簡単スタート!Azure Databricksジョブ実行の基本とAPIによる自動化
2025.02.19
- Azure
- Databricks
- クラウド
- データエンジニアリング
Azure Databricks のジョブ実行方法についてまとめました。
API経由で実行する方法については情報が少なく分かりづらかったため、なかなか苦戦しました...
参考にしていただけますと幸いです。
ノートブック準備
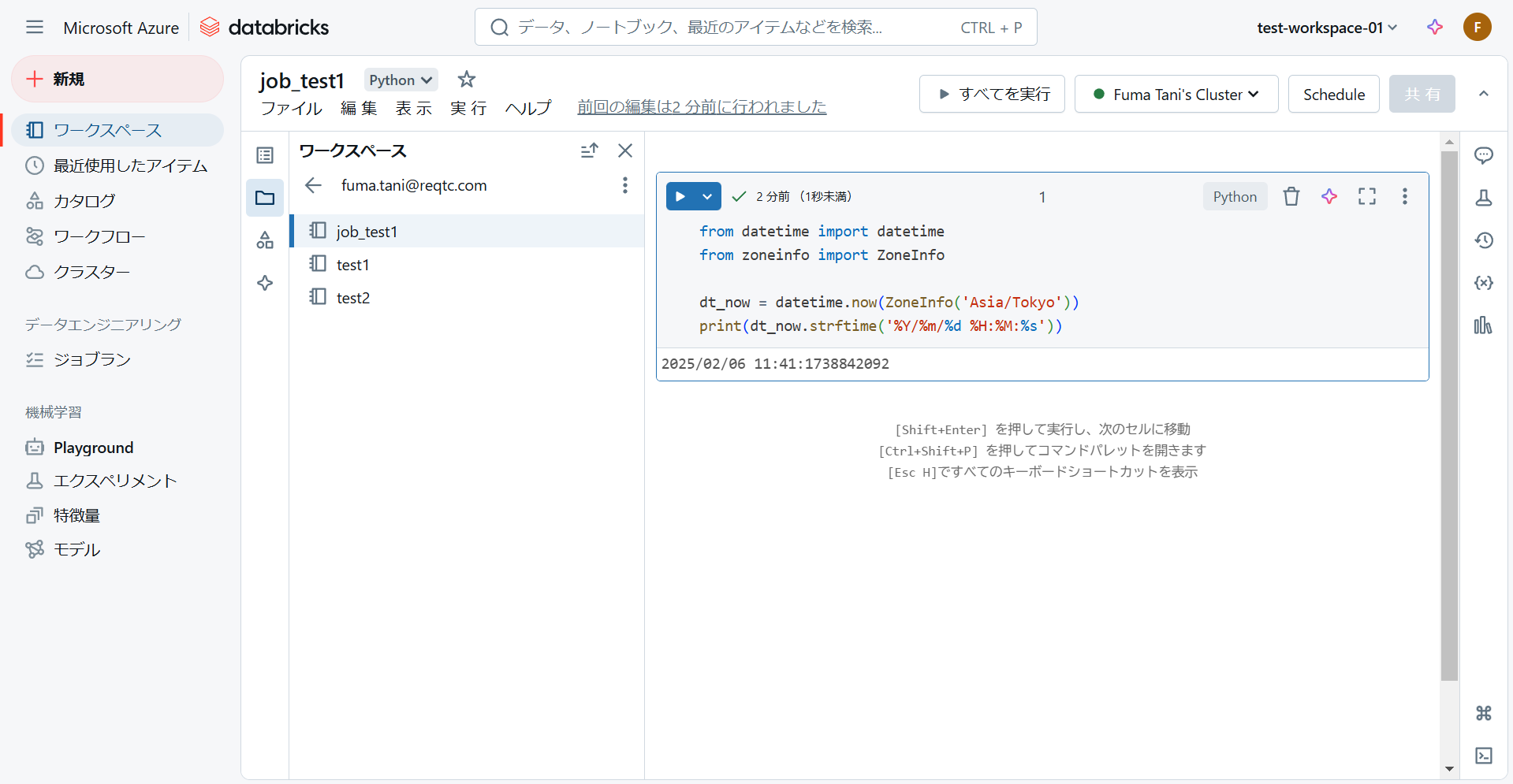
はじめに、ジョブ実行で使用するノートブックを準備しておきます。
今回はテスト用に、現在時刻を表示する以下の Python プログラムを記述したノートブック「job_test1」を作成しました。
from datetime import datetime
from zoneinfo import ZoneInfo
dt_now = datetime.now(ZoneInfo('Asia/Tokyo'))
print(dt_now.strftime('%Y/%m/%d %H:%M:%s'))
ジョブ作成
ノートブックを準備したので、早速ジョブを作っていきます。
まず、メニューから「ワークフロー」を開きます。
「ジョブを作成」をクリックします。
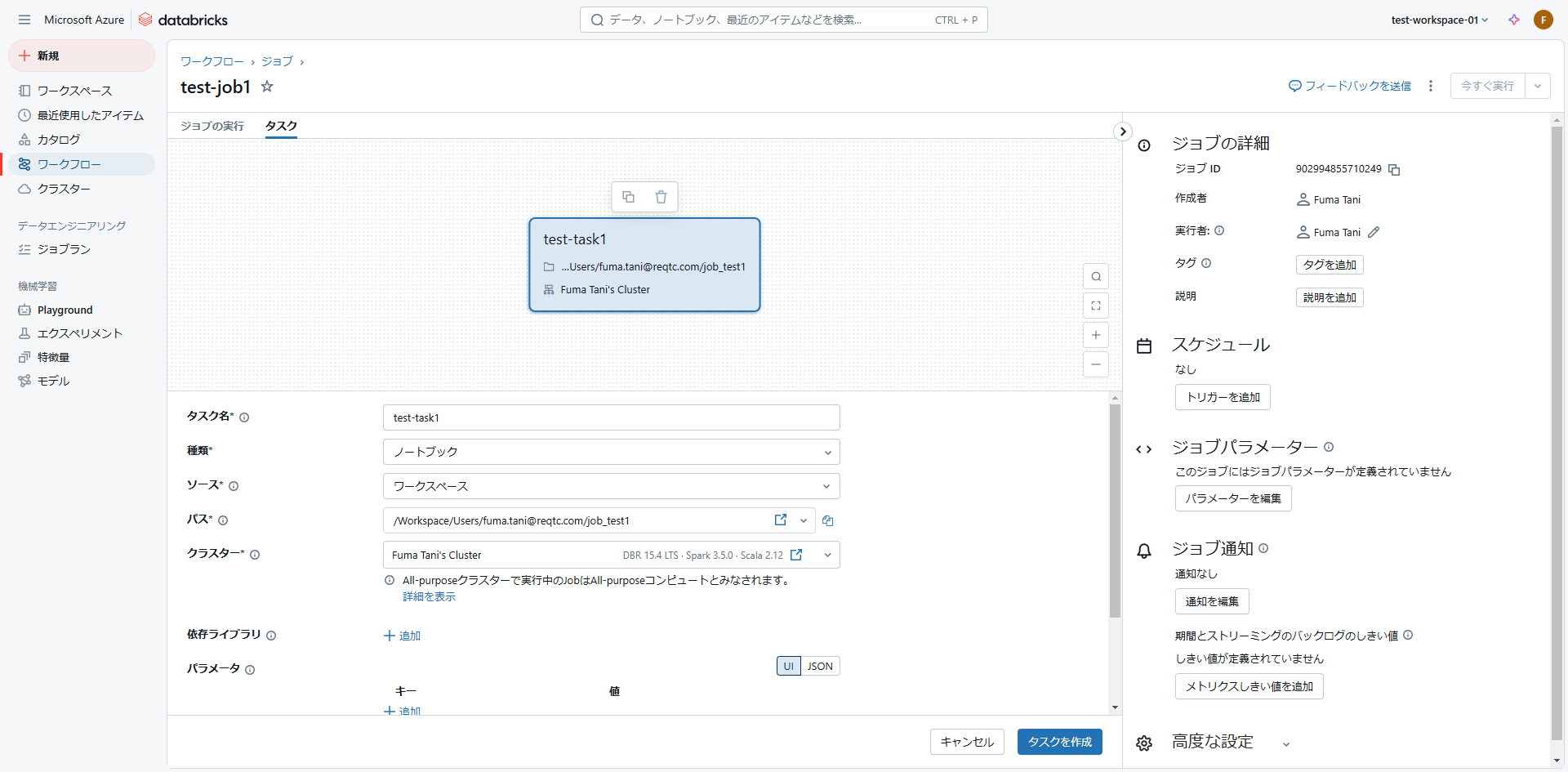
ジョブ作成画面が開くので、下記の項目について設定を行います。
- タスク名:作成するタスク名。
- 種類:ジョブの種類。ノートブックの他にも Python スクリプト、JAR、ジョブなどを選択可能。
- ソース:ノートブックの参照場所。デフォルトは Databricks のワークスペースだが、Git プロバイダーを選択してリモートリポジトリを設定することも可能。
- パス:ノートブックのパス。
- クラスター:ジョブ実行用のクラスター。
他にも実行時のパラメータを設定したり、通知や再試行の設定を行うことが可能です。
設定が完了したら「タスクを作成」をクリックします。
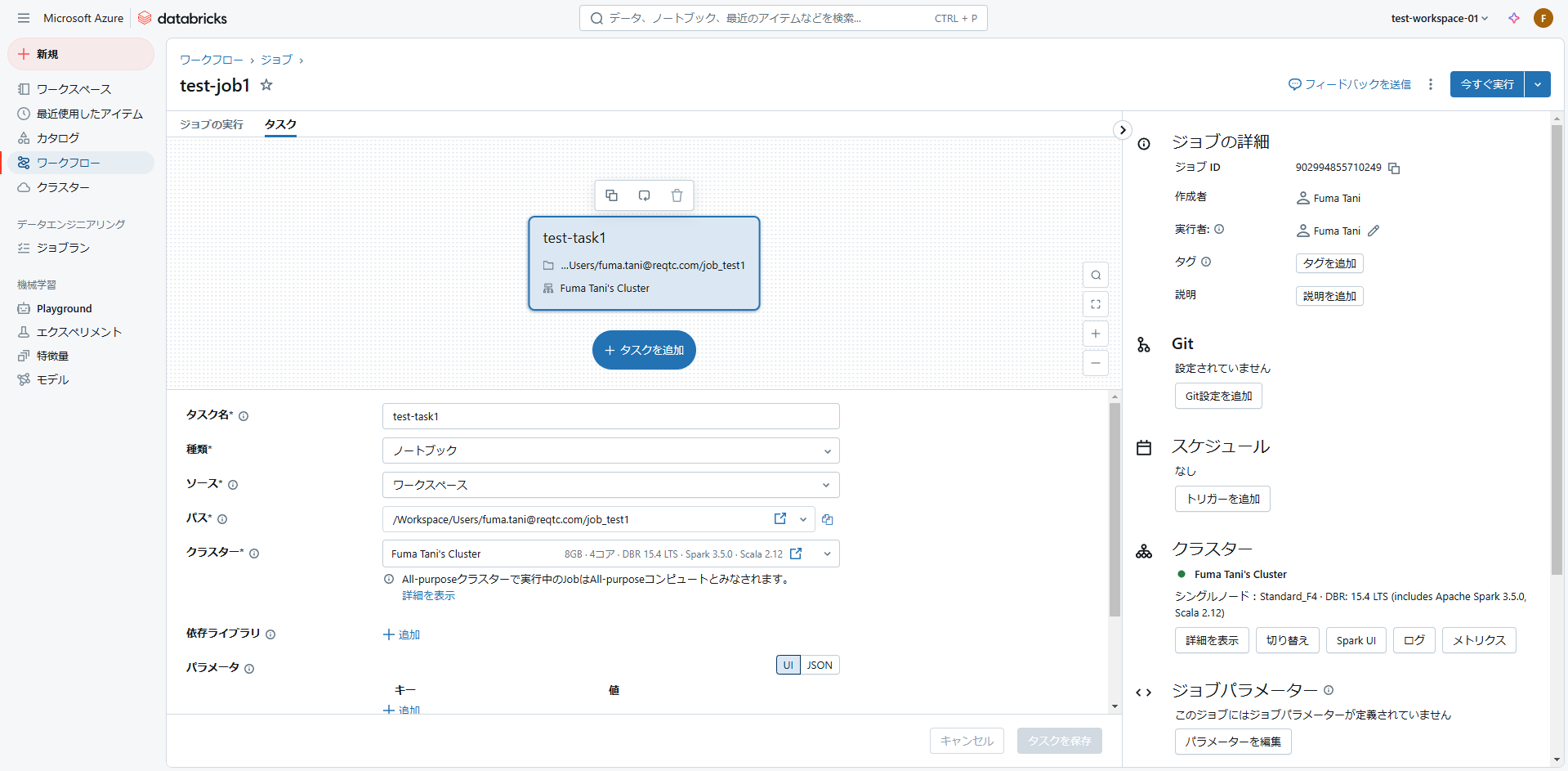
タスクを作成すると「今すぐ実行」ボタンが表示されます。「タスクを追加」で後続タスクを追加することも可能です。
ジョブ実行(直接実行)
「今すぐ実行」ボタンを押せばジョブを実行できます。
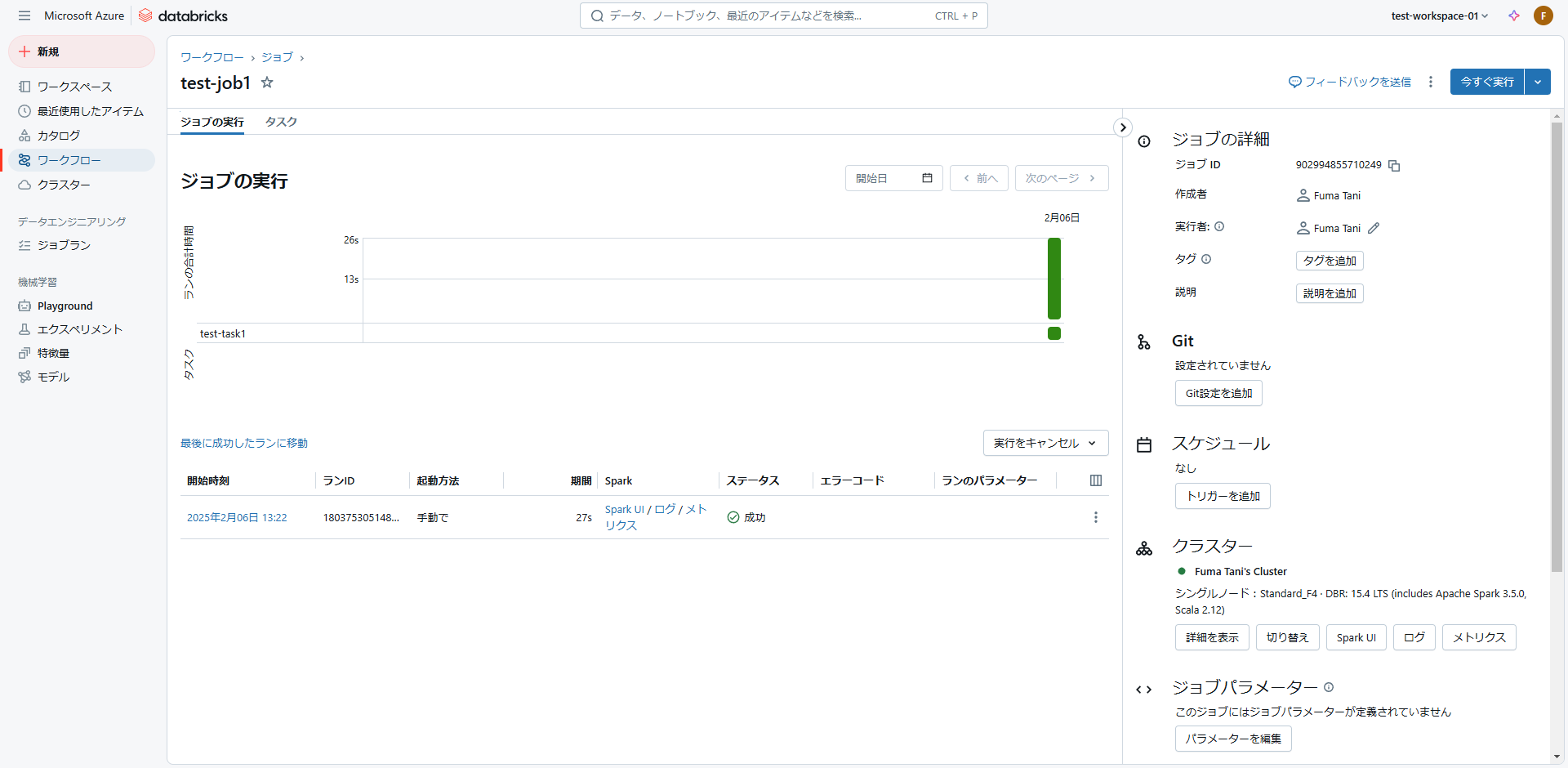
「ジョブの実行」からジョブの実行結果を確認することも可能です。
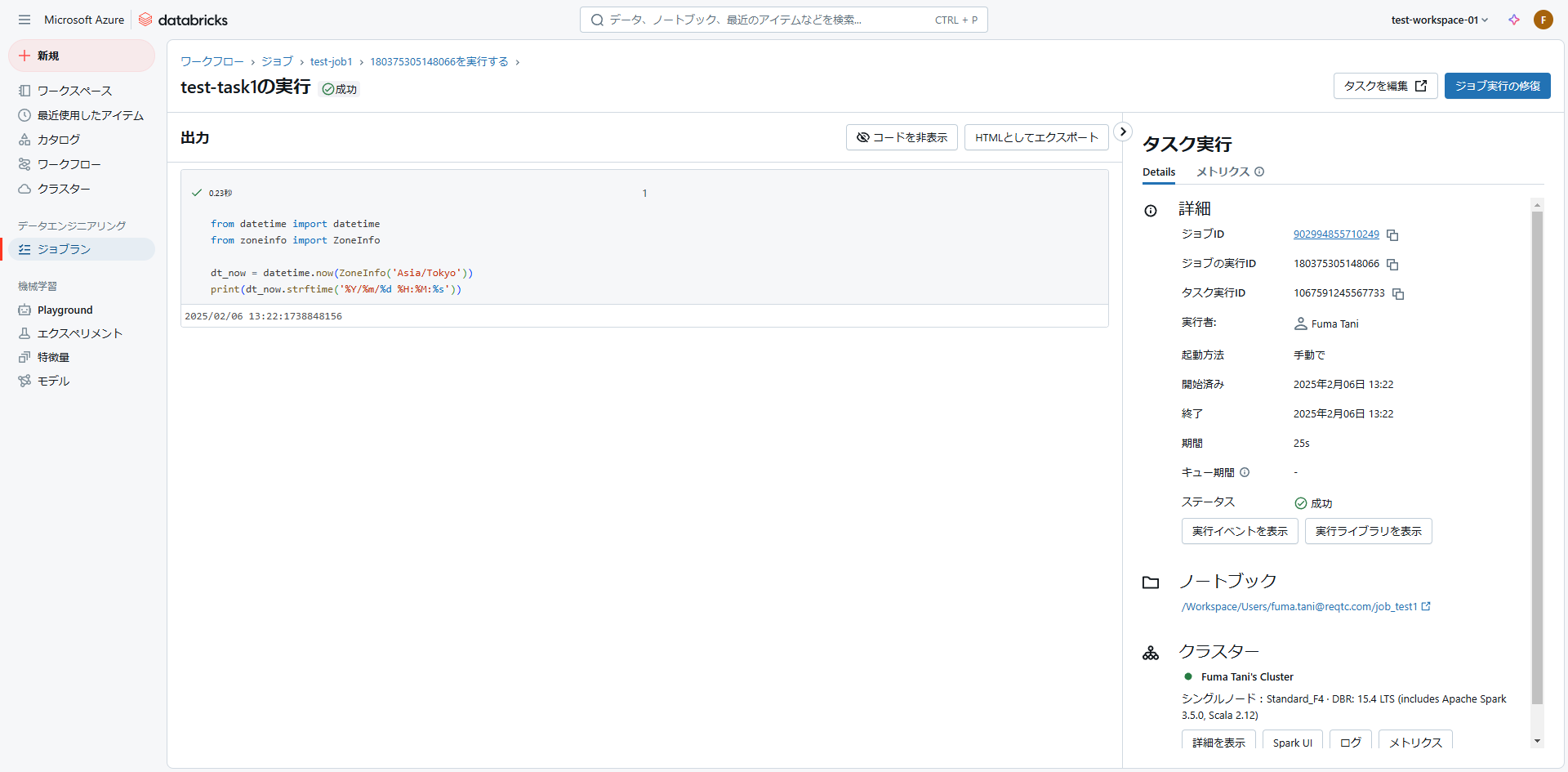
「開始時刻」のリンクをクリックすると、ノートブックの実行結果詳細を確認できます。
ジョブ実行(API利用)
ジョブをAPIでプログラムから実行してみます。
サービスプリンシパル設定
プログラムからAPIを実行する場合、サービスプリンシパルの利用が推奨されています。
※サービスプリンシパルはAWSやGCPのサービスアカウントと同じような、自動化の目的で使用されるbotアカウント。
そのため、まずはサービスプリンシパルの設定を行っていきます。
Azure Portal から「アプリの登録」に移動します。
「新規登録」をクリックします。
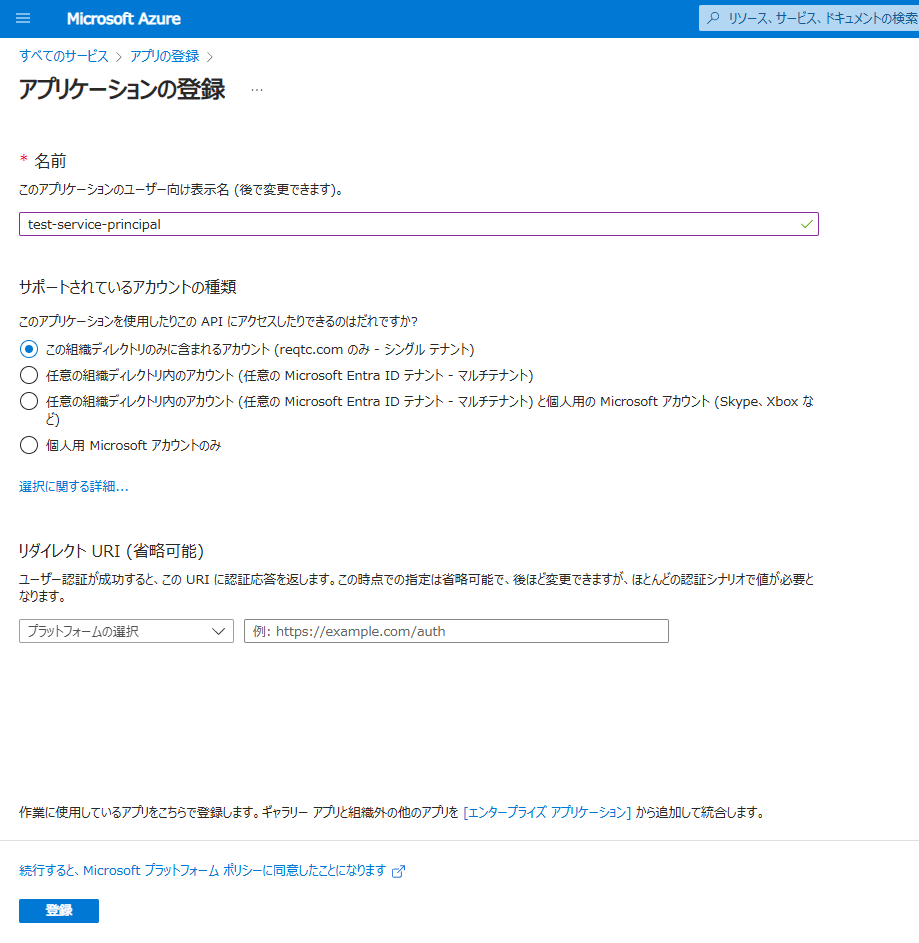
サービスプリンシパルの名前を入力します。
サポートされているアカウントの種類は、サービスアカウントを利用可能なアカウントの範囲についての設定です。組織内のみ利用可能とするため、今回はデフォルトののままとします。
「登録」をクリックします。
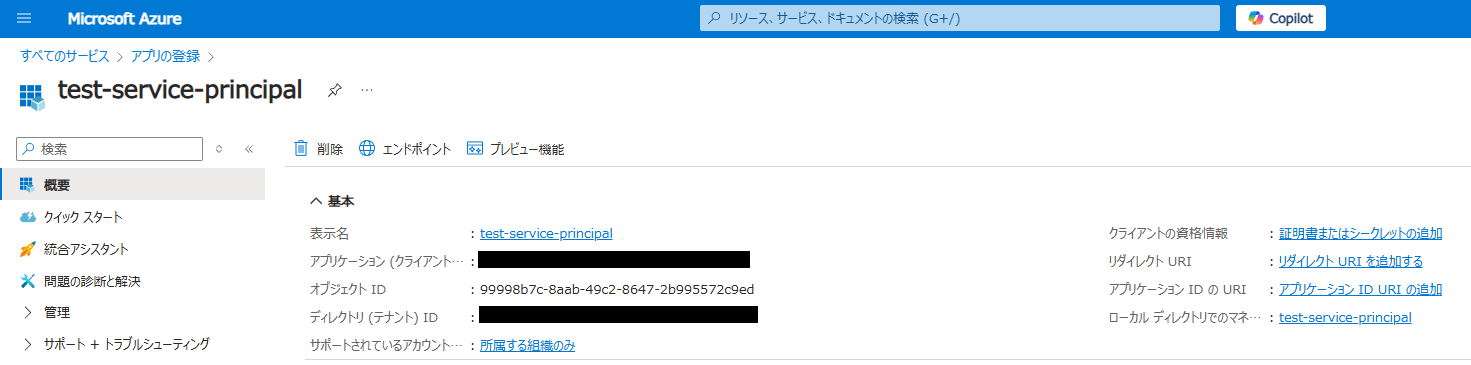
後で使うため、以下の値を控えてきます。
- アプリケーション(クライアント)ID
- ディレクトリ(テナント)ID
「証明書またはシークレットの追加」をクリックします。
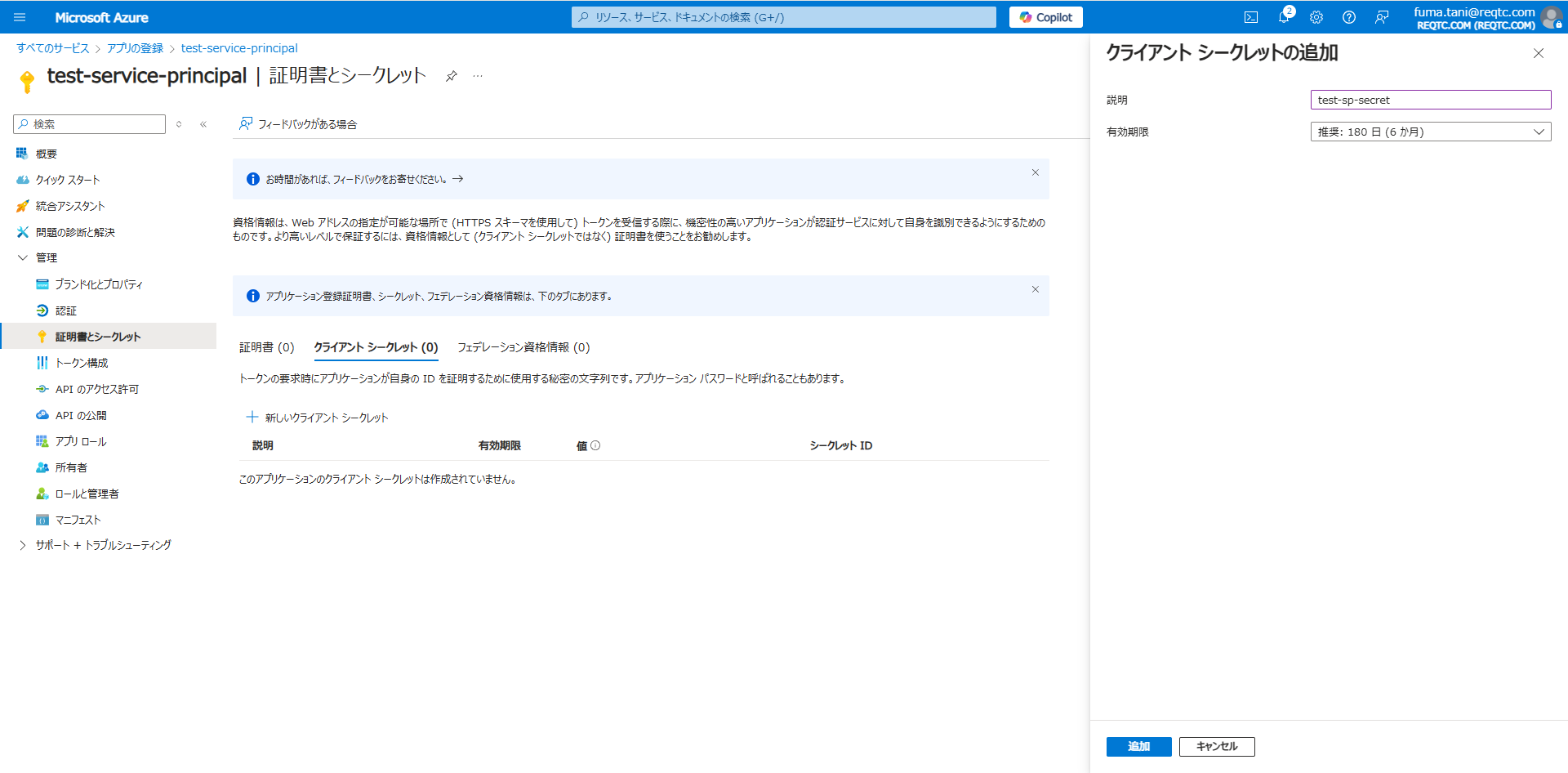
クライアントシークレットの説明を入力し、「追加」をクリックします。

シークレットが作成されました。
後で使うため、クライアントシークレットの値を控えておきます。
Databricks に戻ってワークスペース右上のアカウントアイコンをクリックし、「設定」→「IDとアクセス」を開きます。
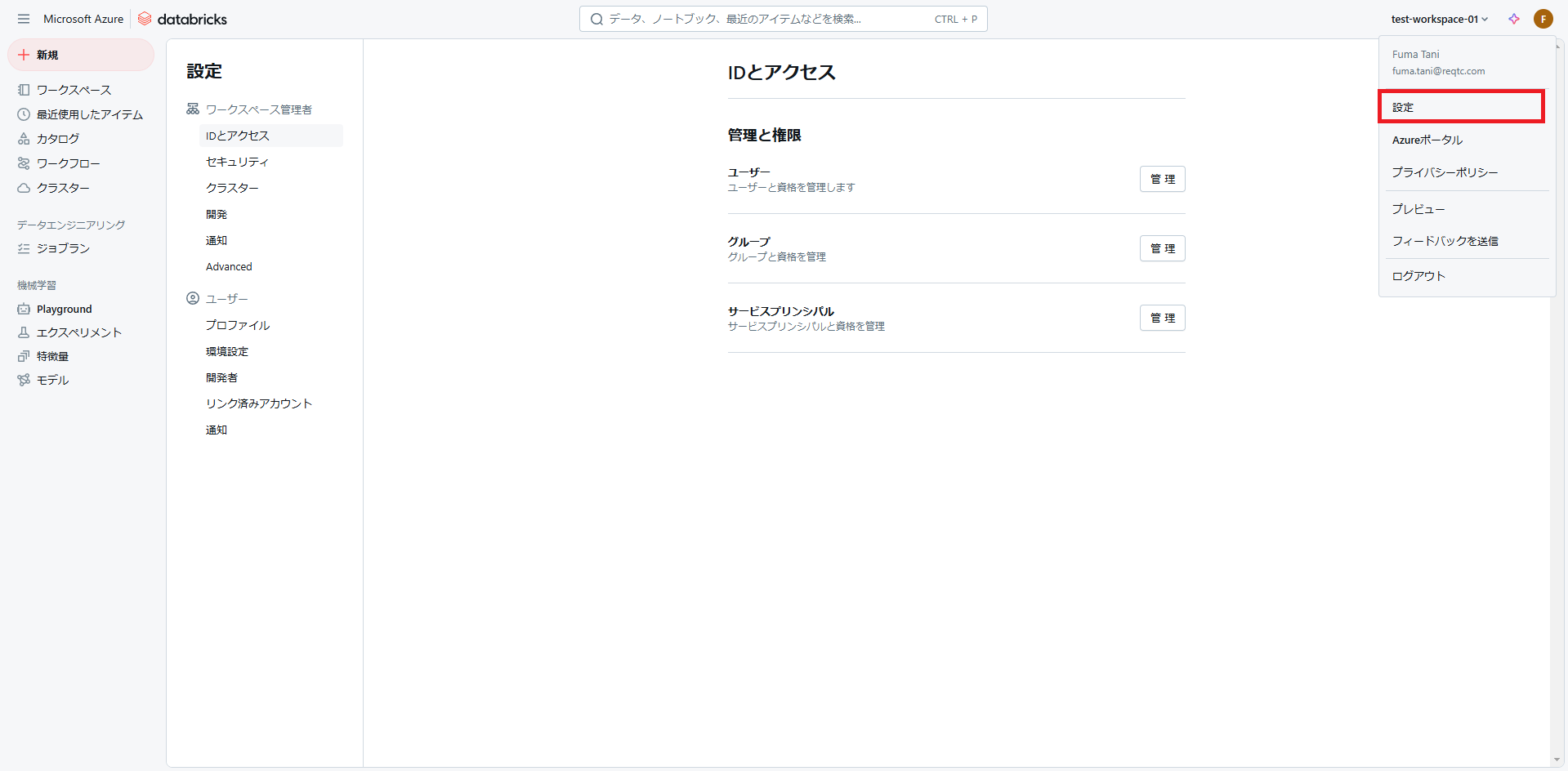
サービスプリンシパルの「管理」をクリックします。
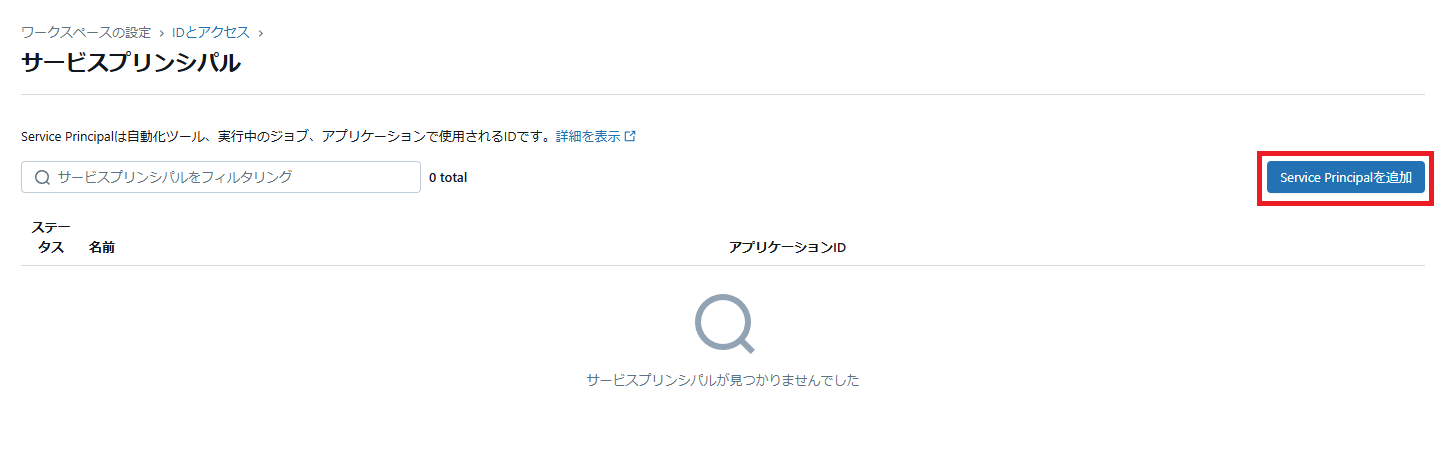
「Service Principalを追加」をクリックします。
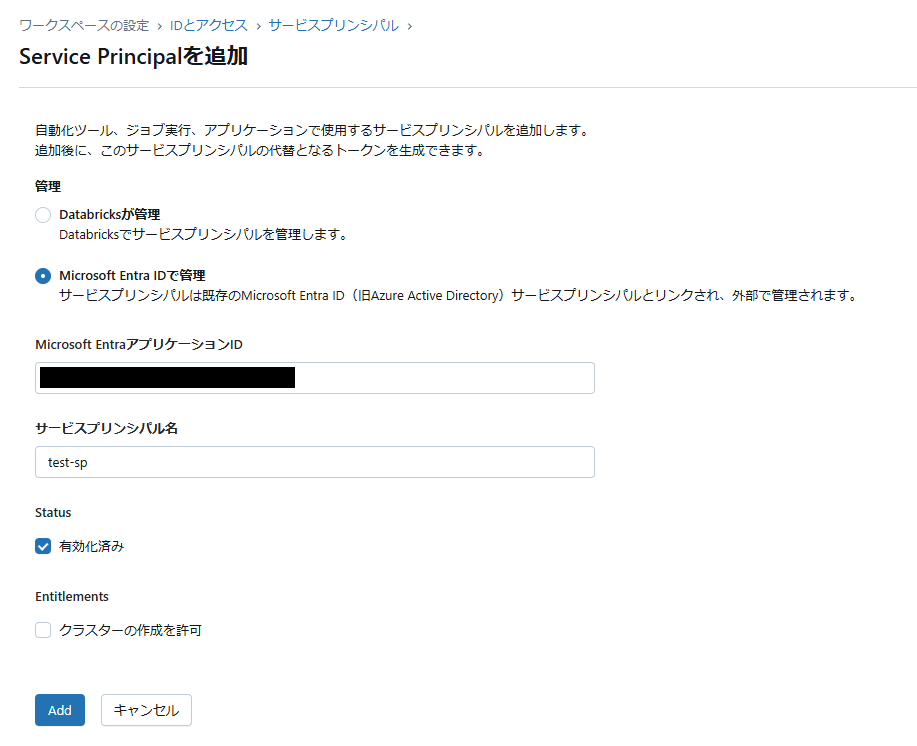
管理は「Microsoft Entra ID で管理」を選択し、先ほど取得した「アプリケーション(クライアント)ID」を指定します。サービスプリンシパル名は任意の名前を指定します。
「Add」をクリックしてサービスプリンシパルを追加します。
以上でサービスプリンシパルの設定は完了です!
ジョブ起動プログラム実行
いよいよジョブの実行をしていきます。
事前準備として、環境変数を以下のように設定しておきます。
INSTANCE_ID=<インスタンスID>
TENANT_ID=<テナントID>
CLIENT_ID=<アプリケーションID>
CLIENT_SECRET=<クライアントシークレット>
<インスタンスID>はワークスペースURLの「https://」以降の部分です。
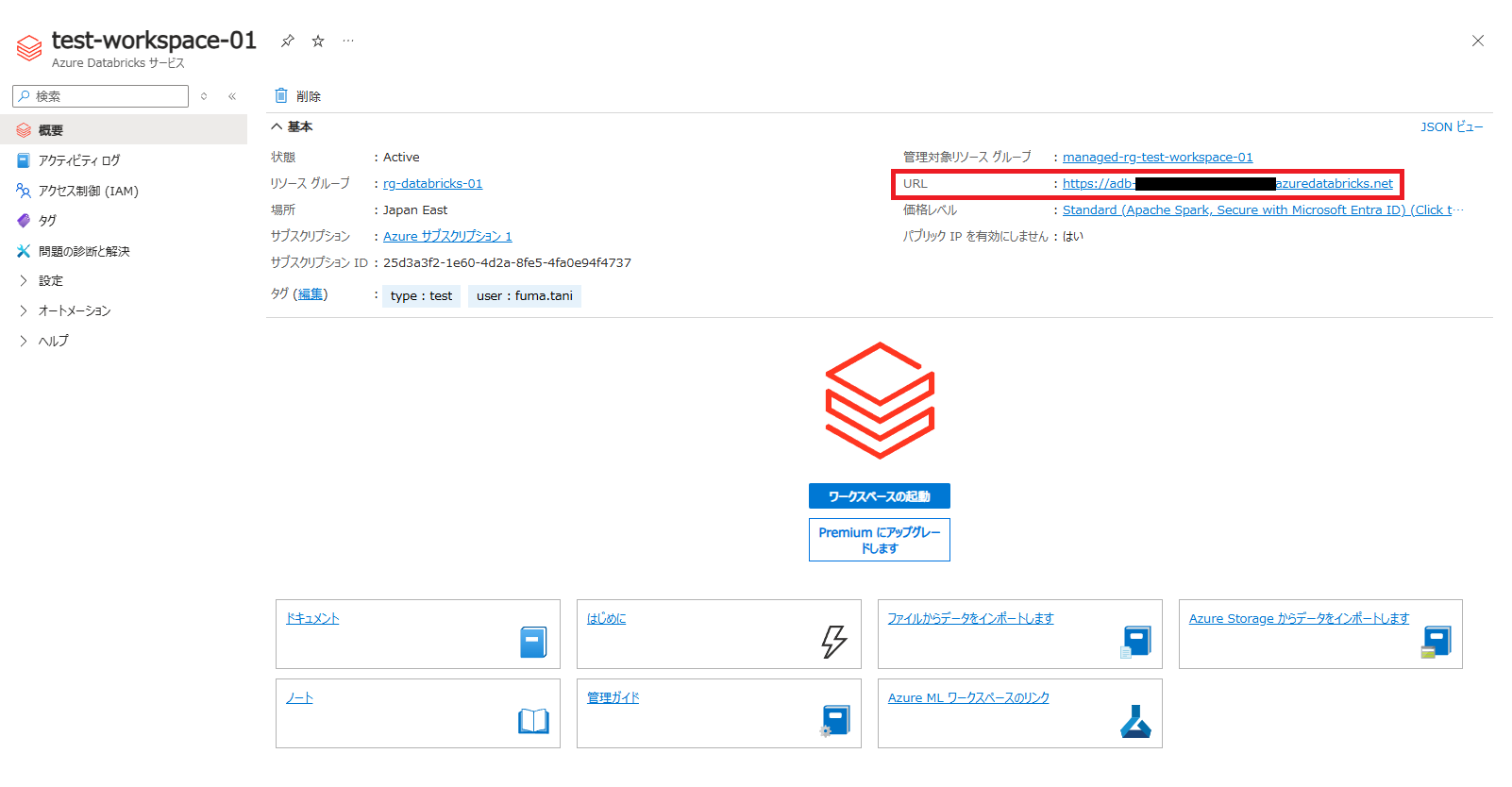
環境変数の設定ができたら、以下の Python プログラムを実行します。
import os
import requests
def get_token():
instance_id = os.environ.get("INSTANCE_ID")
tenant_id = os.environ.get("TENANT_ID")
client_id = os.environ.get("CLIENT_ID")
client_secret = os.environ.get("CLIENT_SECRET")
# Microsoft Entra ID アクセストークンを取得
url = f"https://login.microsoftonline.com/{tenant_id}/oauth2/v2.0/token"
headers = {"Content-Type": "application/x-www-form-urlencoded"}
data = {
"grant_type": "client_credentials",
"scope": "2ff814a6-3304-4ab8-85cb-cd0e6f879c1d/.default" # /.default の前部分は固定IDなので変更しないこと
}
response = requests.post(
url=url,
headers=headers,
auth=(client_id, client_secret),
data=data
)
# Databricks API アクセストークンを取得
url = f"https://{instance_id}/api/2.0/token/create"
headers = {"Authorization": f"Bearer {response.json()['access_token']}"}
json = {
"comment": "no comment",
"lifetime_seconds": 15768000
}
response = requests.post(
url=url,
headers=headers,
json=json
)
token = response.json()["token_value"]
return token
def call_api(job_id):
instance_id = os.environ.get("INSTANCE_ID")
api_version = 'api/2.0'
api_command = 'jobs/run-now'
url = f"https://{instance_id}/{api_version}/{api_command}"
token = get_token()
headers = {"Authorization": f"Bearer {token}"}
params = {"job_id": job_id}
response = requests.post(
url=url,
headers=headers,
params=params
)
print(response.text)
def main():
call_api('<job_id>')
if __name__ == "__main__":
main()
上記を実行すると、(起動していない場合は)クラスターが起動し、対象ジョブが実行されます。
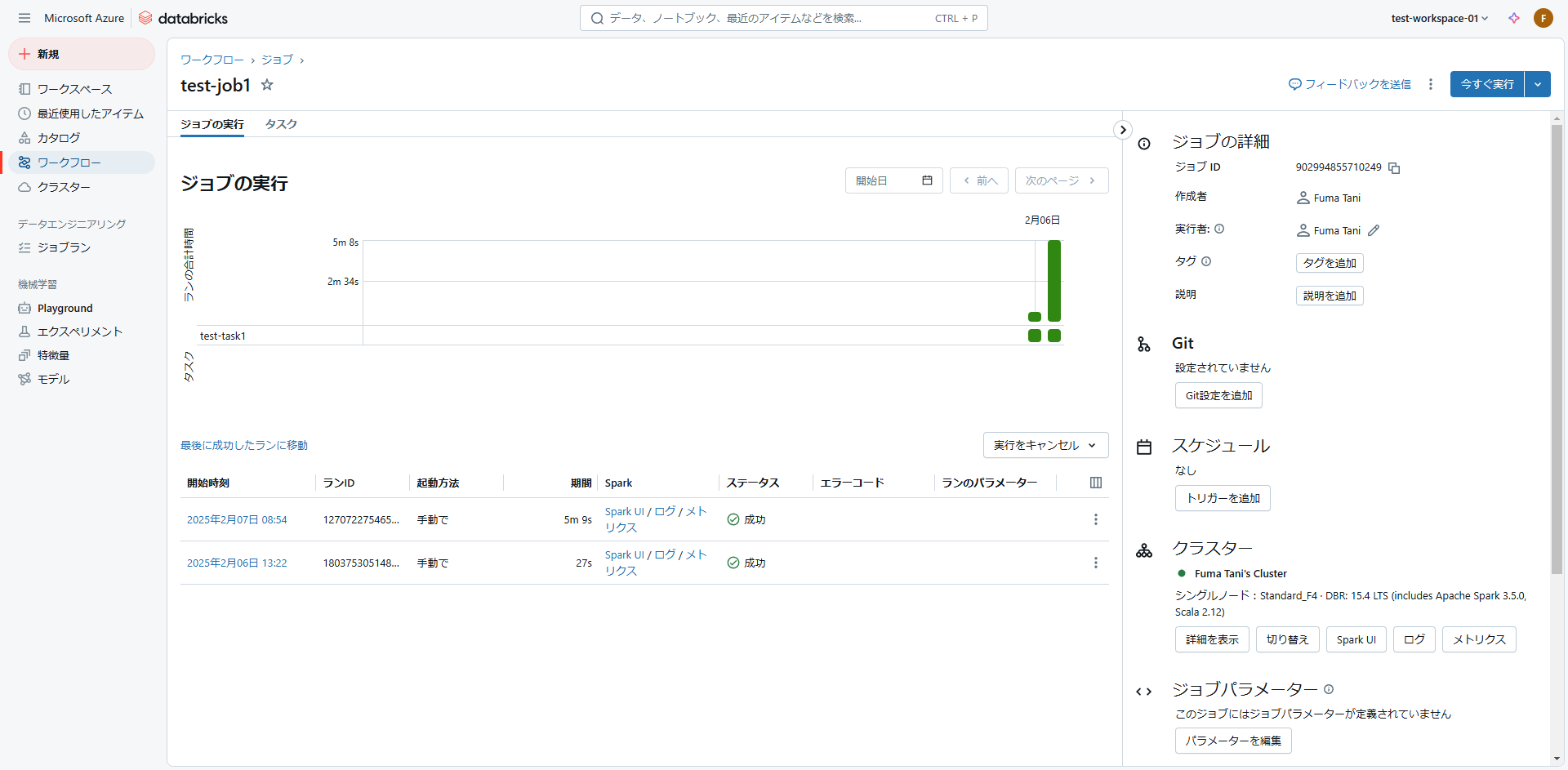
実行履歴からも、確かにジョブが実行されたことを確認できました!
※クラスターの起動から始まったため、最初よりも実行時間が長くなっています
さいごに
Azure Databricks は Azure 上ですぐに使い始められるため便利ですが、APIを利用する場合など通常の Databricks と仕様が異なる部分があるため注意が必要です。
Azure Databricks では記事中で行ったようにサービスプリンシパルを Microsoft Entra ID と連携させて使う必要があり、APIを利用する場合は「Microsoft Entra ID のアクセストークンを取得してから Databricks API 用のアクセストークンを取得する」という2段階の処理が必要になります。
参考記事
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

