【Google Cloud Next '26 in Las Vegas現地参加レポート】終わりのないデータ移行とETL構築からの脱却〜Icebergとオープン・レイクハウスが導く「データは動かさない」戦略
2026.04.30
- GCP
- インフラ
- データエンジニアリング
1. はじめに
データエンジニアリング部のT.Sです。
本日は、先週開催されたGoogle Cloud Next '26 in Las Vegasと2週間前に開催されたIceberg Summitの内容を踏まえ、現代のビジネス現場が抱えるデータ基盤構築のジレンマについて整理を行います。
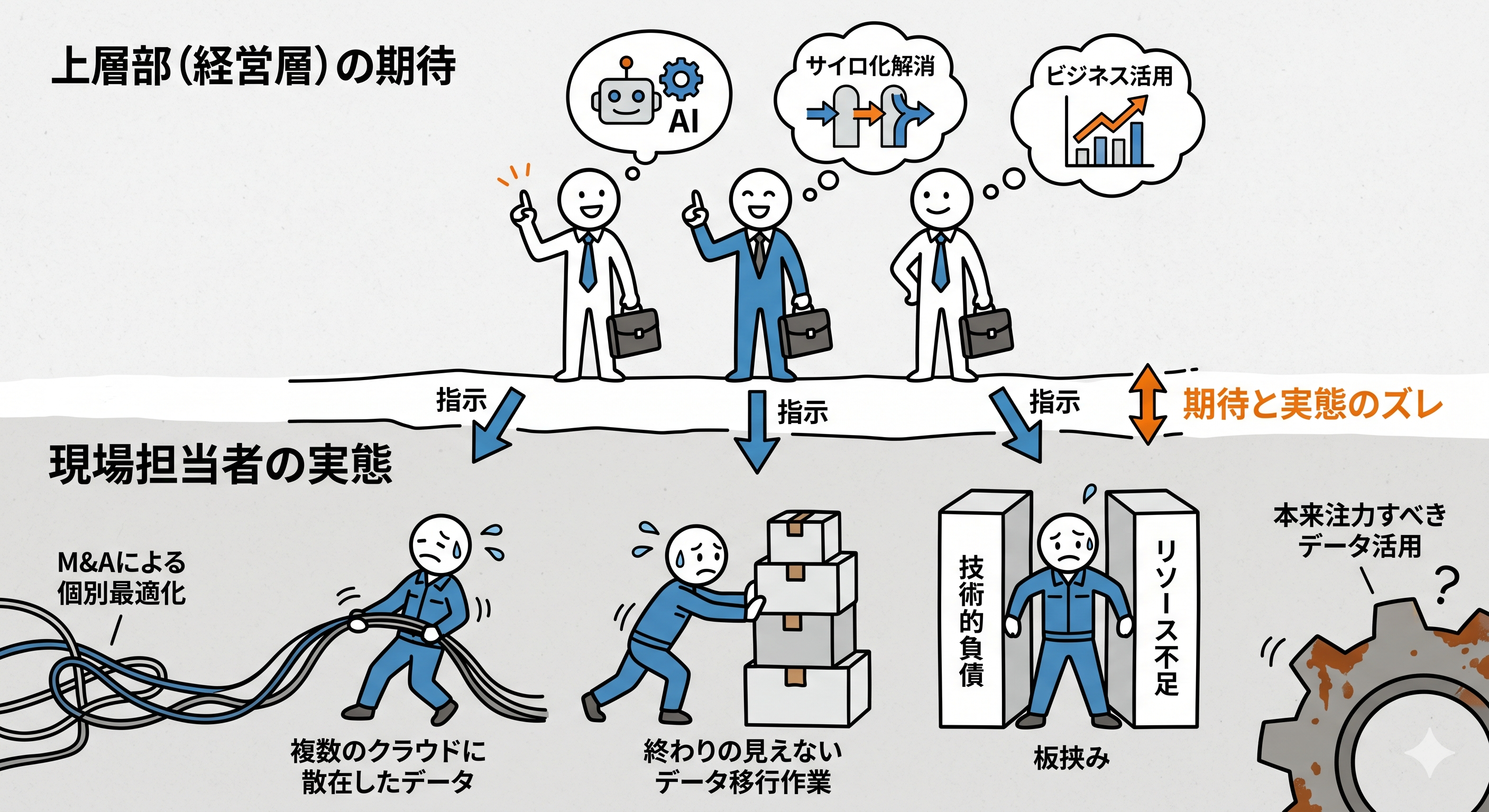
まず、現在のエンタープライズITの現場において、経営層の期待と現場の実態には少なからずズレが生じていることが数々のセッションから感じ取ることができました。
上層部からは「サイロ化を解消し、AIを活用してビジネスに役立てなさい」という指示が下る一方で、現場の担当者は、M&Aや部門ごとの個別最適化によって複数のクラウドに散在したデータを統合するための、終わりの見えないデータ移行作業に追われています。
技術的負債とリソース不足の板挟みになり、本来注力すべきデータ活用そのものに手が回らないというのが実情です。
本記事では、そのような課題に対しての1つの解答として今注目されている、「オープン・レイクハウス」という概念を活用し、新時代のデータアーキテクチャとはどのような姿なのかを解き明かしてきます。
2. セッション・ハイライト:最前線の現場では何が起きているのか
今回分析対象とするセッションでは、Apache Icebergの進化と、それをエンタープライズ規模で活用するGoogle Cloudのソリューションについて、以下のような実例が語られました。
Iceberg Summit
★パネルディスカッション:Engineering the Global Lakehouse: Architecting for Interoperability at Cloud Scale
-
Apache Icebergは、特定のエンジンに依存せず、あらゆるエンジンと相互運用できる「オープンなデータ形式」を実現しました。
-
データは1つだけで済み、データのコピーを減らすことができます。
-
エンタープライズ企業は、Icebergをペタバイト規模のストリーミングや削除処理といった過酷な要件で利用しています。
-
顧客の関心は「Icebergは使えるか」から「Icebergを使っていかに素早くインサイトを得るか」へ移行しています。
-
カタログでUDF(ユーザー定義関数)を定義し共有するなど、相互運用可能なガバナンスへの取り組みが進んでいます。
★Keynote
- Icebergコミュニティでは、AIやストリーミングの要件に対応するためV4の開発が進められています。
- ストリーミング時のメタデータ負荷を軽減するため、「ルート・マニフェスト」という新しい階層の導入が議論されています。
-
AIやLLMのユースケースで増加する数万列の「ワイドテーブル」や、画像・動画などの非構造化データに対応するため、カラム(列)レベルでの追加や更新を別ファイルとして保持する提案が進行中です。
Google Cloud Next
★セッション:Modernizing your data foundation with an AI-ready data lakehouse
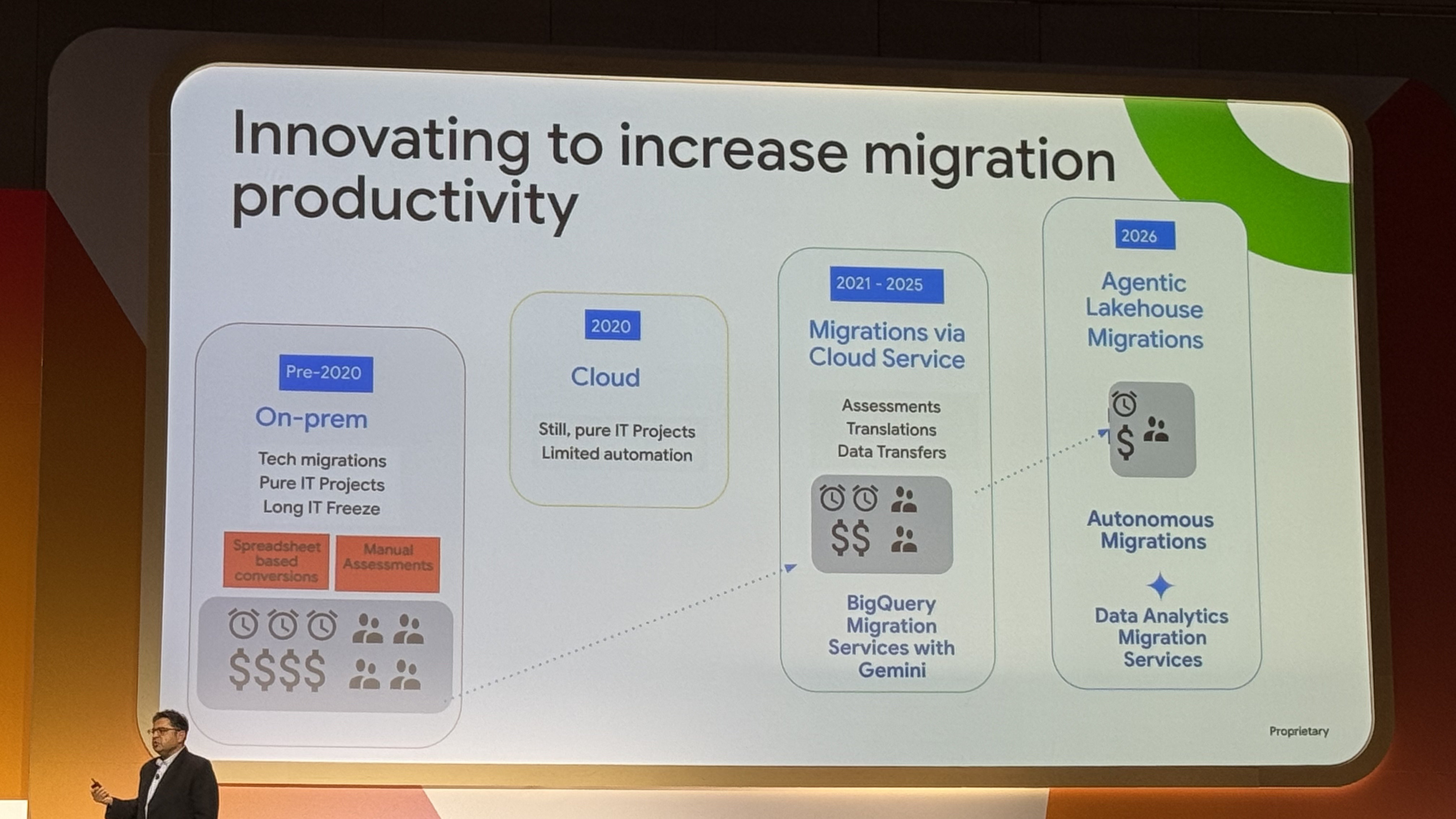
- Google Cloudは、Icebergのようなオープンフォーマットを利用し、マルチクラウド接続をサポートする「AI対応データレイクハウス」を提供しています。
-
自律的に動作する「エージェント型AI」が機能するためには、ビジネスの文脈(ナレッジカタログ)の統合が不可欠です。
-
移行の負担を下げるため、AIを活用してClouderaやAWS環境の自動アセスメントや、精度の高い自動SQL変換を行うサービスが提供されています。
-
KeyBank社の事例では、Google Cloudのデータインフラによって技術的な課題が解決され、現在は銀行員が顧客と接する時間の最大化など、ビジネスプロセスの改善に注力できていることが語られました。
★セッション:Multicloud: Data without borders

- 「CrossCloud Lakehouse」は、データの移動を伴わずに他クラウドのデータへ直接アクセスできる「ゼロコピー・アクセス」を提供します。
- データを物理的に移動させると移行元の場所に依存している下流システムをすべて作り直すコストが発生するという課題が指摘されました。
- 広告代理店グループのWPP社は、M&Aによって複数のクラウドにデータが散在していましたが、この仕組みを利用してデータを元の場所に置いたまま統合することに成功しました。
-
Iceberg REST Catalogによるフェデレーション(連携)と、Googleの「Cross-Cloud Interconnect(CCI)」による転送コスト削減によって、クロスクラウド分析が経済的に実行できます。
★セッション:Unified Iceberg: Open standards, native performance
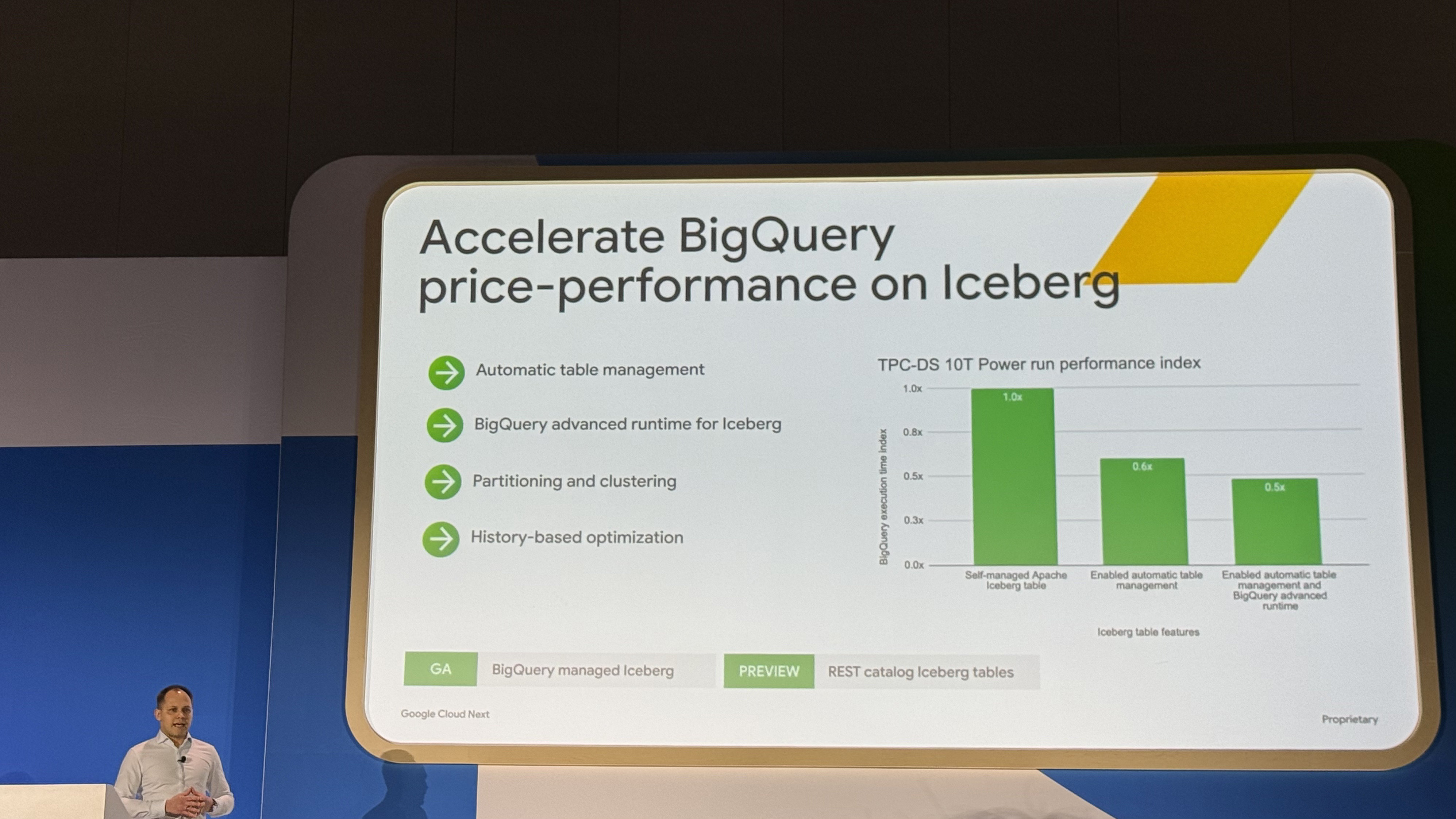
- Iceberg REST Catalogを用いることで、BigQueryとSparkなどの異なるエンジン間で、単一のデータに対する読み書きの完全な相互運用性が実現されました。
- Global Payments社は買収によってクラウドが分散していましたが、フェデレーテッド・カタログ(統合カタログ)を活用してデータを統合しました。
- 同社はAIプロジェクトにおいて、AWSにあるデータを動かさずにGCPから活用することで、短期間でプロジェクトを完了させました。
-
BigQueryのストリーミングインフラをIcebergテーブルに適用し、高速な書き込みが可能に。
3. 数々のセッションから見えた、データ基盤構築における「新時代の最適解」
[考察1] 「データを一箇所に集約する」という前提を疑う
【セッションで語られた実態】: WPP社やGlobal Payments社は、データの「物理的な配置場所」が最大の障壁でした。データを無理に一箇所へ動かそうとすると、そのデータに紐づいた周辺のアプリケーション群まで作り直す必要が出てしまい、影響範囲が大きくなりすぎるからです。そこで両社は、データは元のクラウドに置いたまま、共通の「カタログ(目次)」だけを統合する手法を選びました。
【現場が取るべきアプローチ:私自身の気づき】:
「データ統合=物理的なお引越し」と捉えると、膨大なコストと時間がかかることにハッとさせられました。大切なのは、データを集めることではなく、「どこに何があるか、すべてのデータが見渡せる目次(カタログ)を一つにすること」です。経営層からデータ統合の命を受けた際は、力技でデータを移すのではなく、各クラウドを繋いで一つの巨大な図書館の検索システムにするような「目次作り(カタログの統合)」を代替案として提示することも選択の1つとして考慮できる時代になったのだと感じました。
[考察2] AIの精度を左右するのは、データ量よりも「意味づけ(コンテキスト)」
【セッションで語られた実態】: AIがもっともらしい嘘(ハルシネーション)をつくのを防ぐには、AIがビジネスの背景を正確に理解している必要があります。Googleはこれを「ナレッジカタログ」として重要視しています。また、Iceberg Summitでも、数万列に及ぶ複雑なデータをAIが扱いやすくするための新しい仕組みが議論されていました。
【現場が取るべきアプローチ:私自身の気づき】:
「AIツールさえ導入すれば、勝手にデータから価値が生まれる」わけではなく、人間が「このデータはどういう意味を持つのか」を整理するプロセスが不可欠だと痛感しました。現場の貴重なリソースを、単なるデータの移動に費やすのはもったいない話です。それよりも「このデータはこういう意味で、あのデータと繋がっている」という、AIのための丁寧な事前準備(データの定義・カタログ化)に注力すべきだと見えてきました。
[考察3] ツールを統一するのではなく、データの「規格」を揃える
【セッションで語られた実態】: 現場ではSparkを使うチームもあればBigQueryを使うチームもあり、それぞれが得意なツールを持っています。特定の製品の独自機能に頼りすぎると「そのツールでしか開けられないデータ」ができてしまいますが
【現場が取るべきアプローチ:私自身の気づき】:
社内の分析ツールを無理に一つに統一しようとするのは、各部署の反発を招くだけだと感じました。それよりも、どんなツールからでもアクセスできる「共通のデータ規格」を整えることが重要です。使用するツールを制限するのではなく、データ形式(Iceberg)と管理ルール(カタログ)を標準化すること。これが、現場の作業のしやすさを保ちながら、組織としての一貫性を保つための現実的な着地点と言えます。
[考察4] 単純なコードの書き換え作業は、AIツールに任せる
【セッションで語られた実態】: 古いシステムから新しいシステムへ移行せざるを得ない場合、一番の苦労は山のような古いSQLの修正です。しかし現在の移行サービスでは、この「古い言語から新しい言語への翻訳」をAIが高精度で自動実行できるようになっています。
【現場が取るべきアプローチ:私自身の気づき】:
エンジニアが手作業でコードを一行ずつ直す時代はもう終わったのだ、と改めて感じました。こうした機械的な変換作業は支援ツールに任せ、人間は「そのデータを使って、いかにビジネスを改善するか」という戦略的な議論に時間を使うべきです。移行プロジェクトの見積もりを作る際は、「AIで自動化できる部分」を切り分け、人間がもっと価値のある仕事に集中できる環境を前提にするのが正解です。
4. おわりに
データを特定のデータベースに閉じ込め、日々増え続けるデータ移動の保守に追われるやり方は、もはや過去のものになりつつあります。今回の一連のセッションが示していたのは、Apache Icebergという標準規格と、クラウドが提供する「データを動かさずに繋ぐ」技術により、現場の負担を劇的に減らせるという事実でした。
現場を率いる皆様にとって、これらの気付きは単なるITの最新トレンドではなく、チームの限られた時間と労力を守るための新時代の選択肢となります。「データを移さず、意味を繋ぐ」。この新しい常識を武器にして、終わらない移行作業から抜け出し、本来の目的であるデータ活用そのものにリソースを集中させていきましょう。
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス



Careersキャリア採用


この記事をシェアする

