【Red Hat Summit 2026】 現地参加レポート:OpenShift Virtualizationの高可用性戦略
2026.06.01
- OpenShift
- RedHat Enterprise Linux
- インフラ
- コンテナ技術
- 仮想基盤
Re:Q Tech Blogをご覧いただきありがとうございます。
インフラ技術部のO.M.です。
アメリカ ジョージア州アトランタで開催された「Red Hat Summit 2026」に現地参加してきました!
私は絶賛OpenShiftについて勉強中のため、今回のサミットでは知識を増やすためにOpenShiftやOpenShift Virtualizationの機能や仕様に関するセッションをメインに聴講しました。
数々の興味深いセッションの中から、今回は
「OpenShift Virtualizationではどのように高可用性を実現してきたのか」
というテーマを取り上げたセッションについてレポートをお届けします。
他の仮想基盤は当然のように具備している高可用性ですが、OpenShift, OpenShift Virtualizationではどうなっているのか、とても分かり易く解説されていたので、よく知らないという方もぜひご覧いただければと思います。
セッション概要
- セッション
High availability strategies for Red Hat OpenShift Virtualization workloads
(リンク先:Red Hat Summit 2026 セッションカタログ) - 概要
-
VMのHAを可能にするMedik8sプロジェクト
コンテナ前提のアーキテクチャに起因する、ノード障害時にVMをHAさせるための課題点 -
OpenShift Virtualizationにおけるノード障害時の自己修復動作
NHC Operatorと3種類のRemediation Operatorによる自律的なノード修復 - 進化したDeschedulerによる実効性のある負荷分散
PSIを組み込むことで可能になった、実際の負荷状況を加味したワークロードの再配置
-
セッション詳細
VMもコンテナ同様にHAさせる!「Medik8sプロジェクト」
セッションを聴いてまず驚いたのが、「VMはコンテナと違い、標準ではノード障害時に自動でHAされない」という事実です。OpenShiftのベースとなるKubernetesでは、当初コンテナの稼働のみを想定しており、VMの稼働、ましてや高可用性は組み込まれていませんでした。通常のコンテナであれば、ノードで障害が発生すると、OpenShiftがそれを検知して別の正常なノードで新しいコンテナをすぐに立ち上げます。しかし、VMの場合は下記の理由によりそう簡単にいきません。
-
ストレージの整合性問題: VMは永続的なディスクを使用しています。ノードが通信不能になっただけで勝手に他で再起動してしまうと、元のノードが実は生きていた場合に二重書き込みが発生し、データが壊れてしまうリスクがあります。
-
確認が必要: 安全に再起動するためには、故障したノードが確実に停止し、ストレージをアンマウントしていることを確認するプロセスが必要であり、それには手動での介入や複雑な設定が必要でした。

そこで、VMをコンテナと同じように、安全かつ自動で再起動させるために始まったのが Medik8s(メディケイツ) プロジェクトです。

ノード障害時の挙動:NHC Operatorと3つのRemediation Operator
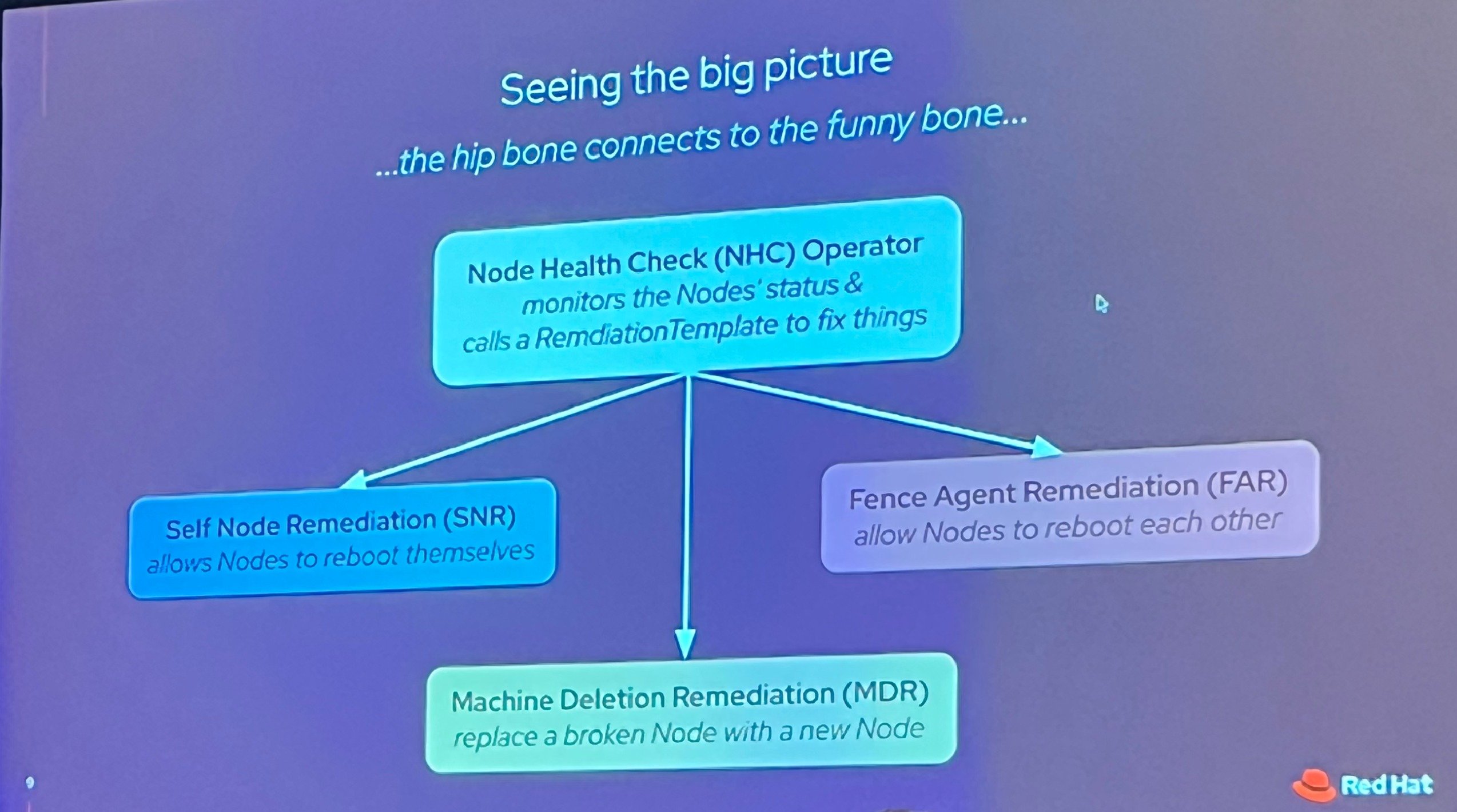
↓SNRの部分では"softdog"にかけた可愛らしいスライドも

Deschedulerによる負荷分散の実現
これを解決する機能として紹介されたのが Descheduler です。
Deschedulerは、ノードの負荷状況を継続的に監視し、状況に応じてワークロードの再配置を行います。
OpenShift VirtualizationではDeschedulerの機能改善が進められており、今回のセッションでは昨年末にGA(General Available)となった「ノードの実負荷に基づいたワークロードの再配置」を自律的に実行する仕組みについて、具体的な設定例を交えて解説されました。
どのような機能か
Deschedulerは稼働中のクラスタの負荷状況を監視し、設定値に基づいてPodやVMを退避することで、スケジューラーによる適切なノードへの再配置を促します。
デフォルトでは利用できないため、別途Operatorを追加する必要があり、下記のように条件や制限を追加することで細かく動作を制御することができます。
PSIを活用した監視と再配置
- 実負荷の検知: PSIは、単なる使用率ではなく、CPUやメモリ、I/Oのリソース待ちによる処理の遅延を計測します。
この機能を活用することにより、見かけの使用率は低くても実際には処理が遅延しているなど、本当に負荷のかかっているノードを特定することができます。 - 条件に基づく再配置: 特定のノードが高負荷だと判断されると、Deschedulerがワークロードの退避をキックし、スケジューラーが空きノードへ再配置(VMの場合はライブマイグレーション)するよう促します。
これにより、予約値上は空きがあるのに実際には重い、といった「サイレントな負荷集中」を解消することができ、壊れてから直すだけでなく、壊れる前に回避するというより高度な可用性が実現されています。
おわりに
今回のセッションは単なる機能説明ではなく、開発の歴史を踏まえた非常に厚みのある内容でした。特にDeschedulerの部分では、より良い機能になるようアップグレードを続ける姿勢や、素晴らしい技術の裏で実体として動いているのが普段使用しているLinuxの機能であるという点に胸が熱くなりました!
モニターに向かっているだけでは経験することのできない、ベンダーの方々から直接話を聞く機会を得ることができたことは、サミットに参加したことの大きな意義のひとつだと感じています。
今後も一層技術の習得に励みつつ、進化を続けるOpenShiftの最新情報もウォッチして、会社やお客様に還元できるよう精進していきたいと思います。
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス

Careersキャリア採用


この記事をシェアする

