VMware Live Site Recovery(VLSR=旧SRM)の紹介
2026.01.07
- インフラ
- 仮想基盤
本記事の目的
はじめに
インフラ技術部T.Oです。
本記事は、VMware Live Site Recovery(VLSR=旧SRM)をほとんど知らない方向けに、
基本部分から具体的な利用例など伝えることを目的とします。
今回「アレイベースレプリケーション」という方法をご紹介しますので、
「アレイベースレプリケーション」や「プレースホルダー」
といった、聞き馴染みのない概念を主に理解いただければ幸いです。
VMware Live Site Recoveryとは何か
VMware Live Site Recovery(VLSR)は、
vCenterと連携して仮想環境の災害復旧を自動化するVMwareのソリューションです。
2024年5月にVMware Site Recovery Manager(SRM)としての販売が終了し、現在はVLSRとして同機能が提供されています。
VLSRでは事前にリカバリ手順をポリシー化することで、それに基づいたリカバリサイトへの自動的な切り替えが可能です。
本番環境に影響を与えないテスト実行や計画的な切替、フェイルバックも安全に行えます。
保護設定の単位はデータストア、ストレージ単位だけでなく、
VMware vSphere Replicationと連動させることで、仮想マシン単位での保護を実現することもできます。
VLSRを利用するには別途サブスクリプション制のライセンスが必要となり、
保護対象仮想マシンの台数などによってサブスクリプション料金は変動します。
VLSRが解決する課題
VLSRは、災害時などのデータ退避作業における人為的ミスや手順の曖昧さ、復旧作業時間のばらつきを解消します。
手順を事前定義して自動実行することで、複雑な依存関係のあるVM群を正しい順序で起動・接続でき、
テスト実行という機能を使えば本番影響なしでの検証も可能です。
また、ストレージレプリケーションやネットワーク再マッピングといったインフラ差異の吸収も支援します。
VLSRの利用シーン
代表的な利用例としては、以下が挙げられます。
・データセンター間の災害復旧計画(DR)実行
・定期的なリカバリテスト
・環境を跨いだ計画済みの移行
VLSRの基本的な構成要素
Site(保護サイト/リカバリサイト)
VLSRでは前提として、平時に稼働させる保護対象拠点と、保護対象が復旧不可となった際の退避先拠点が必要です。
これら二つの拠点を「保護サイト(Primary)」と「リカバリサイト(Recovery)」として扱います。
保護サイトが通常の稼働拠点、リカバリサイトは障害時にVMを復旧する拠点です。
両サイトはペアリングをした後、ネットワークやストレージの接続設定などの事前マッピングが必要となります。
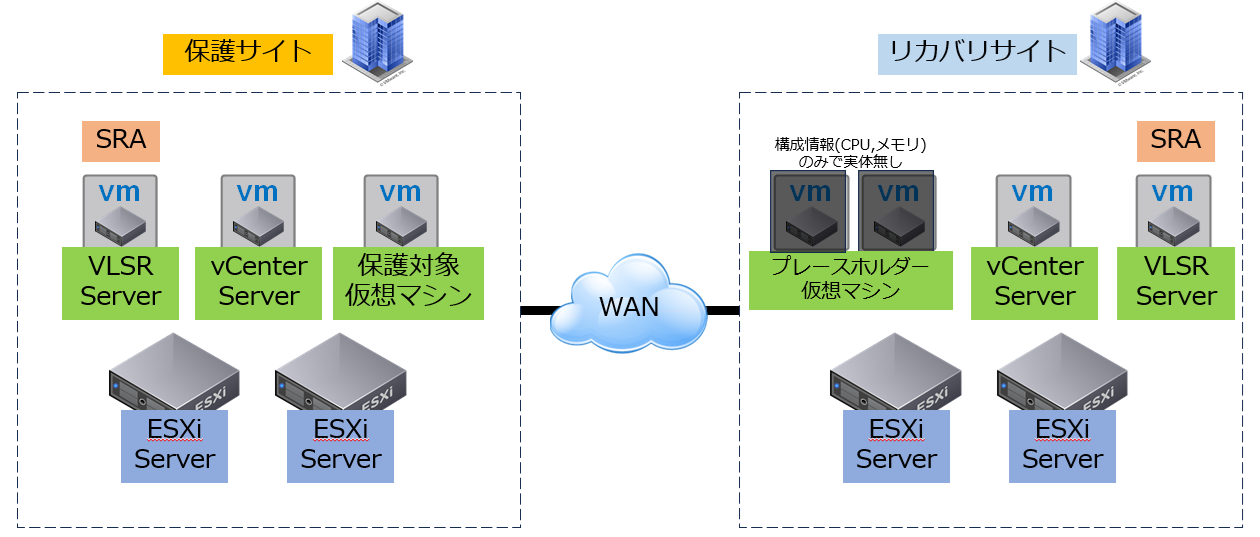
プレースホルダー
プレースホルダーはリカバリサイト上に作られる「仮のVMエントリ」で、メモリやCPUサイズといった情報だけを持ちます。
リカバリサイトへのIP・ホスト配置の事前予約といった意味があり、
フェイルオーバー時に本来の仮想マシン情報と紐付けて復旧された仮想マシンが起動します。
これにより、急を要する復旧作業でも競合が発生せず安全性が保たれます。
なおプレースホルダー仮想マシンの格納先として、
双方向DRを行う場合、レプリケーション対象外のプレースホルダー用データストアを両サイトに用意する必要があります。
片方向DRのみ行う場合、レプリケーション対象外のプレースホルダー用データストアはリカバリサイトにのみ用意すれば問題ありません。
■プレースホルダー仮想マシンのイメージ図
レプリケーションとストレージ
データの転送や同期はVLSRの外側で行われ、
主にベンダーストレージのレプリケーション機能(アレイベース)やvSphere Replicationが使われます。
ストレージ機器のレプリケーション機能を使用する場合は、両サイトで同じモデルのストレージ機器を用意する必要があります。
VLSRはレプリケーションの状態を把握し、
レプリケーション単位(LUNやデータストア)をマッピングしてリカバリ時に正しいデータを割り当てます。
VLSR実行時は、Storage Replication Adapter(SRA)を介してベンダーストレージと連携し、
連携先のストレージでデータ同期コマンドなどが実行されます。
■アレイベースレプリケーションのイメージ図
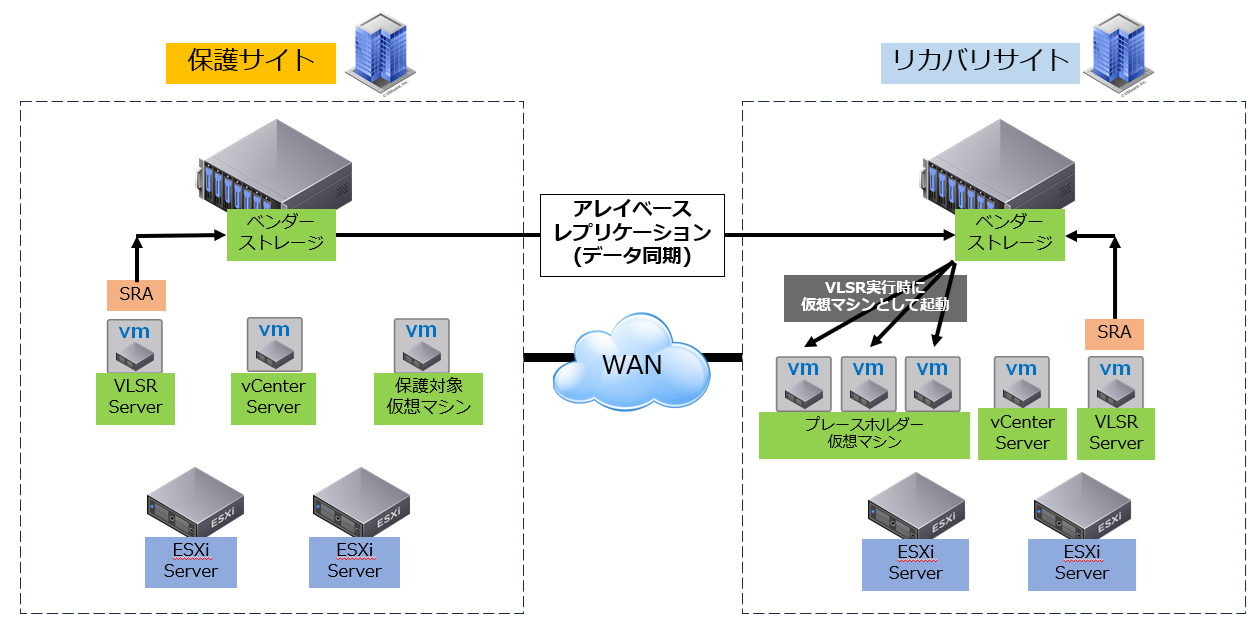
アレイベースレプリケーション
アレイベースレプリケーションは、ストレージ機器側でLUNやデータストア単位にデータを同期する方式です。
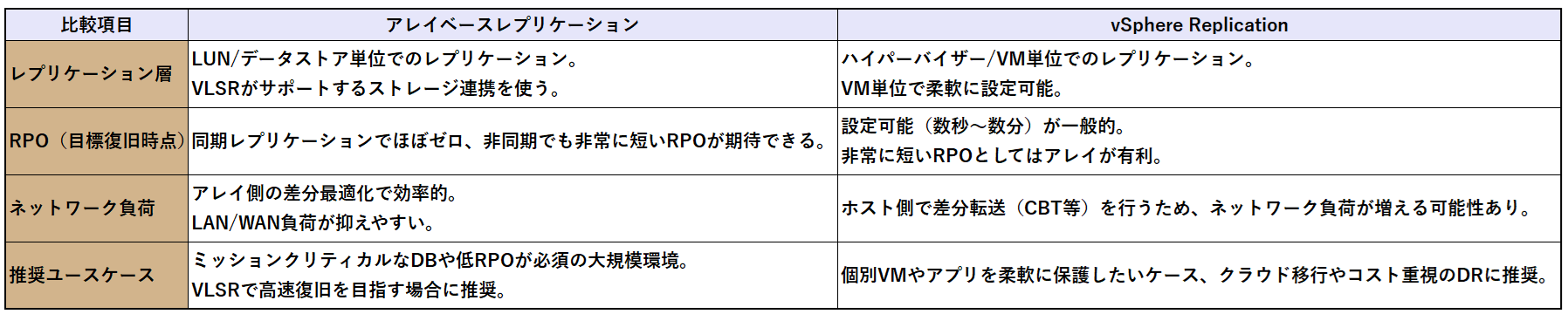
特徴は以下比較表の通りです。
■アレイベースレプリケーションとvSphere Replicationの比較表
アレイベースレプリケーションにおける注意点
アレイベースレプリケーションを扱う場合、気を付けるべきいくつかのポイントがあります。
代表的なものとして、サイト間のストレージモデルとファームウェアを統一すべき点があげられます。
ベンダーのレプリケーション機能はモデルやFWの差で動作仕様等が変わるため、
この点のミスマッチは、致命的な同期失敗や再保護時の不具合を招きます。
2つ目に、前述の比較表通りVM単位で個別に保護選択ができません。
重要なVMだけを個別に保護したい場合は、ストレージレベルの設計見直しも視野に入ります。
3つ目に、ストレージレプリケーションの遅延の程度によっては、RPOに影響を及ぼします。
WAN経路やストレージ側の負荷、IOパターンによる遅延を放置すると想定RPOを満たせなくなるため、
必要に応じて帯域制御や差分削減、WAN最適化、夜間の初期同期スケジュールなどの負荷分散対策が求められます。
アレイベースレプリケーションを使ったVLSRの流れ
構成前の前提条件
アレイベースでVLSRを構成する前に最低限確認すべき事項です。
まず、各サイトのvCenter/ESXiとVLSRのバージョン互換性、
Storage Replication Adapter(SRA)が使用する
ストレージアレイのモデル/ファームウェアでサポートされているかを確認します。
■参考URL:Product Interoperability Matrix
https://interopmatrix.broadcom.com/Interoperability
ストレージ側ではレプリケーションペアが正常に作成・同期されていることを検証します。
ネットワーク面ではサイト間接続やファイアウォール設定など、
そしてリカバリサイトには十分なリソースとデータストア容量を確保する必要があります。
さらに、テスト用に分離されたネットワークまたはVLAN、プレースホルダー用データストアの用意も重要です。
保護グループとリカバリプラン
保護グループは「どのVM/データストアを保護するか」をまとめる単位です。
アレイベースでは通常、データストア/ボリューム単位で複数VMを一括で保護します。
そして保護グループをまとめる形でリカバリプランが作成でき、
リカバリプランは、まとめた保護グループの切替実行単位となります。
リカバリプラン作成時に、
VM起動順序(依存関係に基づく優先度)、各VMのネットワークマッピング、IPアドレス変換を定義します。
実運用では定期テスト結果の記録、起動時間の検証、依存する外部サービスの確認をリカバリプランに反映することが重要です。
プレースホルダーの詳細と運用上の注意
プレースホルダーの生成タイミングと用途
プレースホルダーはVLSRで保護グループを作成し、リカバリサイトを検出するときに生成される仮のVMエントリです。
ディスクや実体は持たず、VM名やリソース配置、構成情報の予約を行うことでフェイルオーバー時の競合回避を実現します。
テスト時にも用いられ、本番環境に影響を与えず起動順序や依存関係の検証が可能になります。
プレースホルダーとIP/ネットワークの扱い
プレースホルダー自体にはIPが割り当てられません。
リカバリ時にはリカバリプランで定義したネットワークマッピングや
カスタマイズ情報に基づいてIPやホスト名の変更が適用されます。
テストでは隔離VLANを使ってIP重複を防ぎ、
実運用フェイルオーバーでは事前にDNSやDHCP、IP変換ルールを確認しておくことが重要です。
具体的な使用例(シナリオ別)
シナリオA:データセンター間での災害復旧(アレイベース)
アレイベースで同期または非同期レプリケーションを用いる典型的な災害復旧です。
VLSRで平時からマッピングを行い、
障害発生時はVLSRのリカバリタイプ:ディザスタリカバリでリカバリサイトへ切り替えます。
事前に十分なテスト実行を実施することが重要です。
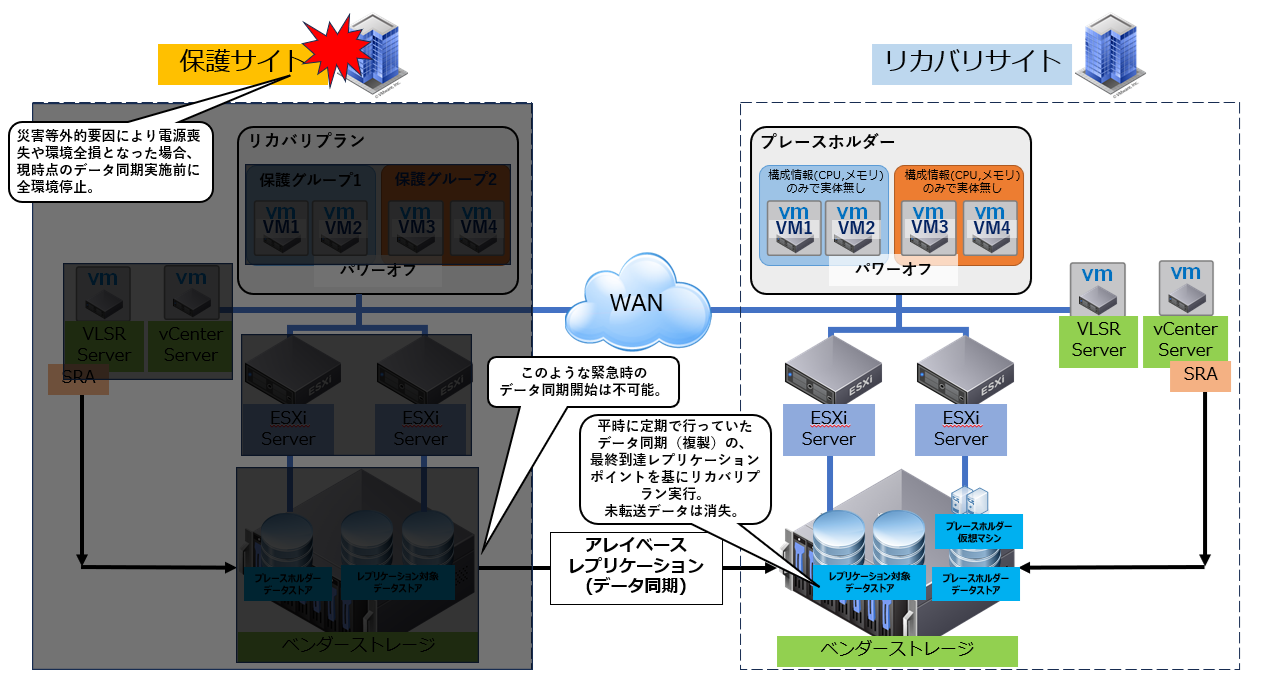
■①データセンター間での災害復旧:平常時
■②データセンター間での災害復旧:保護サイト環境全損
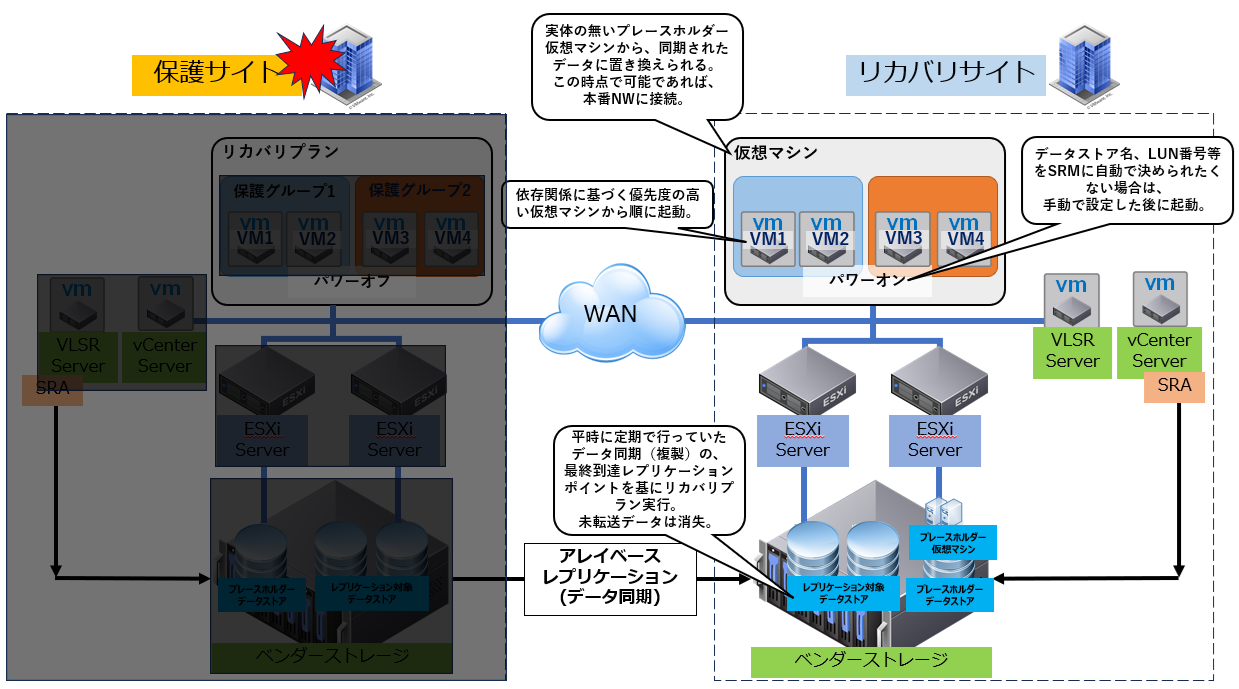
■③データセンター間での災害復旧:DR実行
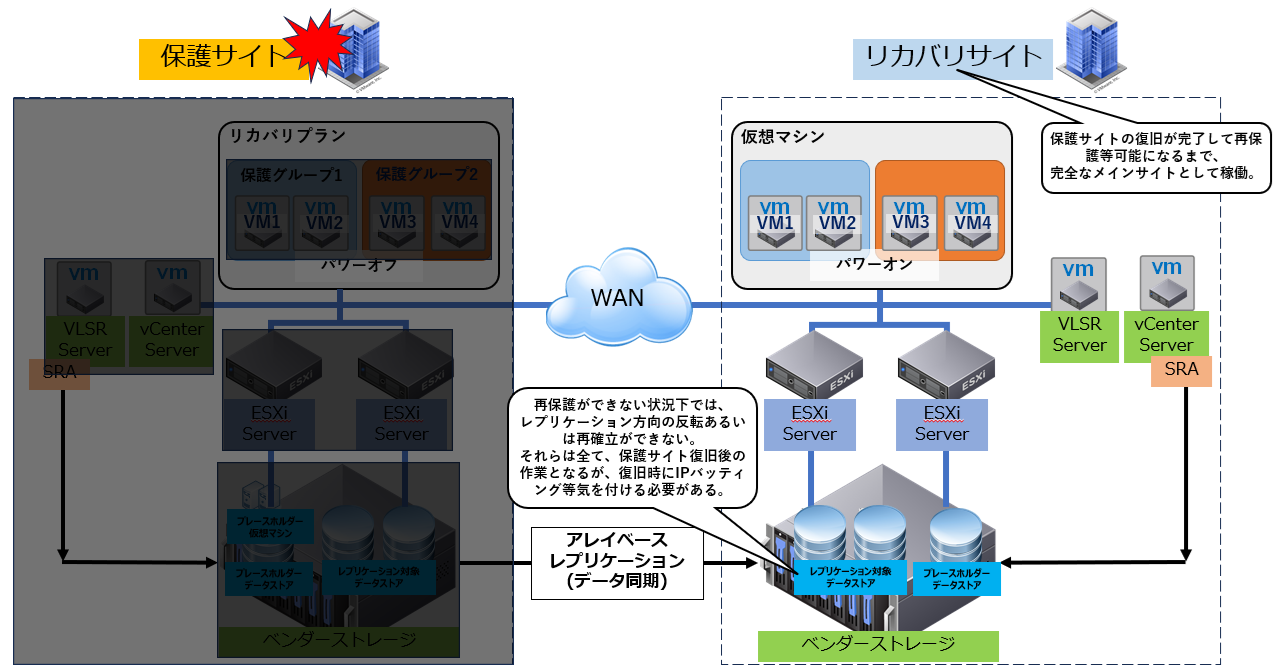
■④データセンター間での災害復旧:DR実行後
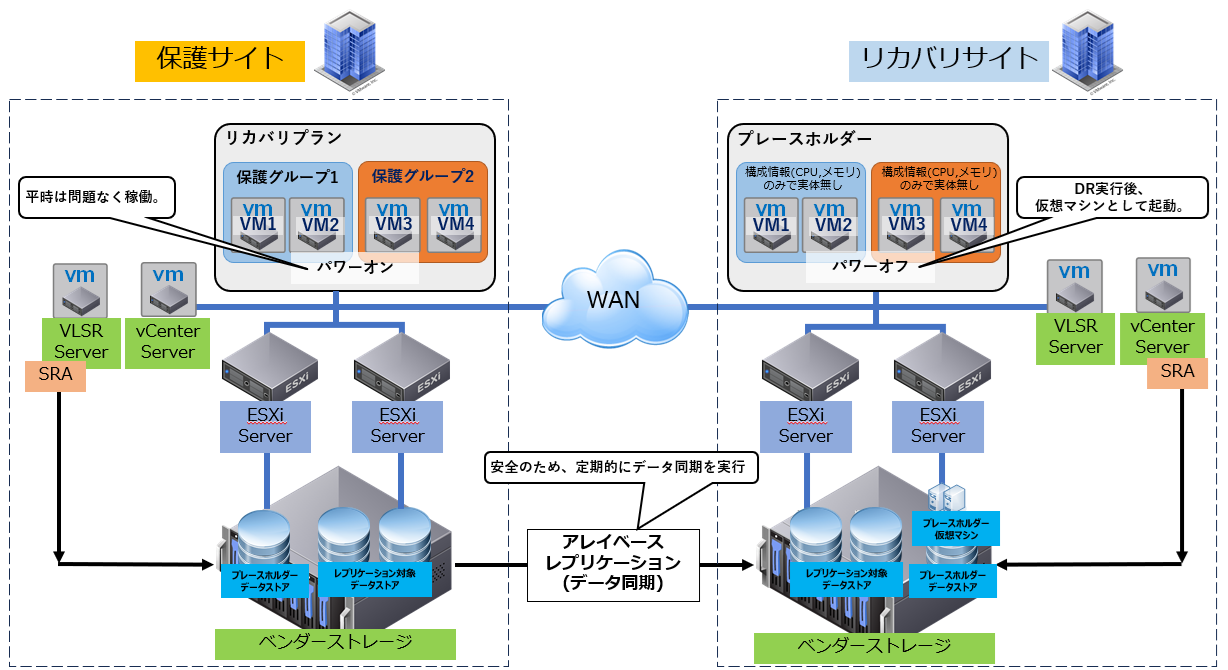
シナリオB:定期的なDRテスト(本番非影響での検証)
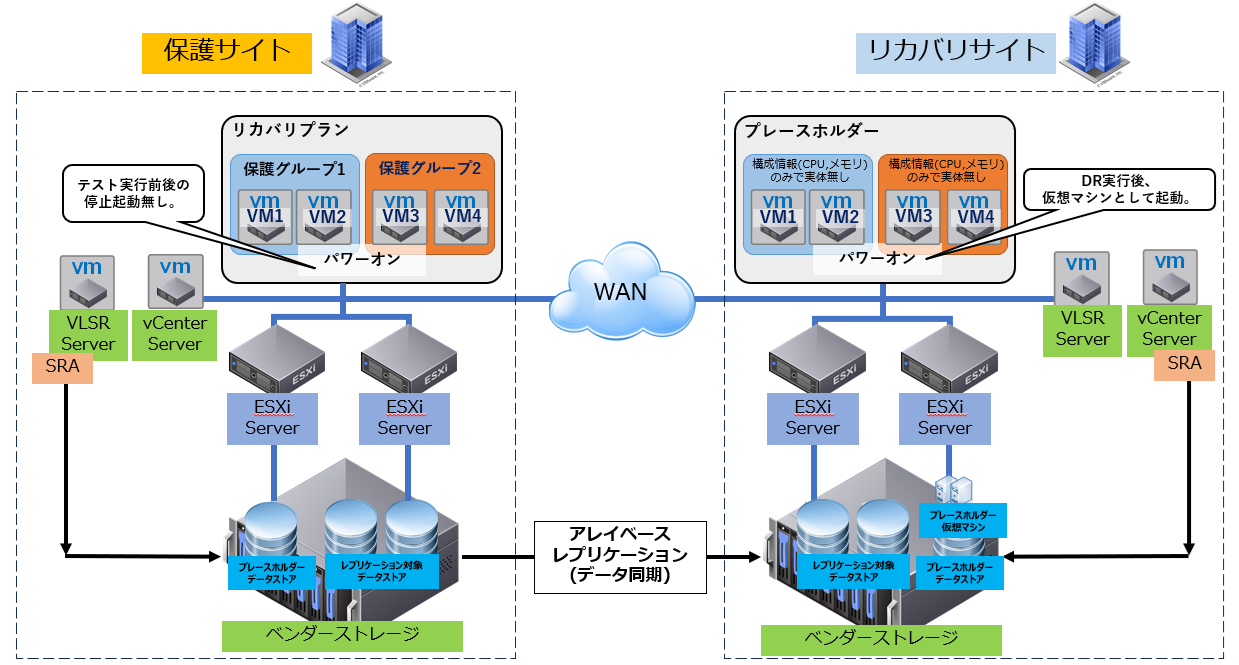
VLSRのテスト機能を使えば、本番データに影響を与えずに復旧手順を検証できます。
プレースホルダーと隔離VLANを利用してネットワーク衝突を避け、リカバリプランで起動順序やカスタマイズを確認します。
定期テストは運用要員の習熟、手順書の更新、想定外の依存関係の発見に有用です。
結果は記録して改善に活かしましょう。
■定期的なDRテスト(本番非影響での検証)
シナリオC:計画的なデータセンター移行
計画移行ではVLSRの計画移行機能を使い、サービス停止時間を最小化して環境を新拠点へ移動します。
移行前にレプリケーションを同期させ、ネットワークマッピングやIP変換を準備。
移行中は最終同期→シャットダウン→起動の順で整合性を保ち、
移行後にリカバリプランステータスがリカバリ完了となった後、後段の再保護を実施することで、
移行前の保護関係を自動で逆向きに構成し、移行先をメインサイトとして稼働することができます。
■計画的なデータセンター移行
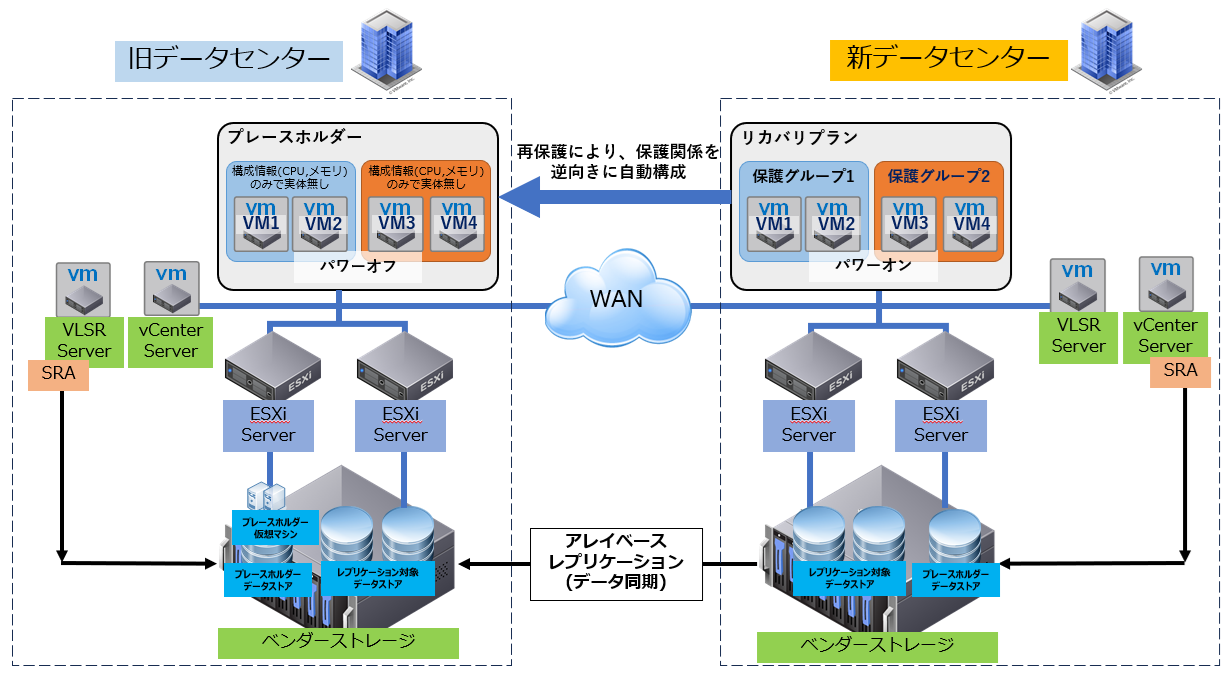
テスト実行などの簡易的な流れ
主な実行の流れ
vCenter、ESXi、VLSRのバージョン互換性を確認し、SRAが両サイトに導入済みであることを確認します。
両サイト間ネットワーク疎通、リカバリサイトのリソース等を確認します。
事前確認が完了した後、リカバリサイトのホストやストレージ機器を適切な準備状態へ移行し、
保護サイトでもレプリケーションの準備を進めます。
移行のために、保護サイトの仮想マシンを順次シャットダウンし、
その後保護サイトからリカバリサイトへストレージの同期を実行します。
同期が完了し次第、必要なリカバリプランを逐次実行し、
起動順序に沿って保護サイト仮想マシンがプレースホルダーへと置換され始めます。
保護設定(保護グループとレプリケーションの確認)
保護対象のVMとそれが格納されているデータストアを特定し、ストレージ側で対象LUNがレプリケーションされていることを確認します。
VLSRでサイトペアリングを行い、SRA経由でレプリケーション済データストアを検出・マップ。
保護グループにVMを登録し、リカバリプランで起動順序やネットワークマッピング、カスタマイズ仕様を設定。
レプリケーションのヘルスとRPO設定を最終確認します。
テスト実行
VLSRのテスト機能を使い、まず隔離VLAN/テストネットワークを指定してテストを実行します。
プレースホルダーからVMを起動し、起動順序やサービス依存、IPカスタマイズが正常かを確認。
実データや本番ネットワークには影響を与えないため、
スクリプトや接続先確認、ログの収集を行い、想定外の依存関係を洗い出して手順を改善します。
これらテスト実行が完了した後、クリーンアップ機能を実行する必要があります。
これにより、一時的に構成されたテストデータを破棄してストレージをリセットします。
テスト環境に行った変更は保持されず、テスト実行の前の状態に全て戻すことで、
次回のテスト実行や計画移行が実施可能となります。
実移行とフェイルバック
計画移行は最終同期→サービス停止→移行、
緊急時は即時移行を実行します。
移行後はサービス起動と疎通確認を速やかに実施。
保護サイト復旧後は再保護で逆方向レプリケーションを確立し、フェイルバック手順で保護サイトへ戻します。
通信連絡、ロールバック条件、検証手順を事前に明確にしておくことが肝要です。
最後に
VLSRを有効に使うには、各機能の意味と役割を理解し、事前準備と定期テストを怠らないことが肝心です。
リカバリプランや保護グループで手順を明確化し、
プレースホルダーやネットワーク/DNSの扱いを整えておくと、テスト移行や実移行がスムーズになります。
小さな検証を繰り返して運用手順を磨き、万一の際に迅速に対応できる体制を作りましょう。
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス

Careersキャリア採用


この記事をシェアする

