rag_retrieval_config,
),
)
)
# Create a Gemini model instance
rag_model = GenerativeModel(
model_name="gemini-2.0-flash-001", tools=[rag_retrieval_tool]
)
return rag_model
# RAG検索の結果を取得する
def rag_search(query):
rag_model = create_rag_model()
response = rag_model.generate_content(query)
return response.text
def main():
query = "レック・テクノロジー・コンサルティング株式会社において1年間に取得可能なシックリーブの最大日数は?"
print("-----")
print(direct_rag_retrieval("projects/my-project/locations/us-central1/ragCorpora/4611686018427387904", query))
print("-----")
print(rag_search(query))
if __name__ == "__main__":
main()
出力
(env) fuma_tani@cloudshell:~/workspace/rag_engine (my-project)$ python main.py
-----
contexts {
contexts {
source_uri: "gs://tani-bucket-20250424/rag/従業員就業規則他_20240328.pdf"
text: "但し、翌年 1 月より勤続年数 1 年とし前項の規定を適用する。\r\n5.該当年度に行使しなかった年次有給休暇は、次年度に限り繰り越すことができる。\r\n6.年次有給休暇は、半日単位で取得することができる。\r\n7.年次有給休暇は、従業員による事前の請求により従業員が指定した時季に与える。但し、業務の都合に\r\nよりやむを得ない場合には他の時季に変更することができる。\r\n第22条 (シックリーブ)\r\n1.従業員は次のいずれかに該当する場合は、前条に定める年次有給休暇とは別に 1 年度に最高 10 日間を限\r\n度としてシックリーブを有給で取得することができる。"
source_display_name: "従業員就業規則他_20240328.pdf"
score: 0.22227487458030015
chunk {
text: "但し、翌年 1 月より勤続年数 1 年とし前項の規定を適用する。\r\n5.該当年度に行使しなかった年次有給休暇は、次年度に限り繰り越すことができる。\r\n6.年次有給休暇は、半日単位で取得することができる。\r\n7.年次有給休暇は、従業員による事前の請求により従業員が指定した時季に与える。但し、業務の都合に\r\nよりやむを得ない場合には他の時季に変更することができる。\r\n第22条 (シックリーブ)\r\n1.従業員は次のいずれかに該当する場合は、前条に定める年次有給休暇とは別に 1 年度に最高 10 日間を限\r\n度としてシックリーブを有給で取得することができる。"
page_span {
first_page: 7
last_page: 7
}
}
}
...
}
None
-----
レック・テクノロジー・コンサルティング株式会社では、従業員は1年度に最高10日間を限度としてシックリーブを有給で取得できます。
Cloud Storage にはRe:Qの就業規則を入れておきました。参照データを確認すると、たしかに就業規則のシックリーブに関する記載が参照されたことが確認できます。
※scoreは関連度を表し、数値が低いほど関連度が高いです。
補足:Vertex AI Studio 経由で利用
Vertex AI Studio の「プロンプトを作成」を開き、グラウンディングを有効にすることでRAGコーパスを利用したクエリを実行することが可能です。
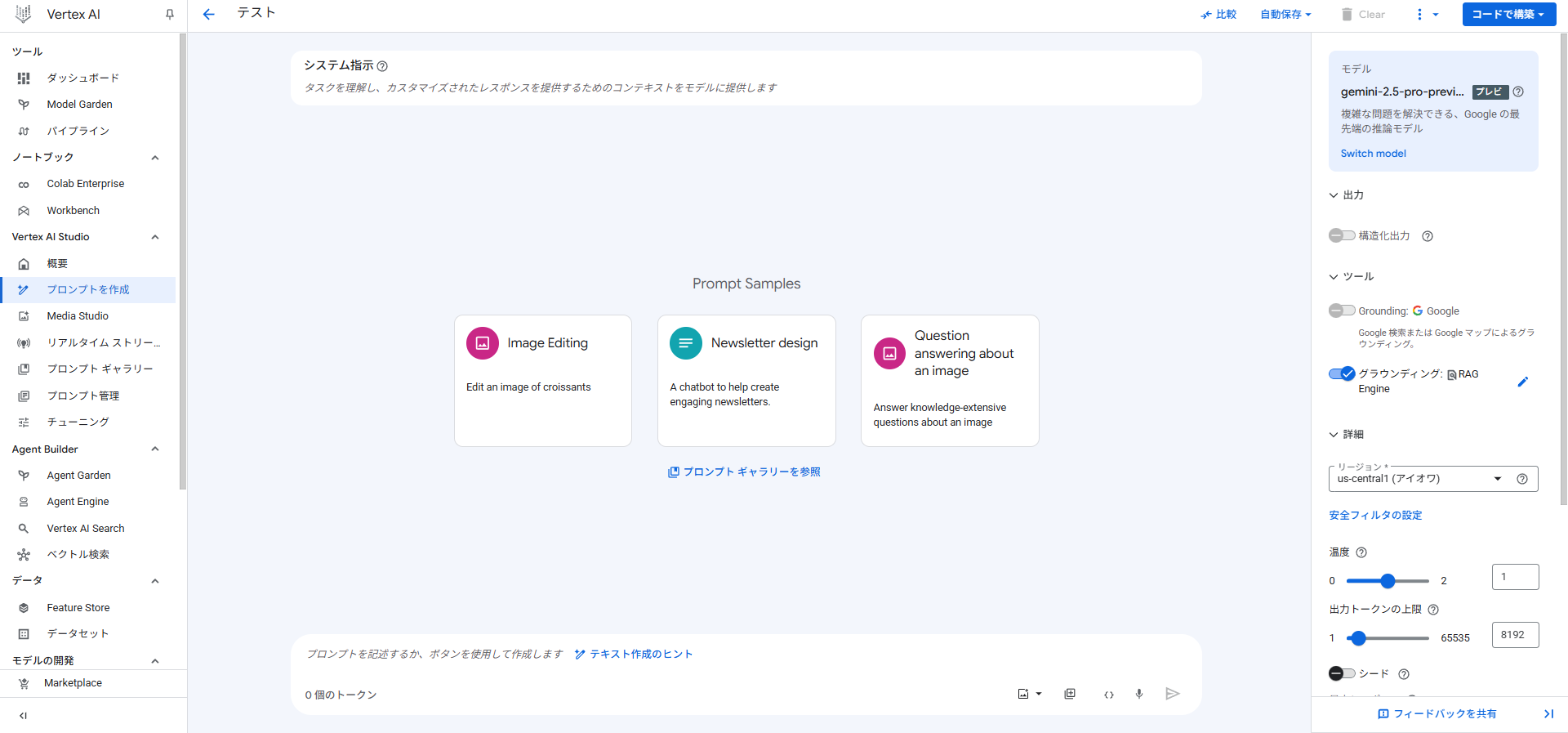
「ツール」→「グラウンディング」で「RAG Engine」を選択し、対象のコーパスを選択して「保存」をクリックします。
利用上の課題
実際に Vertex AI RAG Engine を使ってみた中で感じた課題は以下の通りです。
対象ファイルやフォルダはサービスアカウントと共有する必要がある
今回 Vertex AI RAG Engine を検証した目的の一つとして、Google Driveのファイルなどを扱う際に各ユーザの権限で自然にアクセスできる形にしたい、という要件がありました。
しかし、裏でサービスアカウントがデータソースにアクセスしに行く都合上、サービスアカウントに対して事前にファイルやフォルダを共有する必要があり、上記の要件をそのまま満たすことはできませんでした。
RAGコーパスがどこで管理されているのかよくわからない
プログラムを実行した際にRAGコーパスが作成されますが、Amazon Bedrock Knowledge Bases のようにコンソールから確認できるナレッジベースやベクトルDBの実体がなく、どこで管理されているのかが不明です。
list_corpora()などのメソッドでprojects/my-project/locations/us-central1/ragCorpora/4611686018427387904のようなパスを取得することはできますが、それ以上の情報はわかりません。
RAGコーパスの作成から行うとレスポンスに時間がかかる
クイックスタートのプログラムは実行するたびにRAGコーパスの作成から行う形になっていますが、RAGコーパスの作成から行うとレスポンスに時間がかかってしまいます。特定のタイミングだけ更新するなど、RAGコーパスを効果的に運用するなんらかの仕組みが必要になりそうです。
課金体系がよくわからない
比較的新しいサービスのためか、公式ドキュメントにも課金に関する詳しい情報がなく、料金体系がよくわかりません。
Amazon Bedrock Knowledge Bases と同様に考えると、以下の要素で課金が発生するはずです。
- 基盤モデル
- RAG検索サービス
- インデックス
- 検索
- ストレージ
しかし、料金計算ツールでサービス別に見積をしようにも、現時点で対応するサービスの項目がありません。
現状、APIで対応するサービスの利用状況を確認し、実際に発生した費用から確認するしか方法がなさそうです。今後公式からも情報が出てくるかもしれませんが、実際に使ってみるまでわからないというのは少し不安に感じます。
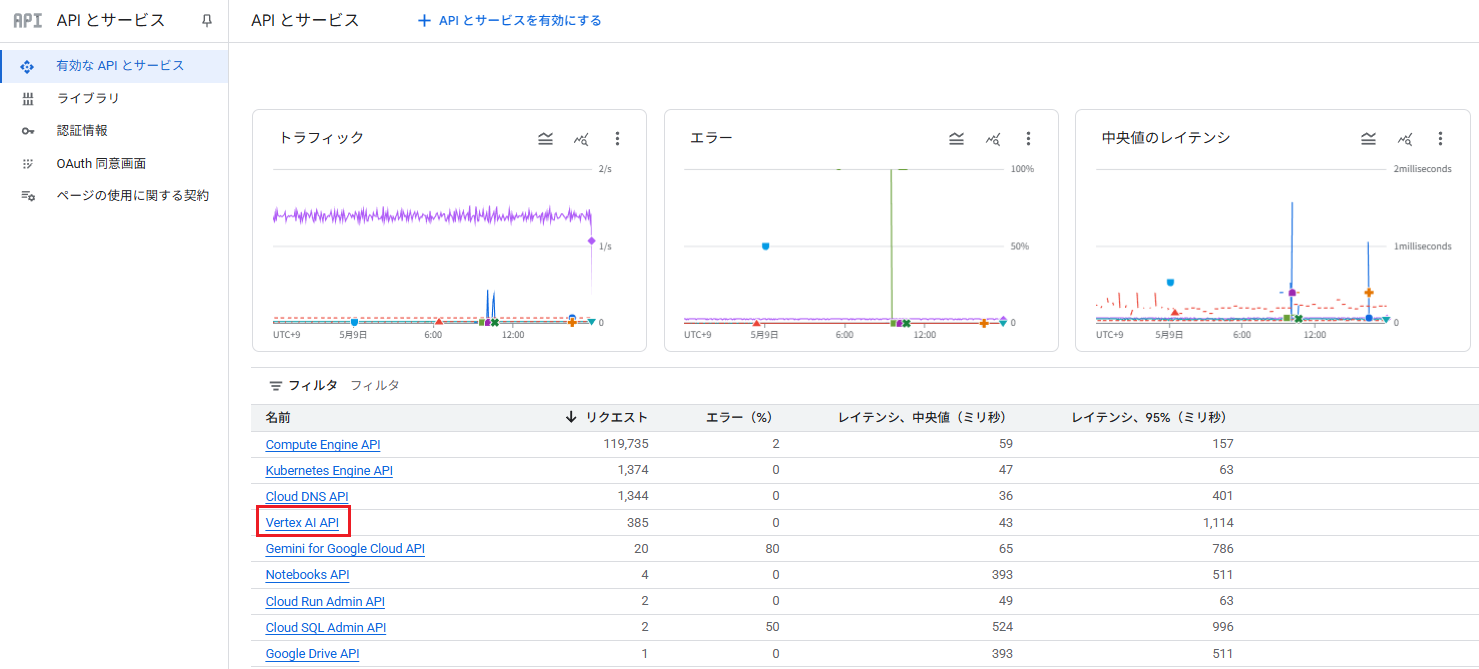
利用状況確認
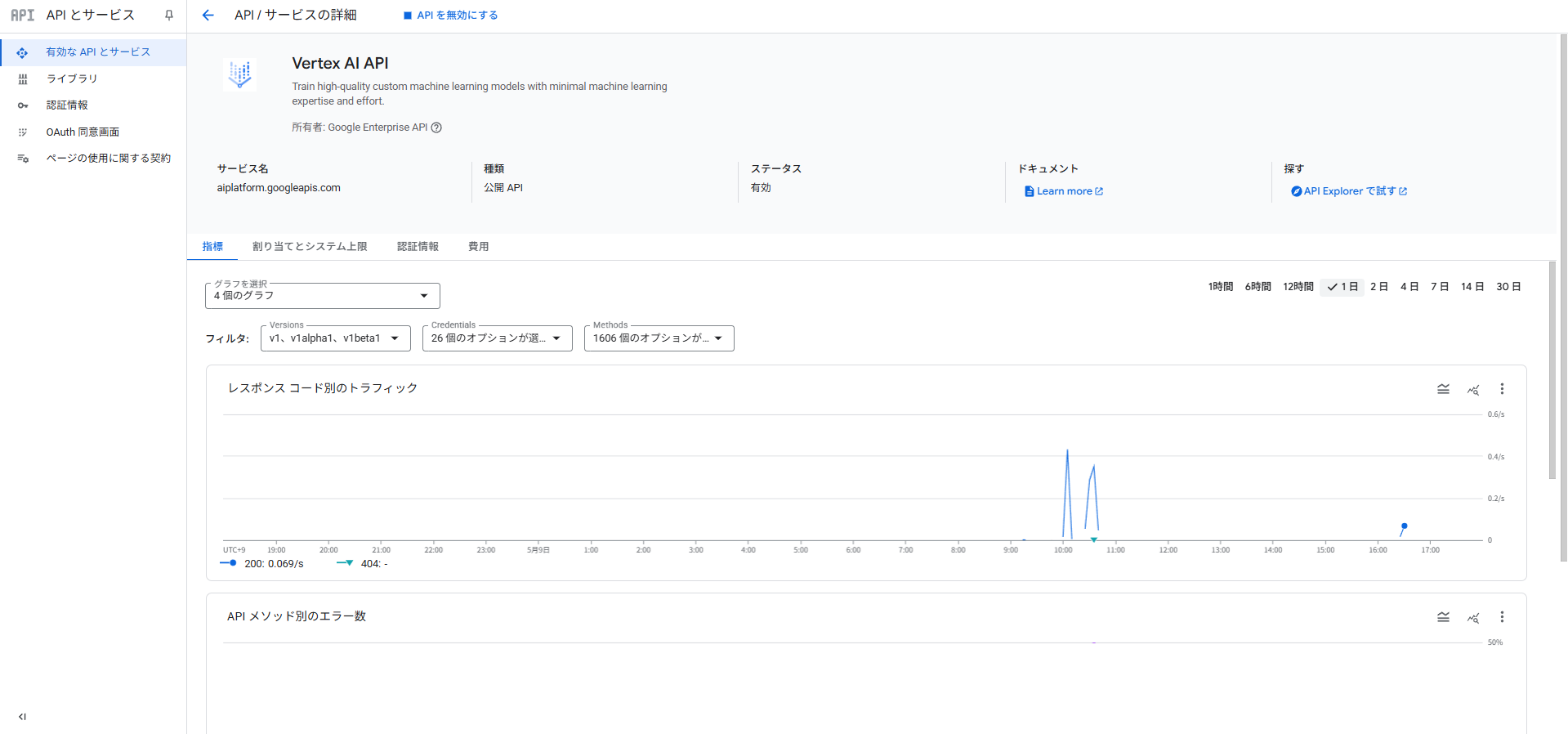
「APIとサービス」→「有効なAPIとサービス」の「Vertex AI API」から確認可能です。
Vertex AI API の使用状況の中に RAG Engine のAPIデータも含まれています。
まとめ
Vertex AI RAG Engine は、Google Cloud 上でRAG検索システムを簡単に構築できるサービスです。
Cloud Storage や Google Drive 等のデータソースに対応しており、データを簡単に取り込める一方で、Google Drive の場合はサービスアカウントとファイルやフォルダの共有をする必要があるなど注意点もあります。
また、RAGコーパスのデータソースの同期・更新に関する問題や課金に関する問題など、実際にアプリケーションに組み込むうえで考えなければならない課題もあるため、ユースケースに応じて慎重に利用を検討することが求められます。
参考
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

