文字化けについて
2023.10.17
- Oracle DB
Windowsで作成したテキストファイルを、Linuxで読み込んだら読めない漢字の羅列になってしまったり、どこの言語かわからない文字の羅列になってしまったことありませんか。
こんにちは始めまして、R.K です。
普段はデータベースエンジニアをやっています。
今回は、Oracle Databaseでも起こる「文字化け」と呼ばれる現象について話していきたいと思います。
そもそも文字化けとは
コンピュータ上で文字を表示する際に、正しく表示されなくなってしまい文章として読めなくなってしまう現象のことを言います。
よく起こる事例では、本コラムはじめでも例に挙げた「Windowsで作成したテキストファイルをLinuxで読み込む」など「別プラットフォームでファイルを読み込む」場合が多いと思います。
いくつか原因は上げられますが、一般的なものは「書き込みした時と読み込みをした時で文字コードが違う」というものです。
例:実際に文字化けした状態の図(サクラエディタで疑似的に再現)
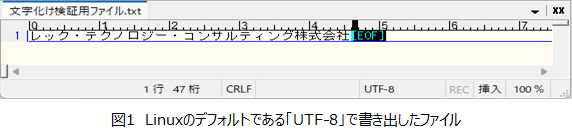
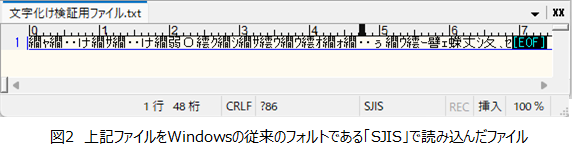
では、ここからは文字コードの違いで「文字化け」が起きる原因について探っていきたいと思います。
その前に、「文字コード」ってなに?
本題に入るためには「文字コードってそもそも何さ?」ってことがわかっていないと深奥には向かえませんので、軽く「文字コード」について語りたいと思います。
前提として、コンピュータは「0」と「1」の「二進法」の世界で生きているので、「文字」をそのままでは理解できません。
なので、コンピュータに「文字」を「0」と「1」の2つの数字で置き換えて教え込んでいます。
画面に表示するときはその「1」と「0」をわざわざ「文字」に再変換してもらうことで、私たちはコンピュータで文字を扱っています。
あまたとある全世界の文字を「0」と「1」で表すには、「0」と「1」の数列によって文字を一意に識別する必要があります。
この「0」と「1」の数例と「文字」の一意の組み合わせの識別番号の一覧が
「文字コード」
と呼ばれるものです
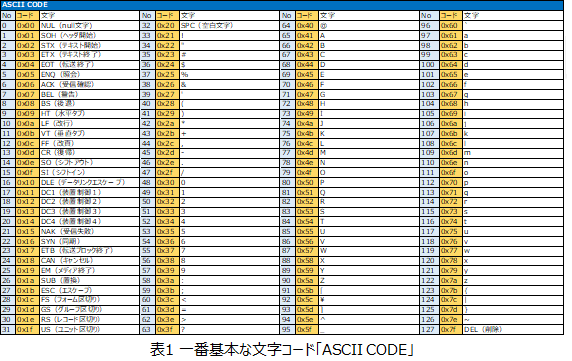
上記は基本となる文字コード「ASCII CODE(アスキーコード)」です。アメリカでタイプライターを基に1963年に制定されました。
文字コードは1~6Byteで構成され、16進数で表されることが多いです。上記のアスキーコードは1Byte(=8bit=0xFF)で表現され、127個の文字が制定されています。
「0x00」~「0x20」は「制御文字(コード)」と呼ばれ、「改行」「文字列の終点(ファイル終端)」「タブ」などを表します。この辺にタイプライター仕様を引きずっているのが見えますね。
自社の英語表記をアスキーコードに沿って文字コードに変換すると以下のようになります。(説明の都合で全て小文字)

こうやって、コンピュータは文字を理解しています。
文字コードは国ごとに作成していたり、国内でも複数の団体によって独自に作成されてきた歴史があり、現行でも複数の文字コードが使用されています。
日本国内で主に使われているのは主に以下のものになりますが、最近のデファクトスタンダードは「UTF-8」になります。

文字化けとは
文字コードについてで長くなりましたが、ようやく、本題の「文字化け」について潜っていこうと思います。
「書き込みした時と読み込みをした時で文字コードが違う」と「文字化け」が起こると前述しましたが、なぜ、文字コードが違うと文字が化けてしまうのか。
それは、文字コードごとに文字に割り振った「識別番号」が違うからです。
例として「レック」という文字を前述3つの文字コードで表すと以下のようになります。
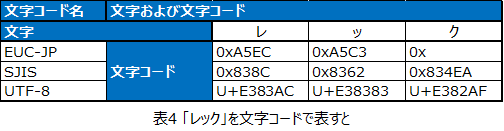
※「UTF-8」の頭文字「U+」は「Unicode」であることを示しています。
テキストファイルにはこの文字コードが保存され、実際の文字は保存されておりません。これをエンコードといいます。
保存したテキストファイルを開き画面に表示する際にはこの文字コードを文字に戻す動作を行います。これをデコードといいます。
このデコード時に、保存時に指定した文字コードでエンコードされた「識別番号」を、開いた時に指定した文字コードで「デコード」した結果、「文字化け」が発生します。
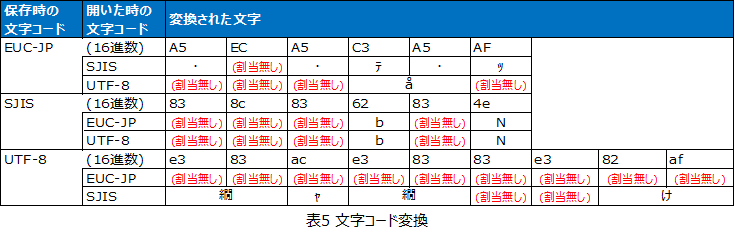
上記のように、「指定した文字コードで表示可能な文字に勝手に置き換えて表示した」結果、「文字化け」という現象になります。
「割当無し」は、その文字コードではその「認識番号」に文字が割り当てられてないという意味で、エディタによって表示され方が違うと思います。
サクラエディタの場合は「半角中黒」になります。(エラーが発生しないようにここには実文字は記載はしません。)
余談ですが、半角英数、半角記号は文字化けしないことが多いです。
これはほとんどの文字コードが「アスキコード」との互換性を持つためで、1バイト文字は文字化けせずに表示されます。
プログラム言語ではコメント文なども英語で記載されることが多いのはこのためで、意図しないバグを発生させずほかのプラットフォームでも互換性を持たせるためでもあります。
日本語などの「全角文字(2バイト以上の文字)」はレガシーシステムでのコードでは回避されてましたが、Unicodeの普及と標準化でそこまで気にしなくても問題なくなってきます。
(レガシーシステムと新システムで互換性をとる場合には注意が必要です。)
さらに余談ですが、「UTF-8」で保存したファイルと「SJIS」「EUC-JP」で保存した場合、ファイルサイズが「UTF-8」のほうが大きくなることがあります。
これは先の表でもある通り、日本語が「SJIS」「EUC-JP」は2バイト(ものによっては1バイト)、「UTF-8」では3バイトでエンコードされるためで、文字数が増えるほど顕著に現れます。
最後に
この話題は実は某SNSで「ダメ文字」というものを知った時に、個人的に調べて理解した内容になります。そちらは蛇足になるので今回は省かせていただきますが、調べてみると面白いかもです。
最近は文字化けも少なくなってきましたが、TeratermとOS側の設定不備のためにターミナルが文字化けすることも間々あるので、今でも注意が必要ですね。
以上、R.K でした。
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス

Careersキャリア採用


この記事をシェアする

