Databricks SQLウェアハウスとは?概要と使い方を解説
2025.03.19
- Azure
- Databricks
- クラウド
- データエンジニアリング
Databricks のメニューにあるものの、初見だとどういうものかよくわからないSQLウェアハウス。
そもそもSQLウェアハウスとは何なのか?から具体的な使い方まで解説します。
SQLウェアハウスとは?
SQLウェアハウスは、SQLコマンドを実行する計算リソースです。もとはSQLエンドポイントという名前でしたが、単なるAPIエンドポイント以上のものであり、SQLコマンドを実行するものでもあることからSQLウェアハウスという名称に変更されたそうです。
名前からデータウェアハウス的な何かを想像してしまいますが、あくまでノートブック等で使う通常のクラスターと同じ計算リソースです。通常のクラスターと大きく異なる点は、SQLを実行するためのエンドポイントとしての側面が強いところです。
設定の自由度が少なく課金のベースコストも高い(最小のXXSでも4DBU/時)代わりに、通常のクラスターに比べて起動から実行までの時間が非常に短いという特徴があります。
SQLウェアハウス作成
SQLウェアハウスの作成方法はいたってシンプルです。
メニューの「SQLウェアハウス」→「SQLウェアハウスを作成」で作成できます。
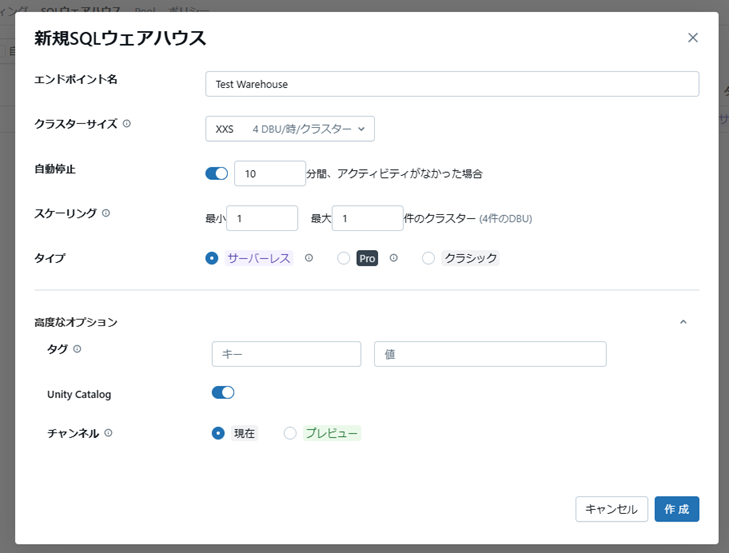
作成画面では以下の項目を設定できます。
- エンドポイント名:SQLウェアハウスの名前。
- クラスターサイズ:計算リソースとなるクラスターのサイズ。XXS~4X-Largeまで指定可能。クラスターサイズが大きいほど処理能力は上がるが、コストも増えるため注意が必要。
- 自動停止:指定時間アイドル状態が続いた場合に停止するかどうか。デフォルトは10分。
- スケーリング:クエリが分散処理されるクラスターの最小数と最大数。
- タイプ:サーバーレス、Pro、クラシックから選択可能。こちらに記載のように、基盤となる計算リソースとサポートされている機能、DBUあたりの料金が異なる。
SQL実行(SQLエディタ)
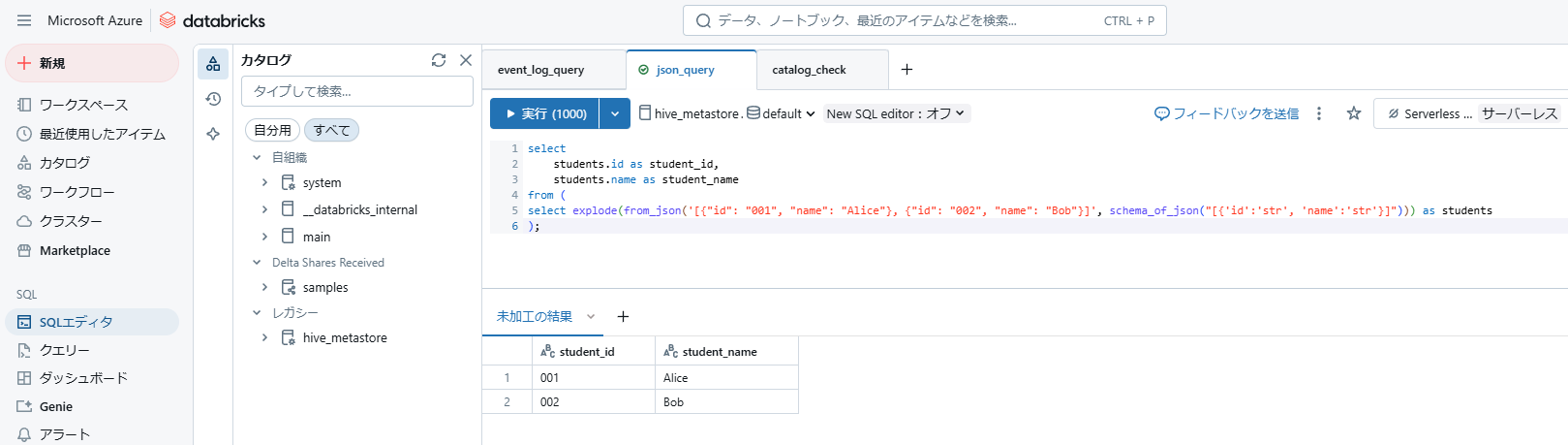
SQLエディタでは、SQLウェアハウスを基盤として任意のSQLを実行することができます。
SQL実行(API)
プログラムからリクエストを送信し、API経由でSQLを実行することが可能です。
以下では Azure Databricks の場合の例を示します。
環境変数の設定部分やサービスプリンシパルの設定に関しては以下の記事の内容をご参照ください。
簡単スタート!Azure Databricksジョブ実行の基本とAPIによる自動化
下記のPythonプログラムは、SQLウェアハウスに対しSQLの実行リクエストを送るものです。
import os
import requests
instance_id = os.environ.get("INSTANCE_ID")
tenant_id = os.environ.get("TENANT_ID")
client_id = os.environ.get("CLIENT_ID")
client_secret = os.environ.get("CLIENT_SECRET")
def get_token():
# Microsoft Entra ID アクセストークンを取得
url = f"https://login.microsoftonline.com/{tenant_id}/oauth2/v2.0/token"
headers = {"Content-Type": "application/x-www-form-urlencoded"}
data = {
"grant_type": "client_credentials",
"scope": "2ff814a6-3304-4ab8-85cb-cd0e6f879c1d/.default" # /.default の前部分は固定IDなので変更しないこと
}
response = requests.post(
url=url,
headers=headers,
auth=(client_id, client_secret),
data=data
)
# Databricks API アクセストークンを取得
url = f"https://{instance_id}/api/2.0/token/create"
headers = {"Authorization": f"Bearer {response.json()['access_token']}"}
json = {
"comment": "no comment",
"lifetime_seconds": 15768000
}
response = requests.post(
url=url,
headers=headers,
json=json
)
token = response.json()["token_value"]
return token
def list_sql_warehouses():
api_version = 'api/2.0'
api_command = 'sql/warehouses'
url = f"https://{instance_id}/{api_version}/{api_command}"
token = get_token()
headers = {"Authorization": f"Bearer {token}"}
response = requests.get(url=url, headers=headers)
print(response.text)
def exec_sql(sql_warehouse_id, sql):
api_version = 'api/2.0'
api_command = 'sql/statements'
url = f"https://{instance_id}/{api_version}/{api_command}"
token = get_token()
headers = {"Authorization": f"Bearer {token}"}
json = {
"warehouse_id": f"{sql_warehouse_id}",
"statement": sql,
"wait_timeout": "50s" # 必要に応じて変更する。デフォルトは10秒
}
response = requests.post(url=url, headers=headers, json=json)
print(response.text)
def main():
sql_warehouse_id = '<SQLウェアハウスID>'
sql = "SELECT * FROM main.default.comments where sender = 'Alice'"
exec_sql(sql_warehouse_id, sql)
if __name__ == "__main__":
main()
list_sql_warehouses()でSQLウェアハウスの一覧を取得できます。
exec_sql()で指定のSQLウェアハウスでSQLを実行します。
なお、上記プログラムはAzure Databricks REST API referenceを参考に実装しています。
sql_warehouse_idは上記のlist_sql_warehouses()を実行した結果、またはメニューの「SQLウェアハウス」→「概要」の名前から確認可能です。
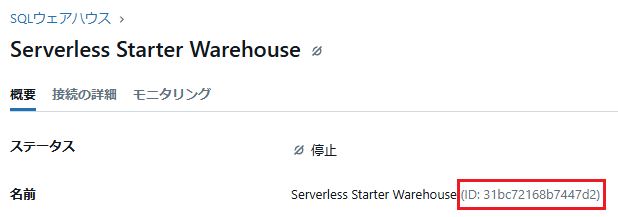
プログラムを実行する際、サービスプリンシパルに対象テーブルの権限がないと権限エラーになってしまうため、必要な権限が付与されているか確認しておく必要があります。
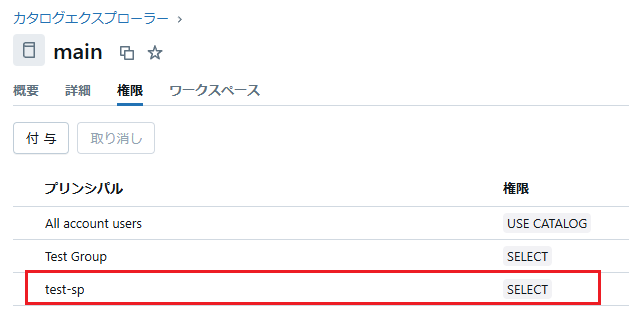
※今回の場合、サービスプリンシパル test-sp にSELECT権限を付与しています。
wait_timeoutに指定した時間内に結果が得られた場合、以下のようなレスポンスが返されます。
{"statement_id":"01eff3e4-1ad6-1b92-b978-a0a9d5793482","status":{"state":"SUCCEEDED"},"manifest":{"format":"JSON_ARRAY","schema":{"column_count":3,"columns":[{"name":"comment","type_text":"STRING","type_name":"STRING","position":0},{"name":"id","type_text":"STRING","type_name":"STRING","position":1},{"name":"sender","type_text":"STRING","type_name":"STRING","position":2}]},"total_chunk_count":1,"chunks":[{"chunk_index":0,"row_offset":0,"row_count":1}],"total_row_count":1,"truncated":false},"result":{"chunk_index":0,"row_offset":0,"row_count":1,"data_array":[["Hello.","C0001","Alice"]]}}
制限時間内に結果を得られなかった場合は、以下のようにSQLステートメントIDと実行ステータスのみが返されます。
{"statement_id":"01eff3e2-710c-1f93-8aa2-c8d49fca9c57","status":{"state":"PENDING"}}
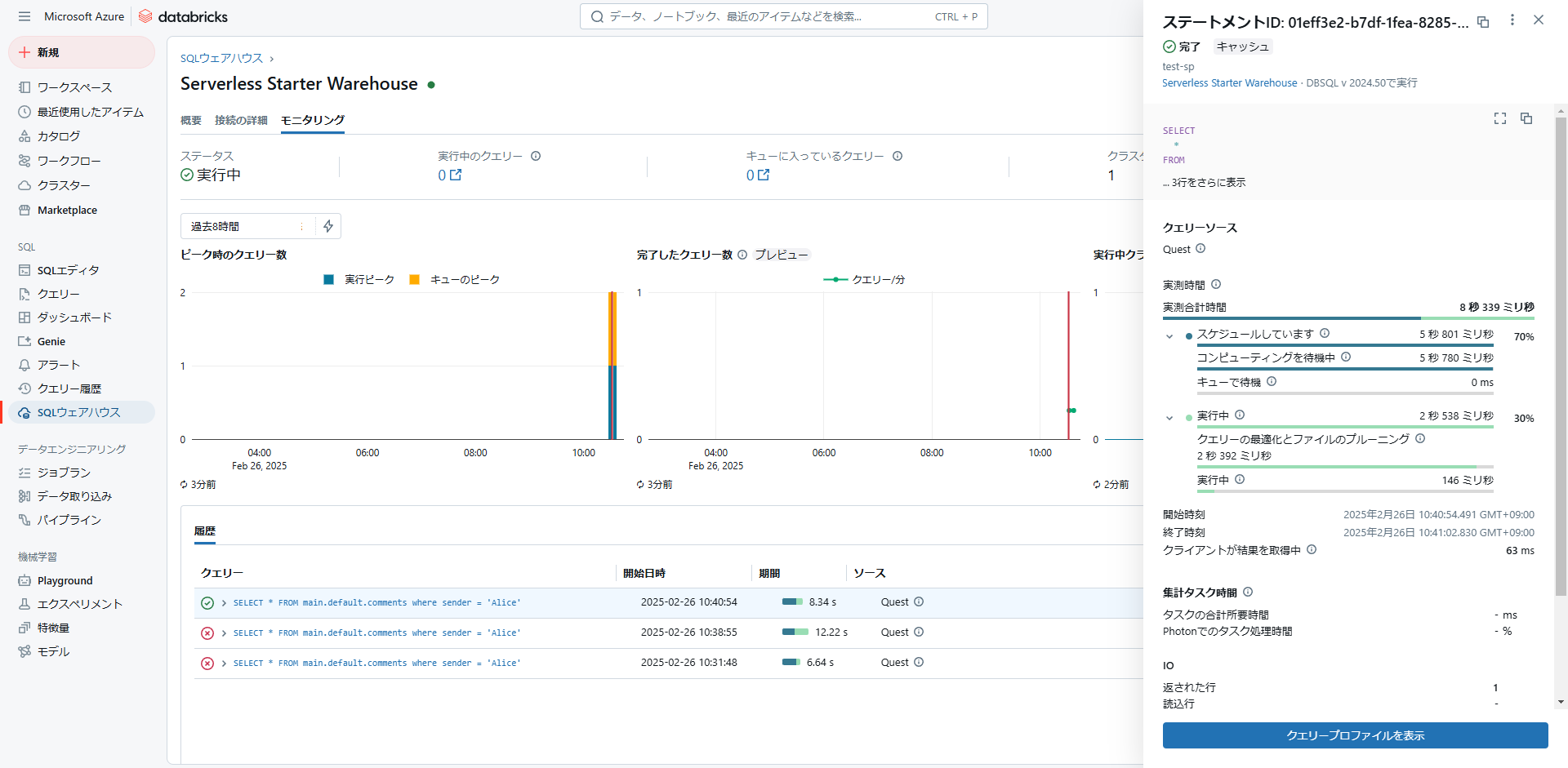
メニューの「SQLウェアハウス」→「モニタリング」からSQLの実行履歴詳細を確認可能です。
外部サービスとの接続
SQLウェアハウスは Tableau や Power BI など、外部サービスと接続して利用することも可能です。
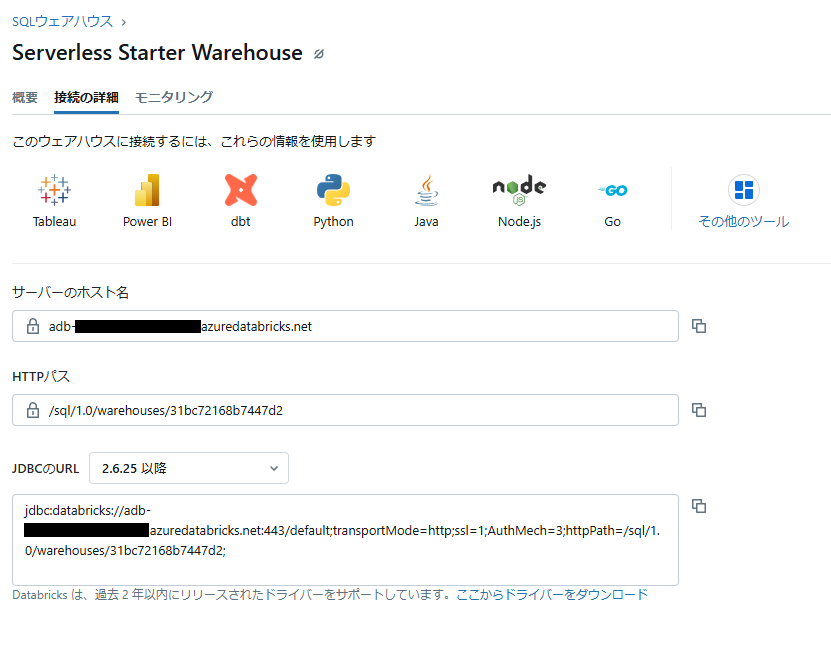
「接続の詳細」タブで表示されている接続情報を用いて、外部サービスと接続することができます。
Databricks SQL Connector for Python
SQL実行(API)で直接リクエストを送る方法をご紹介しましたが、接続の詳細の中に Python もあり、Databricks SQL Connector for Python というライブラリを利用してSQLを実行することもできます。
繰り返し処理と組み合わせたクエリ実行や Unity Catalog ボリューム内のファイル管理、ログ記録などがサポートされているため、プログラムとして本格的に処理を行いたい場合はこちらを利用するのが良さそうです。
まとめ
SQLウェアハウスは計算リソースであり、任意のSQLコマンドを実行することができます。SQLエディタで利用できるほか、APIによりプログラムからSQLコマンドを実行することも可能です。また、外部サービスとの接続機能も提供されており、外部の可視化ツールなどと接続して利用することもできます。
待機時間なく即座にSQLを実行したい場合や、プログラムから任意のタイミングでSQLを実行したい場合など、用途に応じて効果的にSQLウェアハウスを利用してみてください。
参考
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

