Azure Databricks のディザスタリカバリについて
2025.04.16
- Azure
- Databricks
- クラウド
- データエンジニアリング
オンプレミス環境に比べて安心感のあるクラウドサービスですが、天災やサイバー攻撃などが原因で特定の地域でサービスが停止してしまう・・・といった可能性もゼロではありません。
本記事では、そんな事態を想定した Azure Databricks の障害復旧(ディザスタリカバリ)について解説します。
リージョン内の高可用性保証
ディザスタリカバリはリージョンをまたがるものに焦点を当てていますが、Azure Databricks は単一リージョン内で高可用性の保証を提供しています。
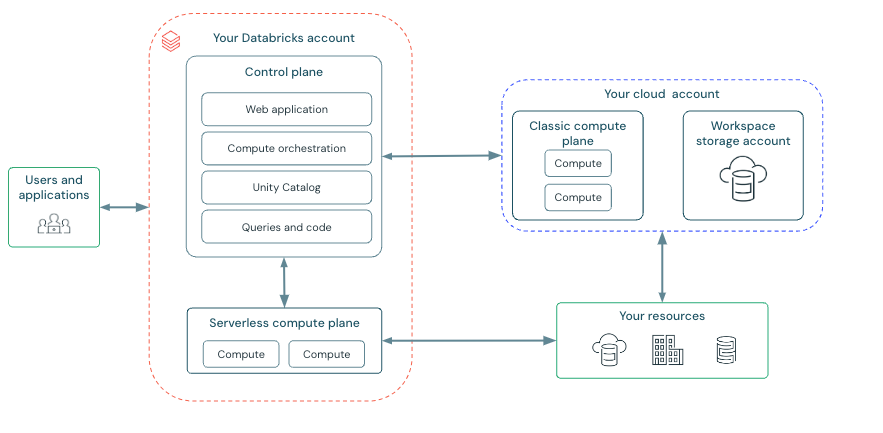
Azure Databricks では、リソースは以下の単位で管理されています。
- コントロールプレーン
- コンピュートプレーン
- その他
※Azure Databricks アーキテクチャの概要より引用
それぞれの可用性保証については以下の通りです。
コントロールプレーン
コントロールプレーンには Azure Databricks によって Azure Databricks アカウントで管理されるバックエンドサービスが含まれています。ノートブックのコードと実行結果、SQLクエリーとクエリ履歴、シークレット、Unity Catalog やHiveメタストアのメタデータなどがが格納されます。
ほとんどのコントロールプレーンのサービスは Kubernetes クラスターで実行されており、特定のAZ内のVMの損失を自動的に処理します。また、ワークスペースのデータは Premium Storage を持つデータベースに格納され、リージョン全体に複製されます。
コンピュートプレーン
コンピュートプレーン(データプレーン)はデータを処理する場所であり、クラスターなどの計算リソースはここに含まれます。Databricks が提供するサーバレス計算リソースは(Databricks が独自に管理する)Azure Databricks アカウント内のコンピュートプレーン内にあり、従来の計算リソースは Azure 上のクラシックコンピュートプレーン内にあります。
クラスターのノードが失われた場合、クラスターマネージャーにより使用可能なAZからノードが復旧されます。ドライバーノード(ワーカーに指示を出す本体)が失われた場合は、ジョブまたはクラスターマネージャーによって再起動されます。
その他
コントロールプレーン、コンピュートプレーン以外のリソース(ストレージなど)の可用性は各種リソースの設定に依存します。例えば Unity Catalog のストレージの冗長性設定を ZRS(ゾーン冗長ストレージ)にしている場合は ZRS になり、データセンターレベルの障害が発生した場合でもデータが失われないことが保証されます。
ディザスタリカバリ
以降では Azure Databricks で想定されている一般的な復旧ワークフローと、ディザスタリカバリのために実施すべきステップについてまとめます。
はじめに:一般的な復旧ワークフロー
Azure Databricks のディザスタリカバリは通常、以下のように進行します。
- プライマリリージョンで障害が発生。
- クラウドプロバイダーと協力し状況を調査する。
- プライマリリージョンでの問題解決まで待機できない場合、セカンダリリージョンへのフェールオーバー(待機系システムへの切替)を検討する。
- 障害の影響がセカンダリリージョンには及ばないことを確認する。
- セカンダリリージョンにフェールオーバーする。
- ある時点で、プライマリリージョンでの問題が解決する。
- プライマリリージョンに復元(フェールバック)する。
※上記は簡略化して記載したものであるため、詳細内容についてはこちらをご参照ください。
ステップ1:要件の明確化
最初のステップとして、以下の内容を明確化する必要があります:
- 障害が発生した場合に影響を受けるサービスとその影響範囲
- どの地点を目標に復旧するか(目標復旧時点、RPO)
- どれくらいの時間を目標に復旧するか(目標復旧時間、RTO)
障害が発生した場合にビジネスに与える影響を調査し、ディザスタリカバリの際に注意すべき事項や必要な対応を明らかにします。
ステップ2:戦略とツールの選定
ステップ1で得られた内容をもとに、ディザスタリカバリのために必要な戦略やツールの選定を行います。
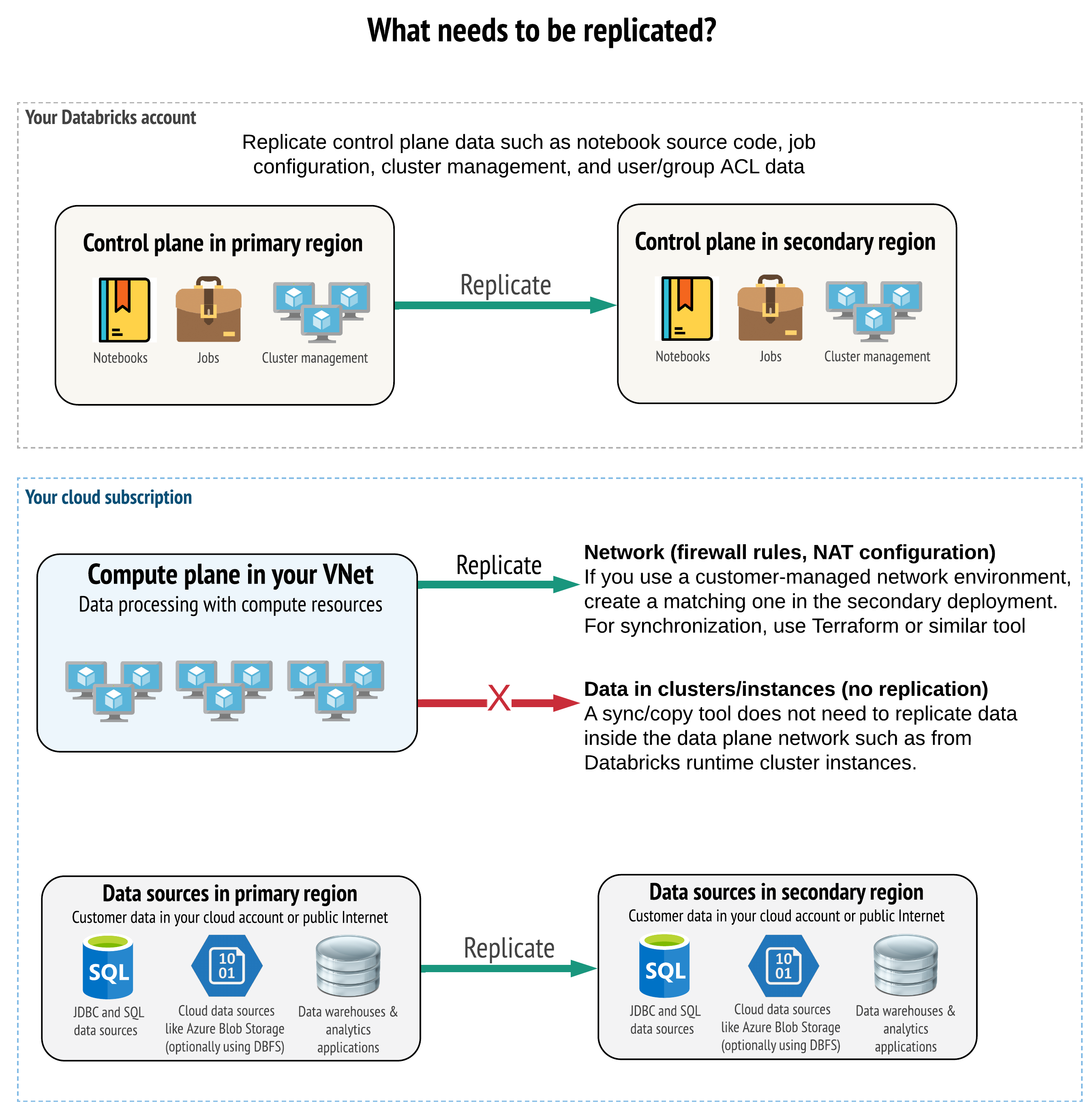
ディザスタリカバリにあたり、プライマリリージョンとセカンダリリージョン両方のコントロールプレーン、コンピュートプレーン、データソースに正しいデータを複製する必要があります。
※Azure Databricks アーキテクチャの概要より引用
リカバリーソリューション戦略
要件に応じて、以下のリカバリーソリューションから適切なものを選択します。
アクティブ/パッシブソリューション
セカンダリリージョンにパッシブデプロイ(待機系のワークスペース)を配置しておき、フェールオーバーのタイミングでアクティブデプロイ(本番ワークスペース)として運用する方式です。
本番切替の際に追加対応は必要になりますが、シンプルで実現しやすいというメリットがあります。読み取り専用のユースケースであれば、いつでもアクティブ/パッシブソリューションで実行可能です。
アクティブ/アクティブソリューション
セカンダリリージョンにもアクティブデプロイを配置しておき、プライマリリージョンと常に並列実行して運用する方式です。
アクティブ/パッシブソリューションと違い即座に切り替えられるというメリットはありますが、実現が難しく、追加のコストも発生するというデメリットがあります。
ツール選択
プライマリリージョンとセカンダリリージョンでデータを同期させるため、以下の2つのツールから選択することができます。
同期クライアント
本番のデータやリソースをプライマリリージョンからセカンダリリージョンに定期的にコピーします。
CI/CDツール
本番システムへの変更を両方のリージョンに同時にプッシュすることで、同じ状態を実現します。
上記のツールはニーズに応じて組み合わせて使うことも可能です。例えば、ノートブックのソースコードにはCI/CDツールを使用し、クラスターやアクセス制御などの構成に対しては同期クライアントを使用する、といった形をとることができます。
ステップ3:ワークスペースの同期
ワークスペースがすでに実稼働している場合、1回限りのコピー操作を実行して、パッシブデプロイをアクティブデプロイと同期させます。
最初の1回限りのコピー操作の後は、それ以降のコピーと同期の操作が高速になります。
ステップ4:データソースの準備
データの種類に応じて、ディザスタリカバリ用に適切なデータソースの構成を行う必要があります。
バッチデータ
ファイルがセカンダリリージョンのストレージにアップロードされることを確認する必要があります。
また、ワークロードではセカンダリリージョンのストレージに対して読み書きを行う必要があります。
ストリーミングデータ
ディザスタリカバリの際、セカンダリリージョンのデプロイを使用するようにデータソースを構成する必要があります。
ストリーミングの進行状況を同期し、セカンダリリージョンでデータが適切に処理されるようにします。
ステップ5:テスト
ディザスタリカバリのセットアップを定期的にテストし、正しく機能することを確認します。
また、要件を満たしているかについても確認を行い、必要に応じて修正や変更を加えます。
補助ツール
ディザスタリカバリのセットアップを補助するための以下のようなツールが公開されています。
- Databricks Terraform Provider
- Azure Databricks ワークスペースと関連するクラウドインフラストラクチャを管理可能なツール。独自の同期プロセスの開発に役立ち、Databricks でも使用が推奨されている。
- Databricks Sync (dbSync)
- Databricks ワークスペースをバックアップ、復元、同期するオブジェクト同期ツール。
さいごに
Azure Databricks のディザスタリカバリについてポイント解説しました。
ディザスタリカバリで注意すべき事柄や具体的な対応内容についてはこちらが非常に詳しいですが、本記事でディザスタリカバリの概要とイメージを掴んでいただけたら幸いです。
参考
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

