Amazon Bedrock Knowledge Basesを使ってみる:導入からプログラム実装と注意点
2025.06.09
- AWS
- クラウド
- データエンジニアリング
- 生成AI
Amazon Bedrock Knowledge Bases は、RAG検索の仕組みを簡単に実現できるサービスです。
通常、RAGを構成する場合はデータのベクトル化や検索、回答生成といった複数のステップを踏む必要がありますが、Amazon Bedrock Knowledge Bases ではこれら一連のステップが内部で実行される仕組みになっており、APIを1回呼び出すだけで回答を得られるようになっています。
今回はそんな Amazon Bedrock Knowledge Bases の導入からプログラム実装までの具体的な手順についてご紹介します。
導入
ナレッジベース作成
Amazon Bedrock コンソールから「ナレッジベース」を開き、「作成」→「ベクトルストアを含むナレッジベース」をクリックします。
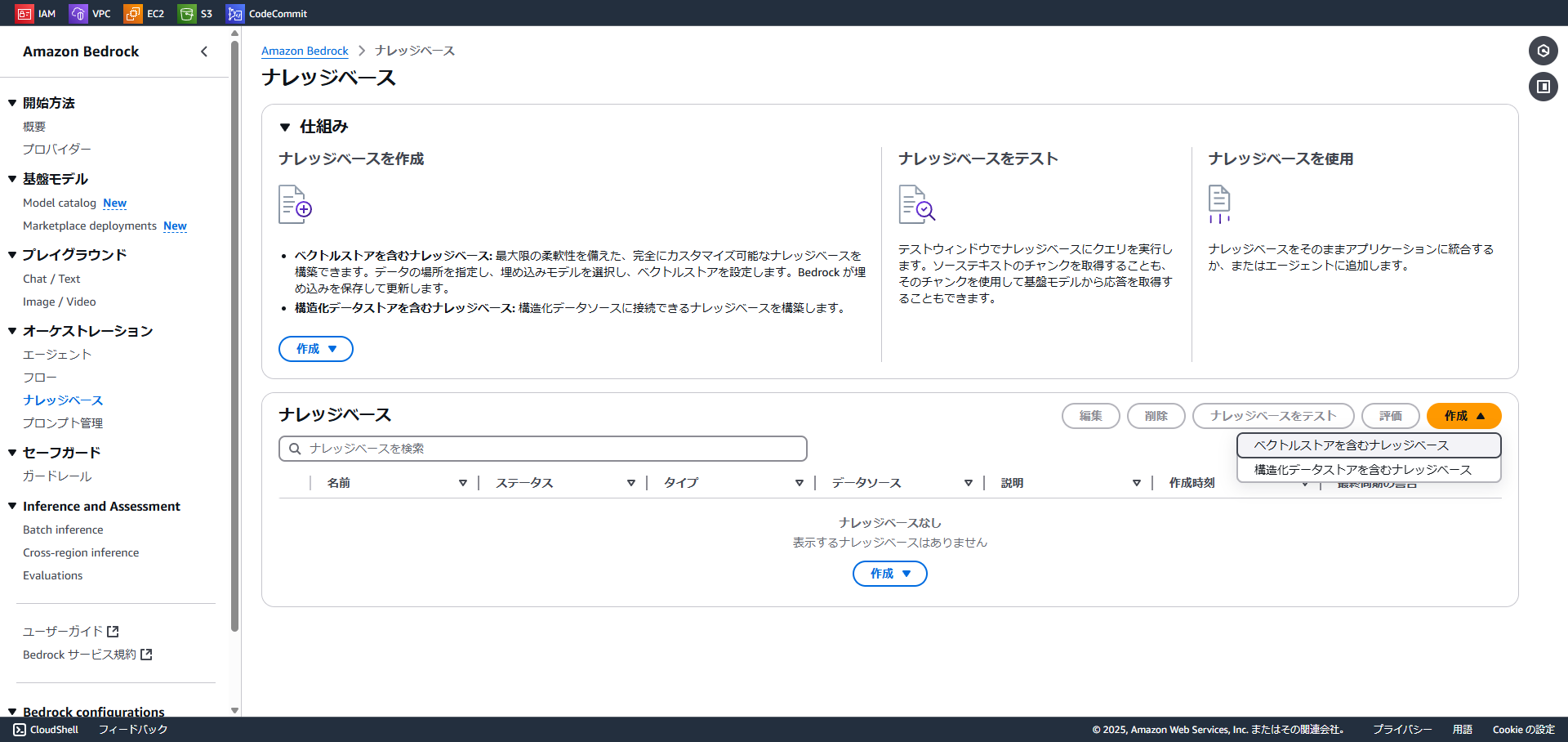
ナレッジベース名は適当な名前を入力し、IAM許可は「新しいサービスロールを作成して使用」にチェックを入れます。
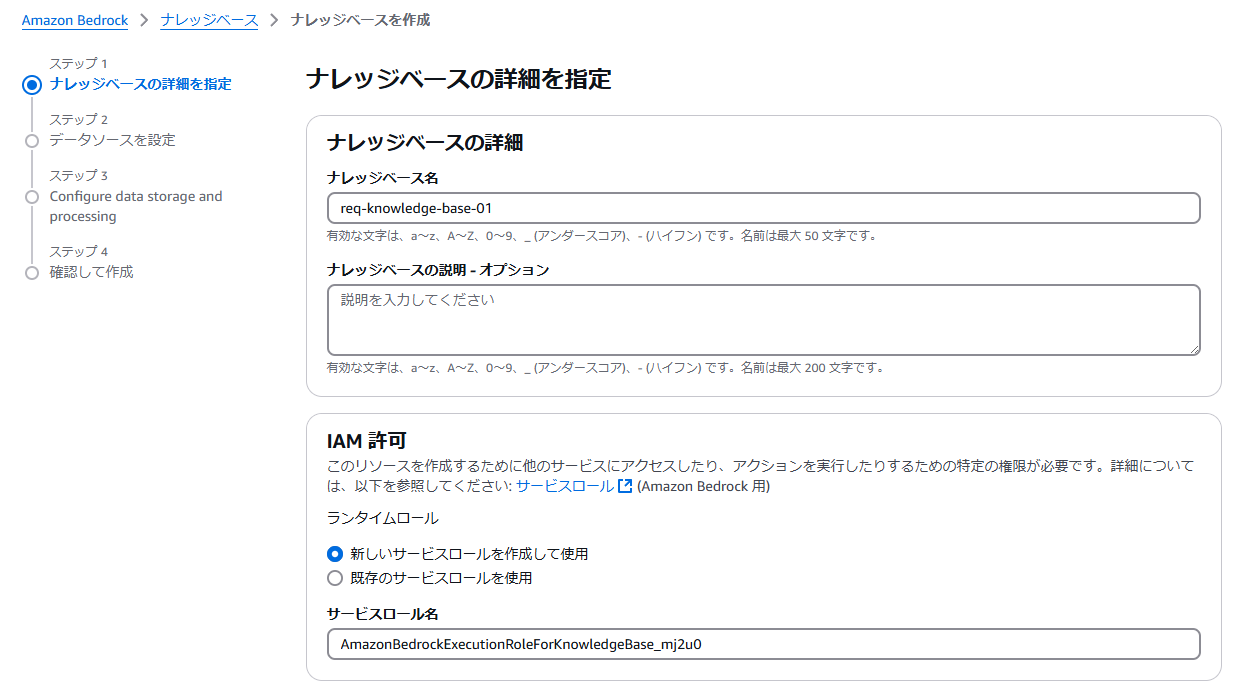
データソースはS3を選択します。他はデフォルトのままで次へ進みます。
データソースの設定を行います。
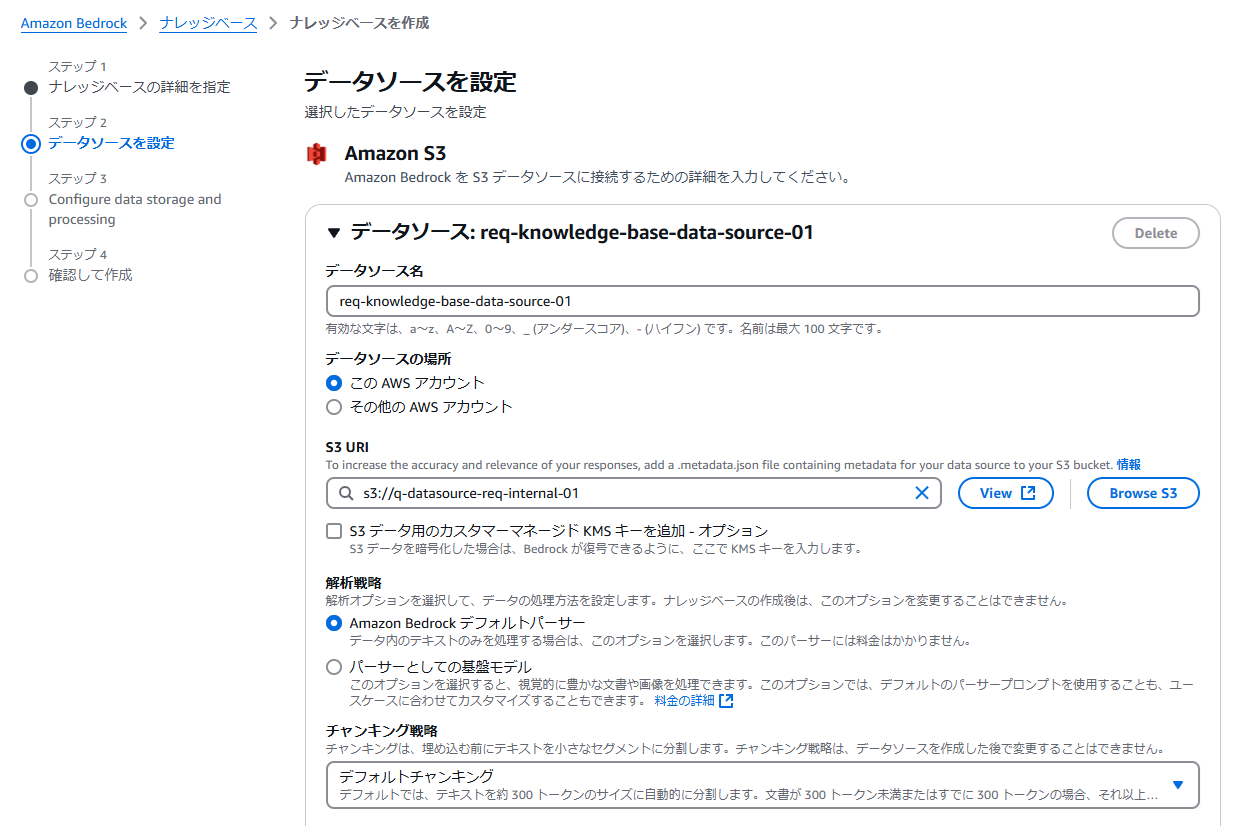
設定画面下部で、以下の設定を行うことができます。
- 解析戦略:データ処理用の解析オプション
- Amazon Bedrock デフォルトパーサー
- パーサーとしての基盤モデル(テキスト以外も処理する場合は選択)
- チャンキング戦略
- デフォルトチャンキング:テキストを約300トークンのサイズに自動的に分割
- 固定サイズのチャンキング:設定値に近いサイズで分割
- 階層型チャンキング:テキストチャンク(ノード)を親子関係の階層構造に整理
- セマンティックチャンキング:テキストチャンクまたは文のグループを意味的な類似度を基準に整理
- チャンキングなし:チャンキングを行わない
- 変換関数:既存のLambda関数でチャンク処理とドキュメントメタデータ処理をカスタマイズする
※解析戦略、チャンキング戦略はデータソース作成後に変更することはできないため注意が必要です。
Embedding 用のモデルの選択とベクトルデータベースを選択します。ベクトルストアは新規作成するか、既存のものを利用することができます。今回は新規作成します。
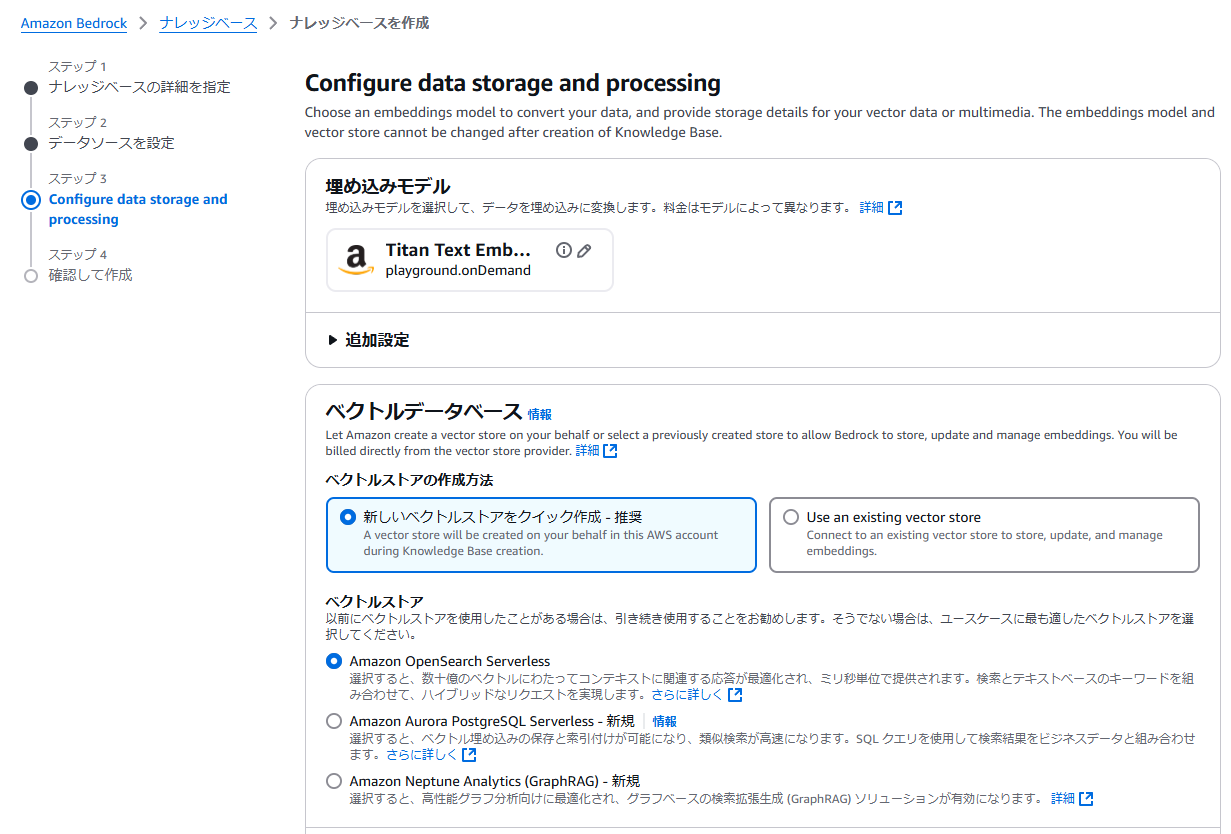
設定を確認し、問題なければ「ナレッジベースを作成」をクリックします。
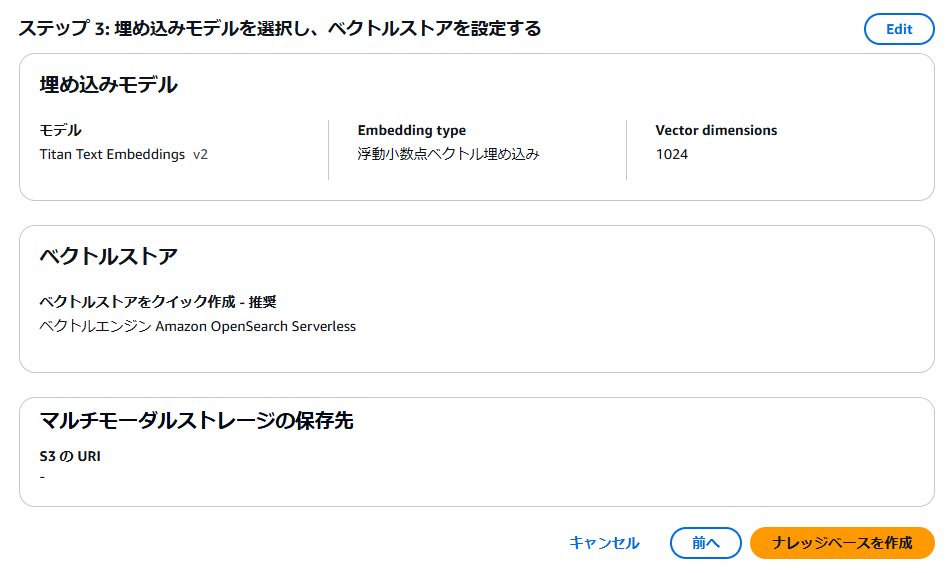
数分待つと、ナレッジベースが作成されます。
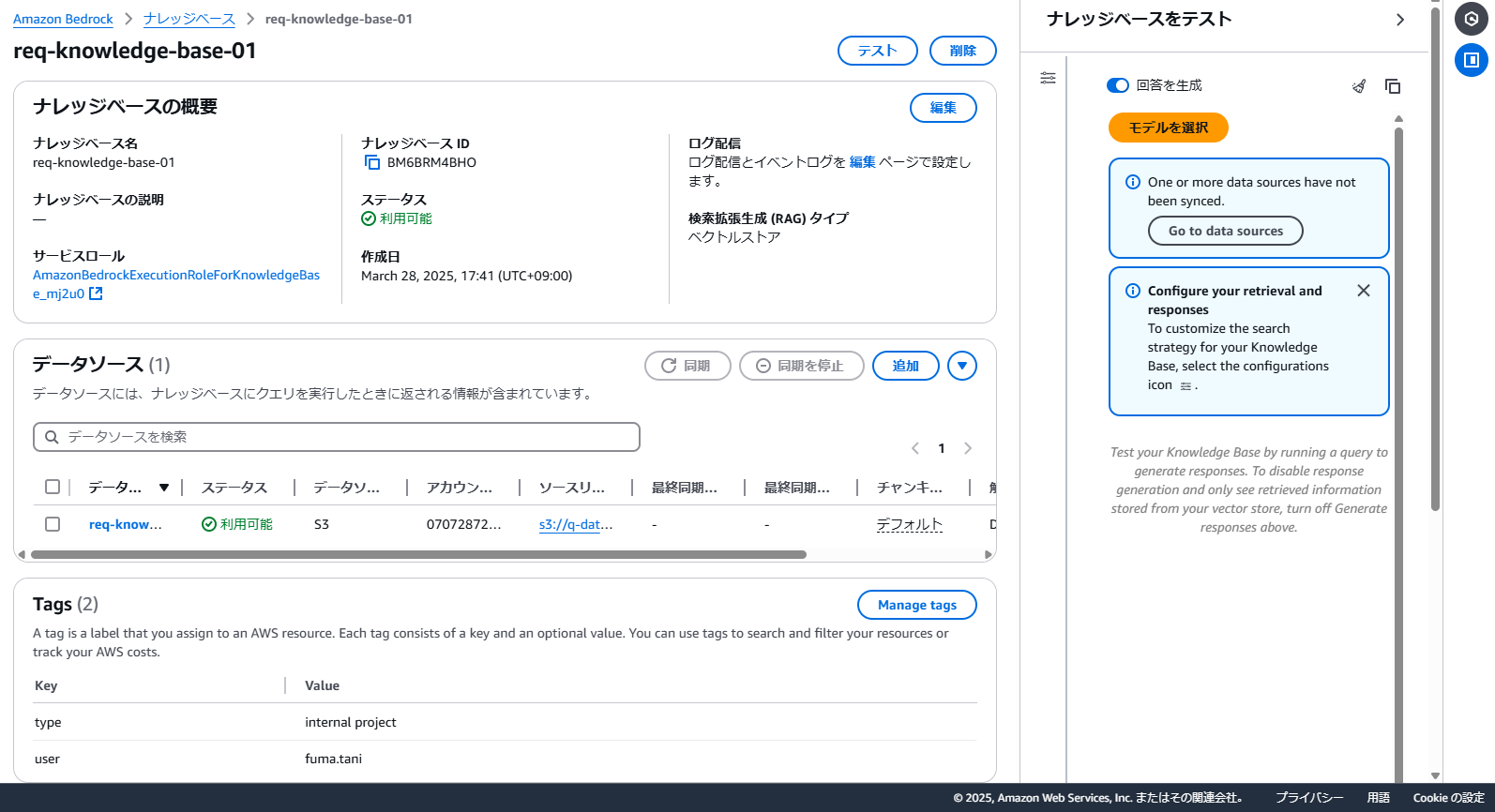
現在の状態ではデータソースが同期されていないため、対象のデータソースを一覧から選択し、「同期」をクリックします。
同期に失敗しました。。指定した埋め込みモデルが利用できないとのことです。

「Bedrock configurations」→「モデルアクセス」で、今回埋め込みモデルに指定している「Titan Text Embeddings V2」を有効化します。
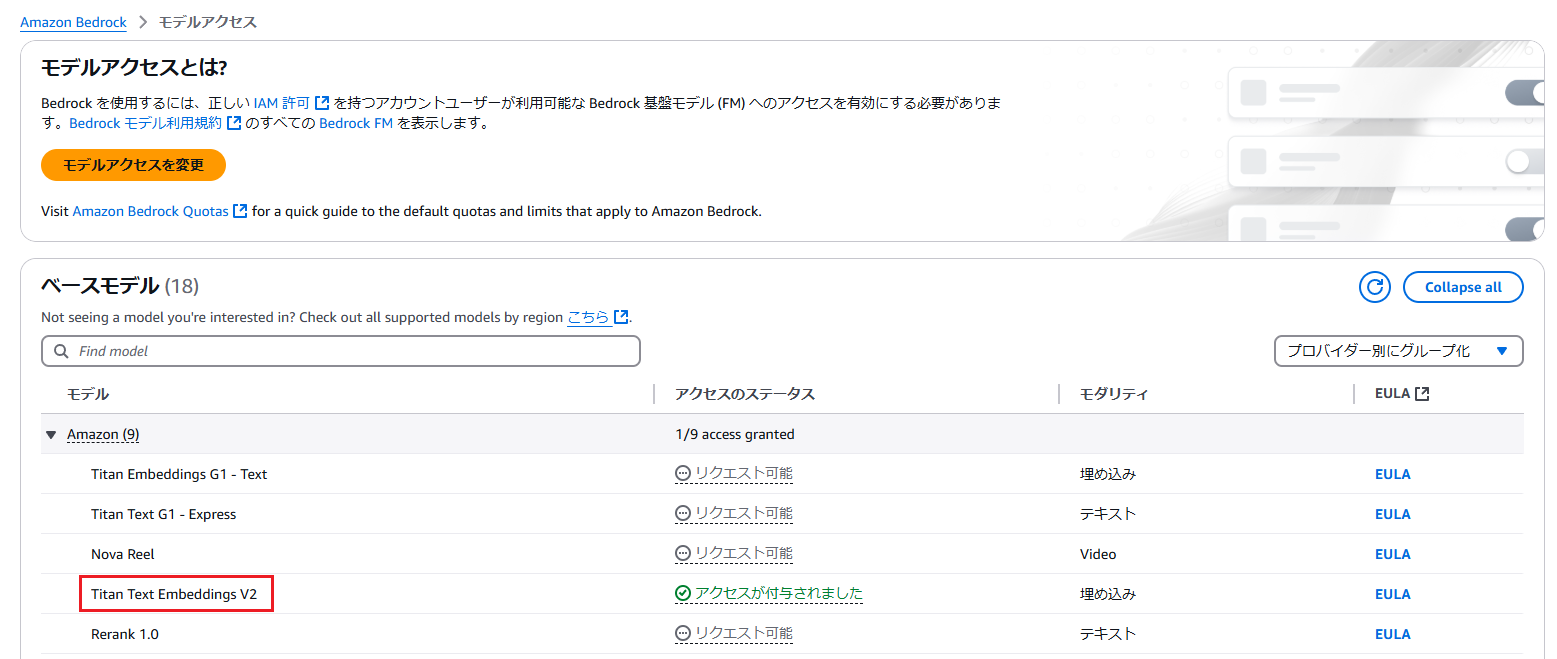
再度同期を行うと成功しました!

動作確認
「ナレッジベース」→「ナレッジベースをテスト」で、動作を確認することができます。
テキスト生成モデルとして「Nova Micro」を指定し、Re:Qの就業規則に基づいて質問をした結果は以下の通りです。就業規則の記載に基づき、質問に正しく回答できていることが確認できます。
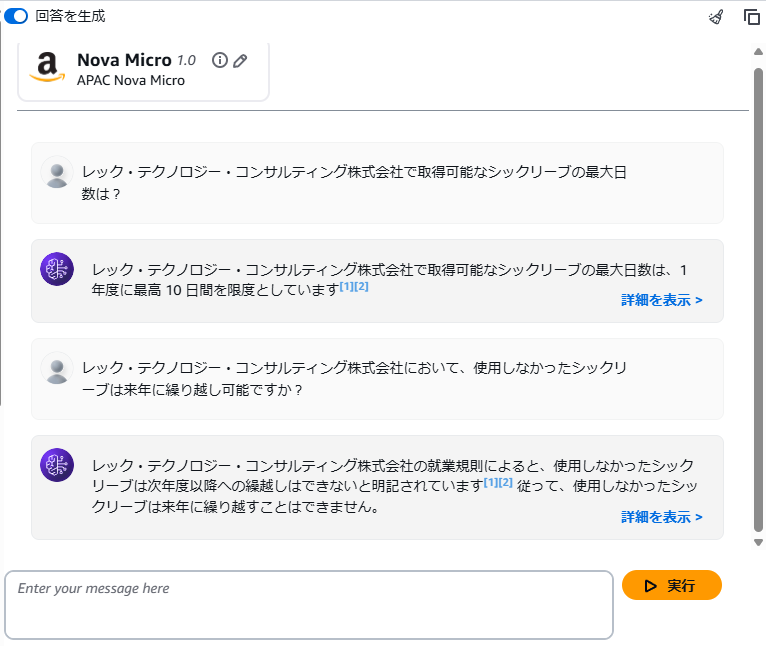
「詳細を表示」で参照したデータソースの詳細を確認することができます。
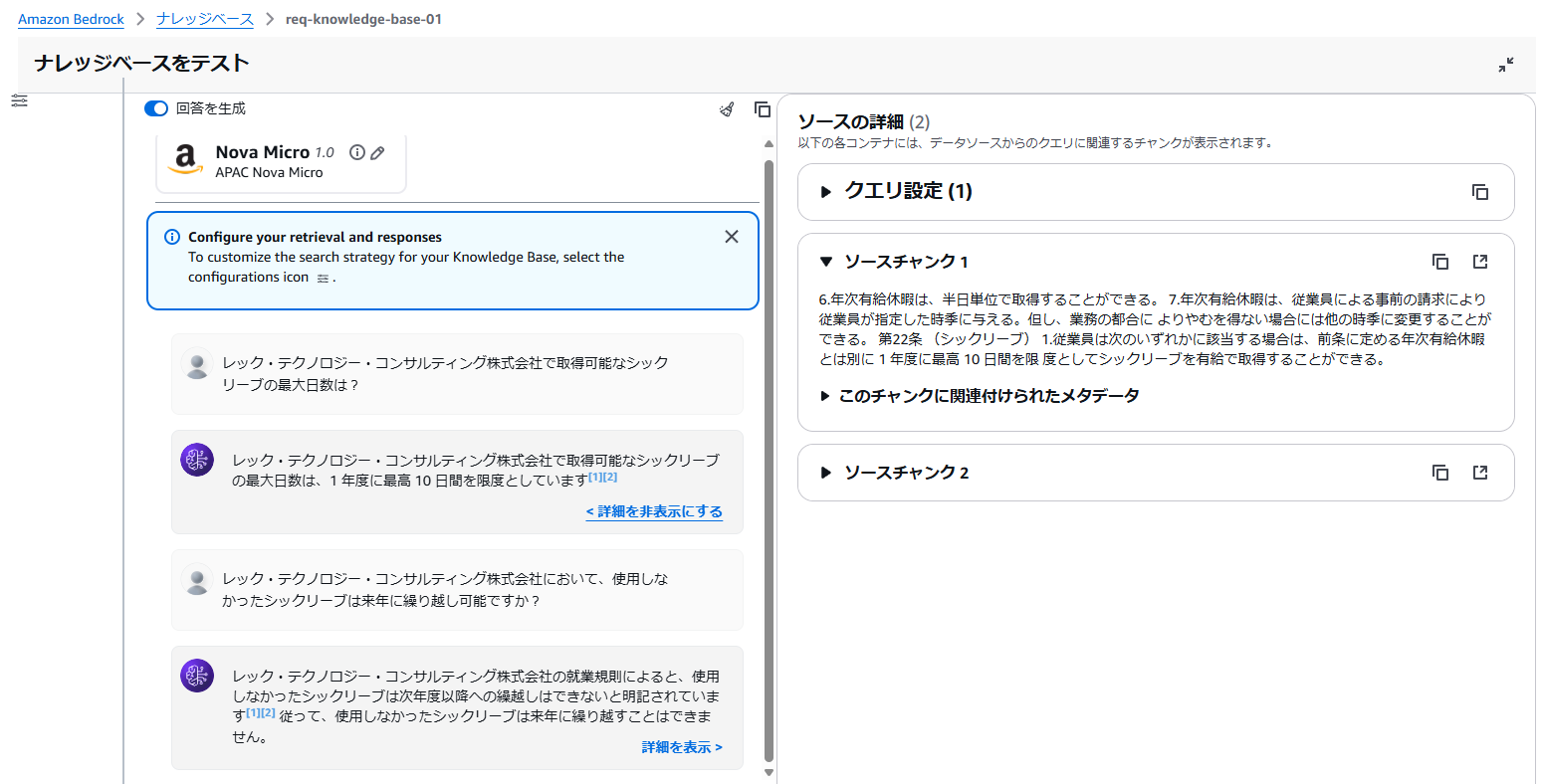
補足:データソース参照について
データソースの参照は、Amazon OpenSearch Service の検索結果に基づいて行われます。
「Amazon OpenSearch Service」→「Serverless Dashboard」で、作成されたナレッジベースのダッシュボードを開くことができます。
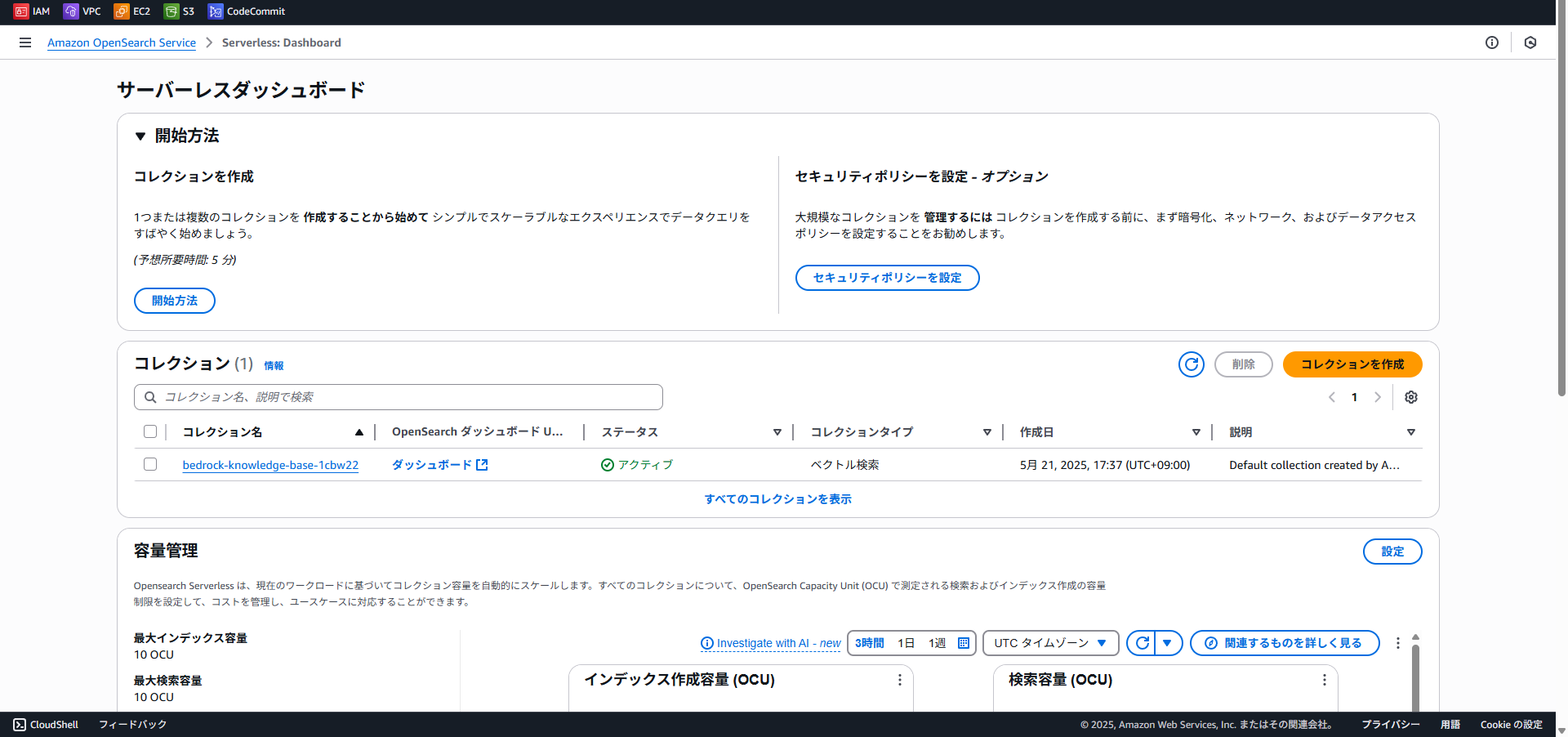
開いたダッシュボードのメニューで「Management」→「Dev Tools」をクリックすると、検索実行用のコンソールが開きます。試しに「シックリーブ」と検索すると、合計4つのドキュメントがヒットすることが確認できました。
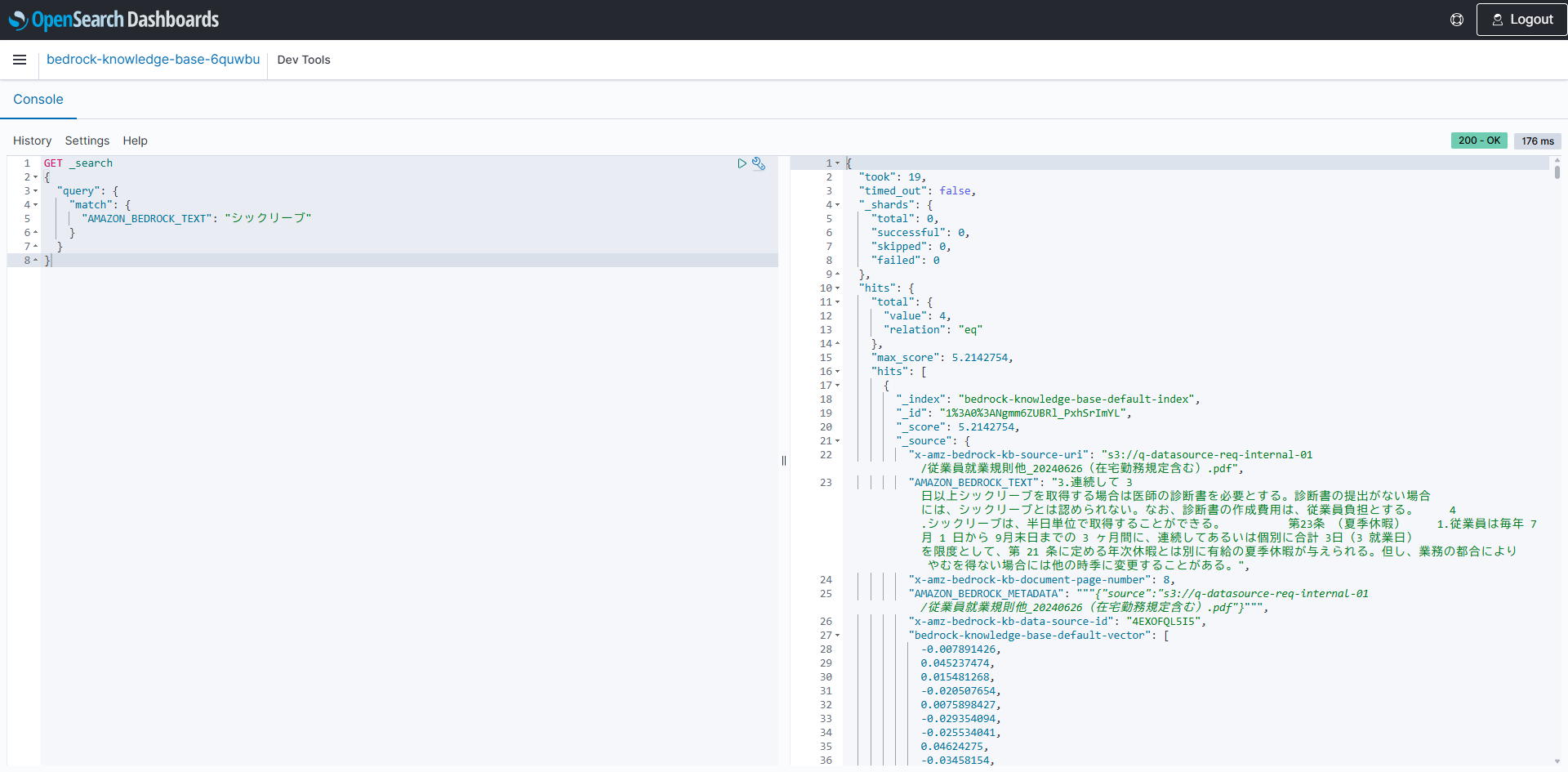
左側の検索リクエストは以下の通りです。
GET _search
{
"query": {
"match": {
"AMAZON_BEDROCK_TEXT": "シックリーブ"
}
}
}
アプリケーション実装
SDKを利用し、回答をプログラム経由で取得することが可能です。以下はPythonの実装例です。
import json
import boto3
def generate_response(query: str) -> str:
# Bedrockクライアントを作成
kb = boto3.client("bedrock-agent-runtime", region_name='ap-northeast-1')
# Retrieve and Generate
response = kb.retrieve_and_generate(
input={"text": query},
retrieveAndGenerateConfiguration={
"type": 'KNOWLEDGE_BASE',
"knowledgeBaseConfiguration": {
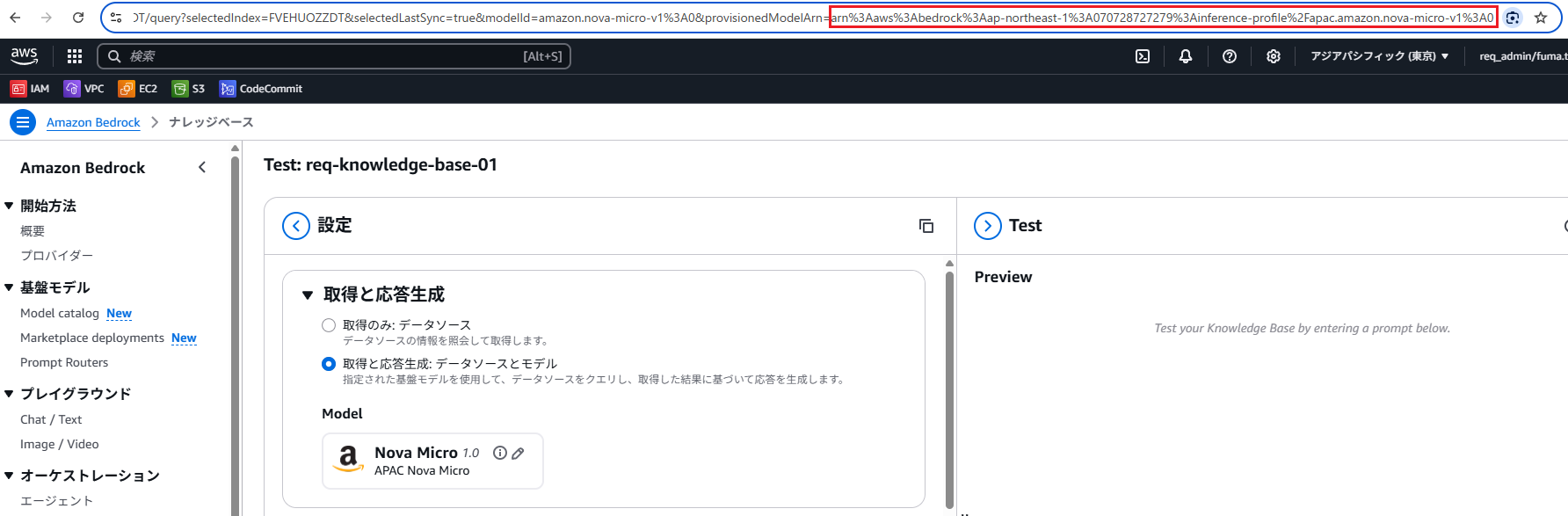
"knowledgeBaseId": "FVEHUOZZDT", # ナレッジベースID
"modelArn": "arn:aws:bedrock:ap-northeast-1:070728727279:inference-profile/apac.amazon.nova-micro-v1:0", # 回答を行うモデルのARN(詳細は補足に記載)
'retrievalConfiguration': {
'vectorSearchConfiguration': {
'numberOfResults': 10,
}
}
},
},
)
print("-----")
print(json.dumps(response, indent=2, ensure_ascii=False))
print("-----")
return response["output"]["text"]
if __name__ == "__main__":
print(generate_response("Re:Qが提供するデータエンジニアリングサービスの特徴は?"))
出力
(.venv) tani@PC174:~/rag-test-app/backend$ python app/main_knowledge_bases.py
-----
{
"ResponseMetadata": {
"RequestId": "821d87f4-89a1-424f-bc26-0703d4a5fe90",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"date": "Thu, 22 May 2025 01:40:43 GMT",
"content-type": "application/json",
"content-length": "8940",
"connection": "keep-alive",
"x-amzn-requestid": "821d87f4-89a1-424f-bc26-0703d4a5fe90"
},
"RetryAttempts": 0
},
"citations": [
{
"generatedResponsePart": {
"textResponsePart": {
"span": {
"end": 127,
"start": 0
},
"text": "Re:Qが提供するデータエンジニアリングサービスの特徴は、以下の点に集約されます:\n\n1. **インフラ領域の技術力ベース**:創業以来、Re:Qが強みとしてきたインフラ領域の技術力をベースに、データ活用を推進するための支援をワンストップで提供しています"
}
},
"retrievedReferences": [
{
"content": {
"text": "データエンジニアリングサービス 創業以来Re:Qが強みとしてきたインフラ領域の技術力をベースに、データ活用を推進するための支援をワンストップで提供します。 ①データ基盤構築サービス データ駆動型ビジネスの発展に伴い、データ分析やデータ活用が業務に密接に関わるようになりました。 それに伴い、システムに対して可用性やセキュリティ、運用性、性能といった要件も厳密に求められるようになっています。 一方でアジャイル型開発に合わせてスピーディに基盤を用意することも求められています。",
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://datasource-req-internal-01/データエンジニアリングサービス.docx"
},
"type": "S3"
},
"metadata": {
"x-amz-bedrock-kb-source-uri": "s3://datasource-req-internal-01/データエンジニアリングサービス.docx",
"x-amz-bedrock-kb-chunk-id": "1%3A0%3A0joB8pYBswI6OCDZxKM0",
"x-amz-bedrock-kb-data-source-id": "R1O4YXMBZH"
}
}
]
},
...
],
"output": {
"text": "Re:Qが提供するデータエンジニアリングサービスの特徴は、以下の点に集約されます:\n\n1. **インフラ領域の技術力ベース**:創業以来、Re:Qが強みとしてきたインフラ領域の技術力をベースに、データ活用を推進するための支援をワンストップで提供しています.\n\n2. **データ基盤構築サービス**:データ分析やデータ活用が業務に密接に関わるようになるにつれ、システムに対して可用性やセキュリティ、運用性、性能といった要件が厳密に求められています。また、アジャイル型開発に合わせてスピーディに基盤を用意することも求められます.\n\n3. **データパイプライン開発サービス**:様々なデータソースからのデータ収集、加工、蓄積、集計といったデータパイプライン開発と、可視化/分析のためのダッシュボード開発を一貫して実施しています.\n\n4. **伴走型支援サービス**:データ活用を内製化で進めるためのユーザ企業様向けに、計画・立案から導入、運用支援までを伴走型で支援します。ユーザ企業様が独力でデータ活用を推進し、ビジネスの成果に繋げられるよう、様々な面でサポートします.\n\nこれらの特徴により、Re:Qはデータ活用を促進するための総合的なソリューションを提供しています。"
},
"sessionId": "c836ee40-6c87-4c22-8388-fe6d87422644"
}
-----
Re:Qが提供するデータエンジニアリングサービスの特徴は、以下の点に集約されます:
1. **インフラ領域の技術力ベース**:創業以来、Re:Qが強みとしてきたインフラ領域の技術力をベースに、データ活用を推進するための支援をワンストップで提供しています.
2. **データ基盤構築サービス**:データ分析やデータ活用が業務に密接に関わるようになるにつれ、システムに対して可用性やセキュリティ、運用性、性能といった要件が厳密に求められています。また、アジャイル型開発に合わせてスピーディに基盤を用意することも求められます.
3. **データパイプライン開発サービス**:様々なデータソースからのデータ収集、加工、蓄積、集計といったデータパイプライン開発と、可視化/分析のためのダッシュボード開発を一貫して実施しています.
4. **伴走型支援サービス**:データ活用を内製化で進めるためのユーザ企業様向けに、計画・立案から導入、運用支援までを伴走型で支援します。ユーザ企業様が独力でデータ活用を推進し、ビジネスの成果に繋げられるよう、様々な面でサポートします.
これらの特徴により、Re:Qはデータ活用を促進するための総合的なソリューションを提供しています。
今回、S3にはRe:Qホームページに記載のデータエンジニアリングサービスの説明文書を入れておきました。レスポンスのcitationsには参照したデータの詳細が記載されており、たしかにS3のドキュメントが参照されたことが確認できます。
SDKはPython以外にもC++, Java, JavaScriptなどでサポートされています。詳細は以下のページをご参照ください。
RetrieveAndGenerate - Amazon Bedrock
補足:
- 今回、boto3の認証はローカル端末のセッションをもとに暗黙的に実行されています。
modelArnは、「ナレッジベース」→「ナレッジベースをテスト」でモデル選択後に表示されるURLから取得できます。
課金について
上記までで一通りのご紹介は終わりですが、忘れてはいけないのが課金のお話。Amazon Bedrock Knowledge Bases は非常に便利で使いやすいサービスですが、課金面で注意が必要です。
課金対象となる要素は以下の通りです:
- 基盤モデル
- RAG検索サービス
基盤モデルは、高価なモデルを使わない限り大したコストはかかりません。
例:Amazon Nova Micro の場合
入力100万トークンあたり$0.042、出力100万トークンあたり$0.168なので、1人あたり1日最大入力1万トークン、出力1万トークンで平均100人が20日間利用するとした場合、
1 x ($0.042 + $0.168) / 100 x 100 x 20 = $4.2 ≒ 600円 (1ドル144円)
注意すべきは、RAG検索サービスの部分です。
デフォルトでは、RAG検索サービスは Amazon OpenSearch Service が使われます。この Amazon OpenSearch Service がくせ者で、インデックスと検索に結構な費用がかかります。
※課金単位はOCU(OpenSearch Compute Units)で、データのインデックス作成用と検索用の2つのラベルがあり、時間単位で課金されます。本番で最低2OCU、開発で最低1OCUが必要です。
例:100GBのデータをインデックスする場合
- インデックス:0.5OCU x $0.334 x 24h * 30 = $120.24
- 検索:0.5OCU x $0.334 x 24h * 30 = $120.24
- ストレージ:100GB x 0.026 = $2.6
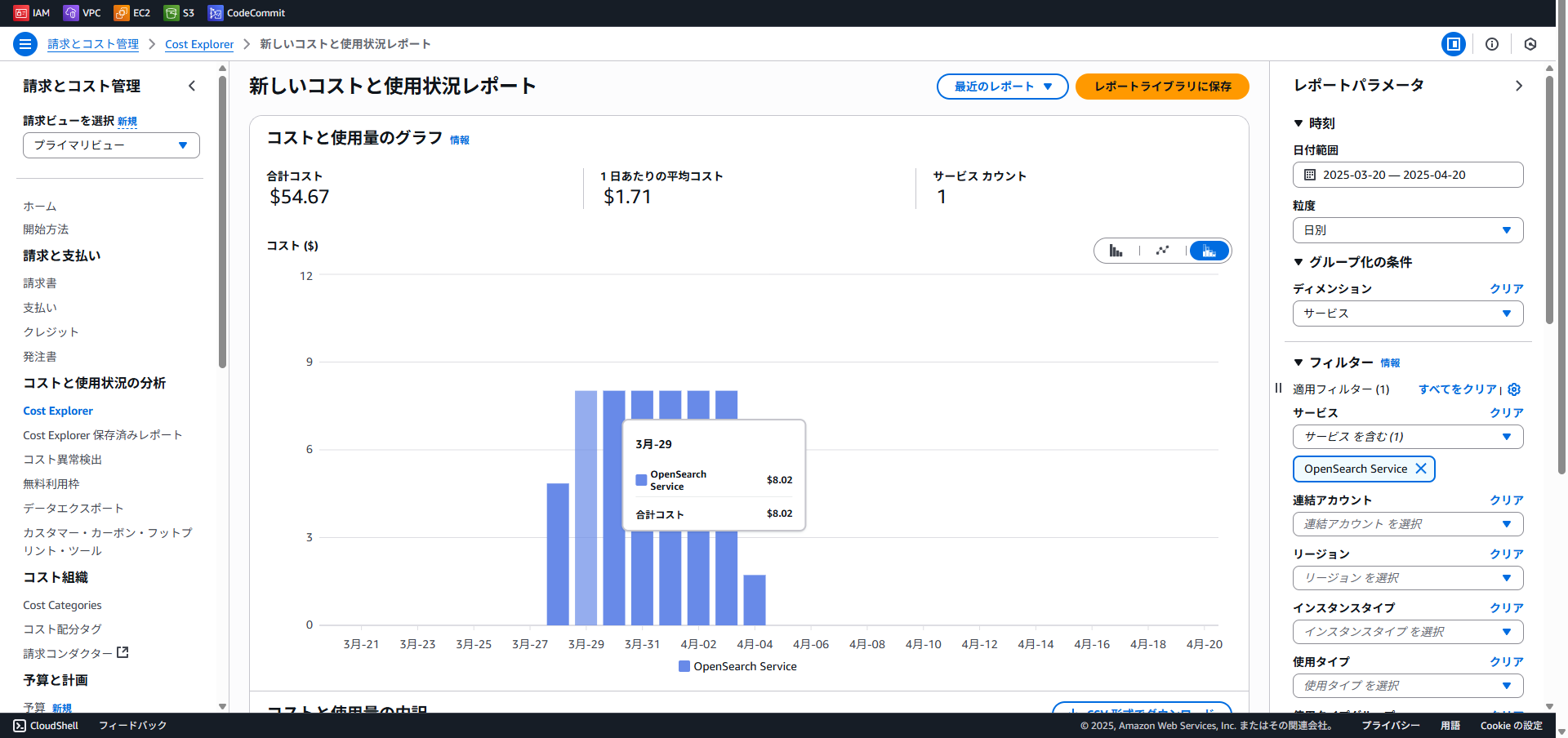
より、月額コストは $243.08 ≒ 35,000円 (1ドル144円)
このように、ストレージはS3なので大したコストはかかりませんが、インデックスと検索に大きな費用がかかります。OpenSearch Service はコレクションが存在する限り常時稼働扱いなので、使っていなくても課金されてしまう点に注意が必要です。
実際、検証期間のコストを確認してみると、毎日 $0.334 * 24h ≒ $8.02 が課金されていました。
まとめ
Amazon Bedrock Knowledge Bases では、コンソールから簡単にナレッジベースの作成やデータソースの同期を行うことができます。
データのパースやチャンキング、変換処理に関する設定もカスタマイズでき、出来合いのRAGサービスに比べて自由度が高いことが特徴です。また、APIやSDKが充実しており、プログラム実装も手間いらずでできるため、AWS上でさくっとRAG検索システムを構築したいという場合にうってつけです。
ただし、RAG検索のベースコストが高いため、課金には注意しながら利用する必要があります。
参考
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

