データ活用事始め - ETL処理の必要性
2024.08.23
- データエンジニアリング
はじめに
この記事ではデータ活用のために必要な工程であるETL処理について紹介します。
ETL処理が必要となる理由、どのように実施するかについて記載していきます。
データ活用には構造化データの作成が必要
ここでは、一般的に業務で使用されるExcel帳票や基幹システムに含まれるデータの活用例として、以下のような簡単なダッシュボードで分析をするケースを考えます。
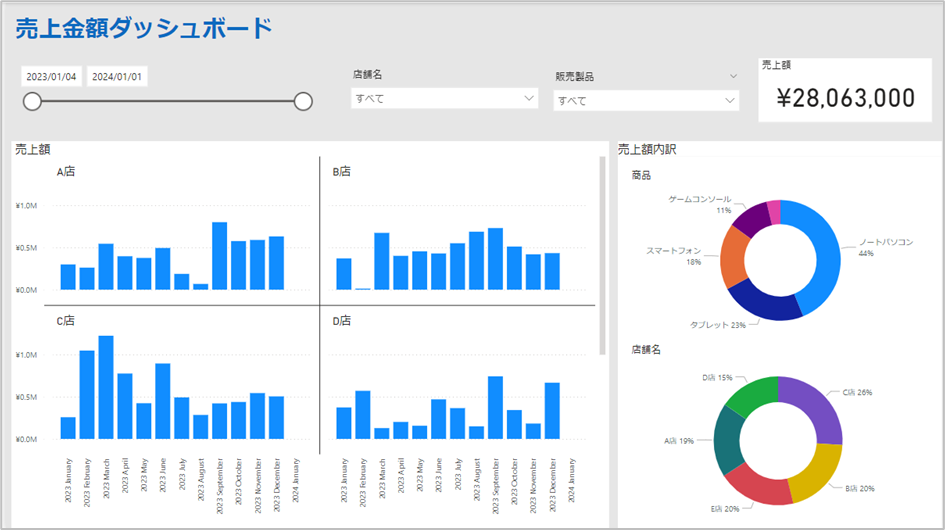
このダッシュボードは、Microsoft PowerBIを使用して作成しています。
このようなBIツールにグラフを表示するためには、基本的には以下のようなテーブル形式のデータが必要となります。(構造化データと呼ばれます)
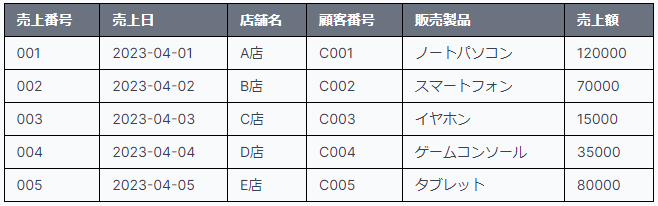
活用データに必要なこと
ダッシュボード向けに活用するための構造化データは、このほかにも様々な要求を満たす必要があります。
(ダッシュボードの用途により満たすべき要求は異なります)
【要求の例】
- 時系列データとして参照できること
- 販売日時や、ログの取得時刻ごとに集計表示する必要がある場合、日時が正しく入った列が必要となります。
- 大量のデータから集計などにより必要なデータを抽出できること
- 生データ(販売履歴、システムログなど)が大量になる場合、すべてBIツールにそのまま入力してしまうと、重すぎて処理できなくなる場合もあります。
- ダッシュボードの表示に使用する粒度(1ヶ月ごと、1日ごとなど)によって、あらかじめ集計しておいたデータを用意する必要があります。
- 表示目的のデータ列(売上額などのKPI)がすぐに取り出せること
- 複数のデータ列を用いて、あらかじめ目的の値を計算しておくことで、ダッシュボードにスムーズに表示できるようになります。
- データが正確であること
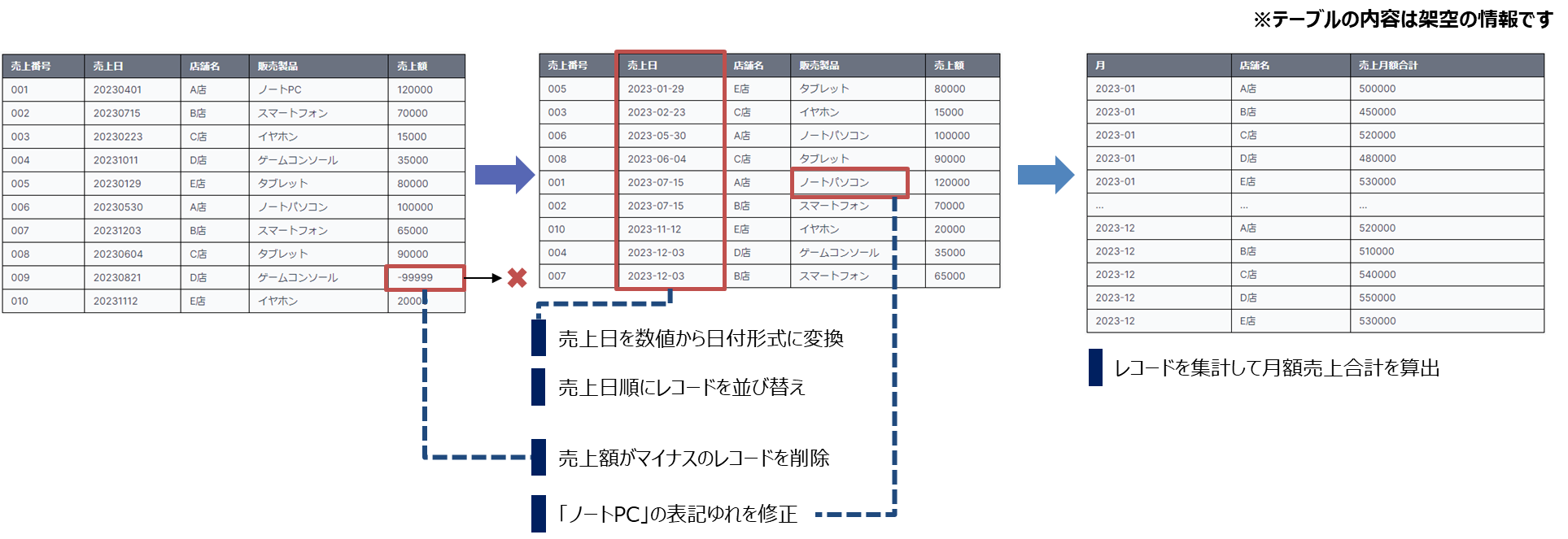
- 例えば同じ商品の販売データでも、"ノートパソコン"と"ノートPC"で入力されている(表記ゆれがある)場合は、そのままだと別の売上商品としてダッシュボードで集計されてしまうため、統一する処理が必要です。
- 表記ゆれ以外にも、売上額が入力されていない(欠損データ)の場合にも、0を入れるか他の値を入れるか、検討が必要になります。
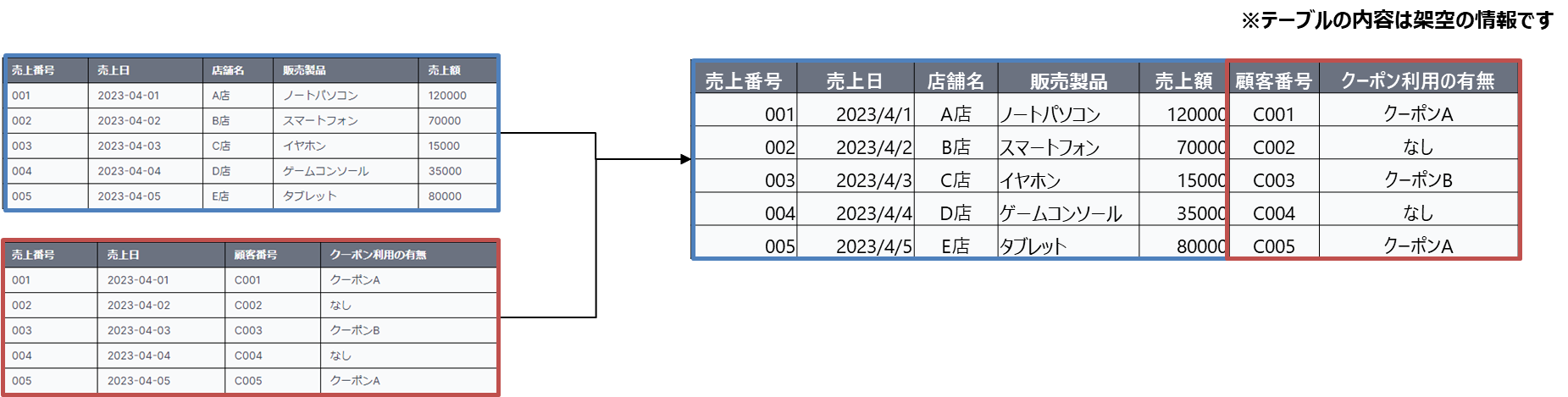
- 別々に保管されているデータを合わせて表示用のデータとすること
- ダッシュボードで確認したいデータを作るために、別々のシステムに保管されている情報を組み合わせて統合することも、一般的に必要となります。
- ダッシュボードで確認したいデータを作るために、別々のシステムに保管されている情報を組み合わせて統合することも、一般的に必要となります。
こうした要求を満たすために、一般的には複数のデータソースに対してETL処理を実施することになります。
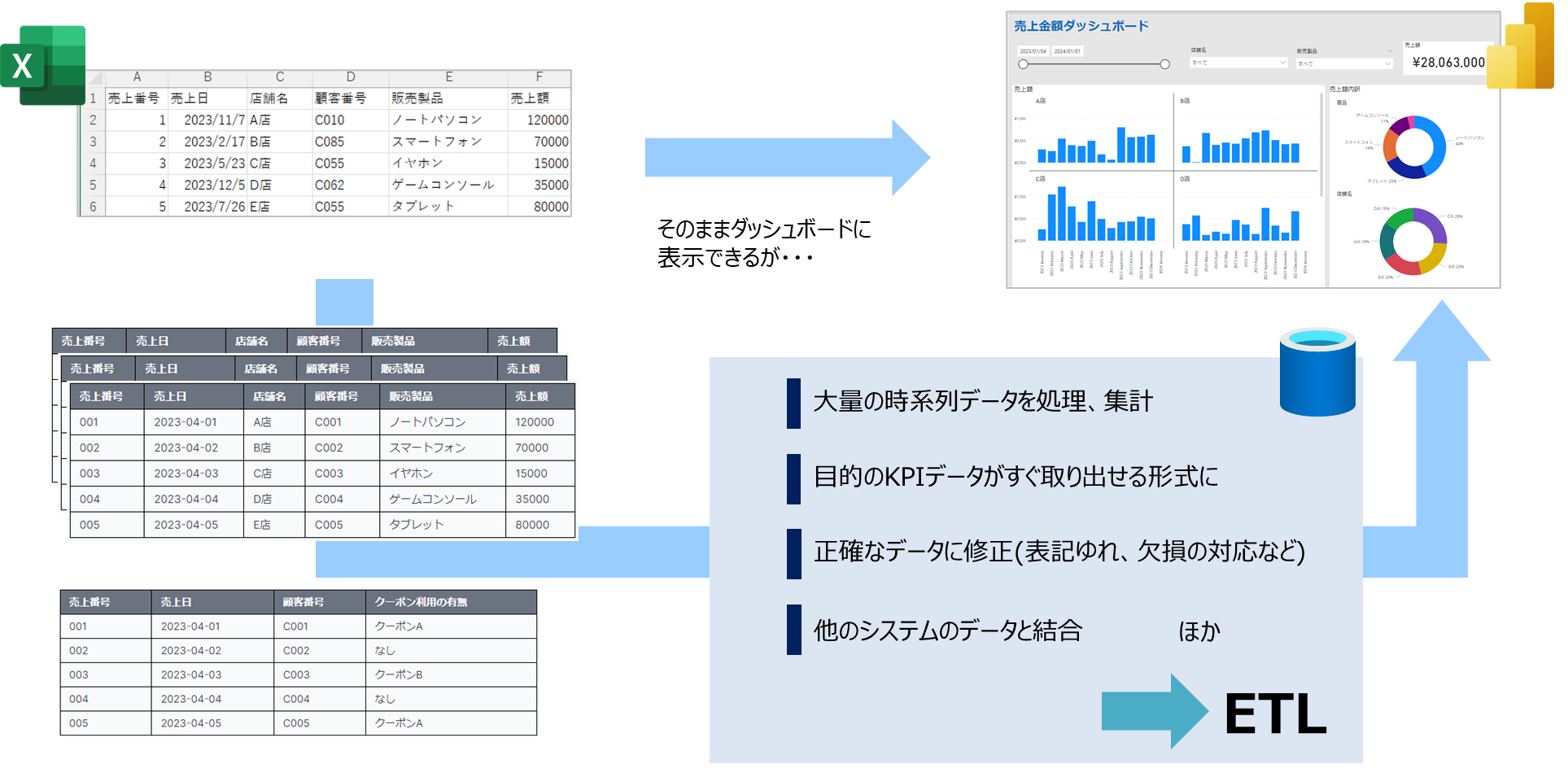
用途ごとのデータとETL
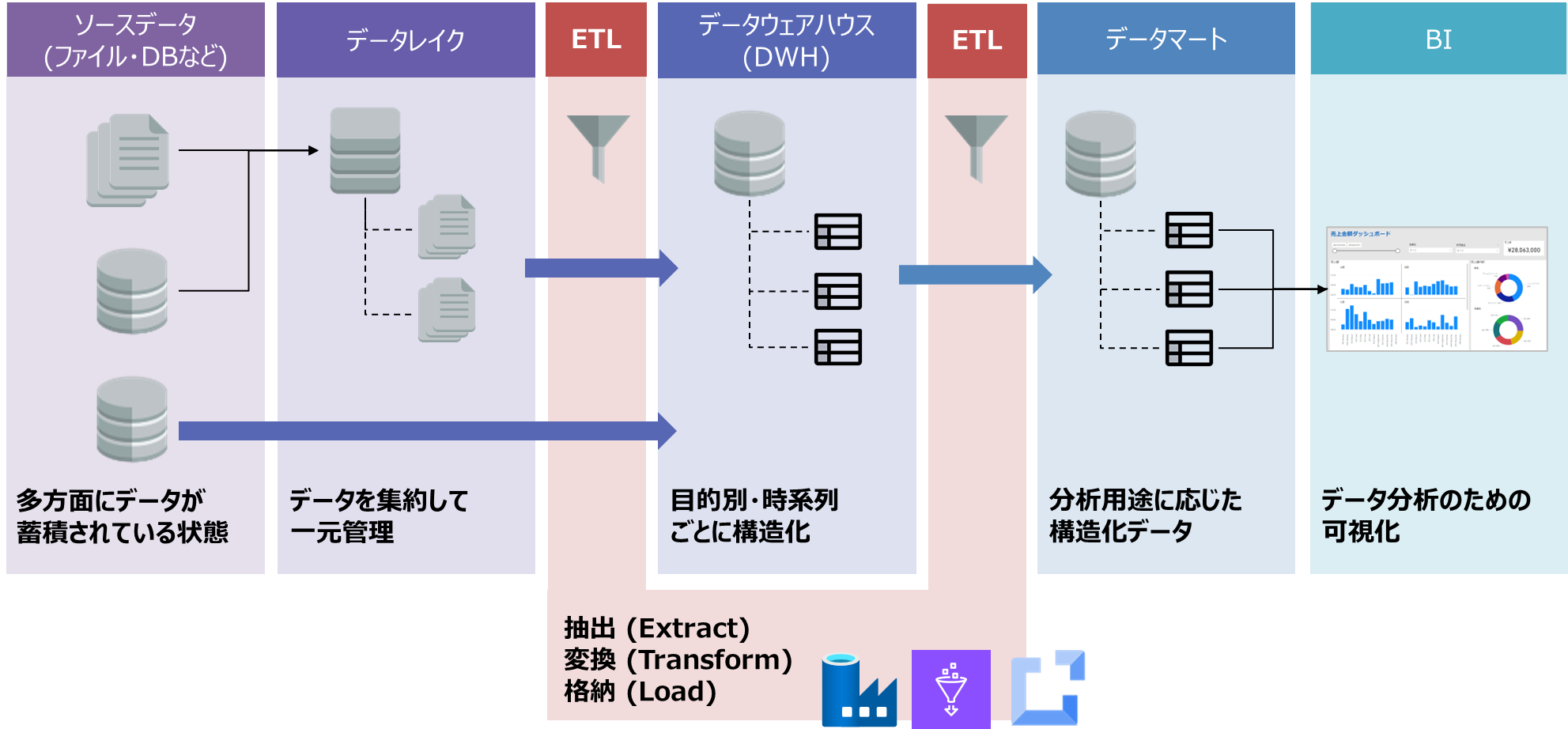
一般的に、集められたソースデータは以下の順序で整理されます。
- データレイク
- 構造化データ、非構造化データを問わず、企業・組織における活用対象のデータを大規模ストレージに集めたものです。
- 大量の生データをそのままの形式で保存します。
- 低コストでデータの保管をすることに特化しています。
- データウェアハウス(DWH)
- データレイクに保存された生データ、あるいは組織の他システムから抽出したデータを構造化した形式で保管します。
- ETL処理によりデータが整理され、分析用に最適化されています。
- データの整合性と品質を維持するためにモデリング等が行われます。
- 時系列でデータを保持し、データのトレンドを分析することができるようになります。
- データマート
- 特定の用途(ビジネス領域など)に焦点を当て、特定のグループのユーザーが活用するためのデータベース(構造化データ)です。
- データウェアハウスのサブセットであり、一つの部門に特化した小規模データの集まりです。
- BIツールなどのために独立して構築する場合と、データウェアハウスとセットで構築される場合があります。
- 小規模であることを活かし、迅速な検索に向いています。
ETL処理は、これらのデータを整理する中で、主にデータレイクからデータウェアハウスの作成とデータウェアハウスからデータマートを作成する場面で実施されます。
ETL処理をクラウド上で実施する際に利用されるサービスの例として、以下が挙げられます。(他にもたくさんあります)
- Azure Data Factory
- AWS Glue
- Cloud Data Fusion(Google Cloud)
ETLで実施する処理内容の例
ETL工程で実施される作業の例を紹介します。
一つ一つの作業の解説は割愛しますが、これらの作業から必要な項目を組み立ててデータフローを構築し、要求を満たす活用データを作成します。
データフローの例(Azure Data Factoryを使用した場合)
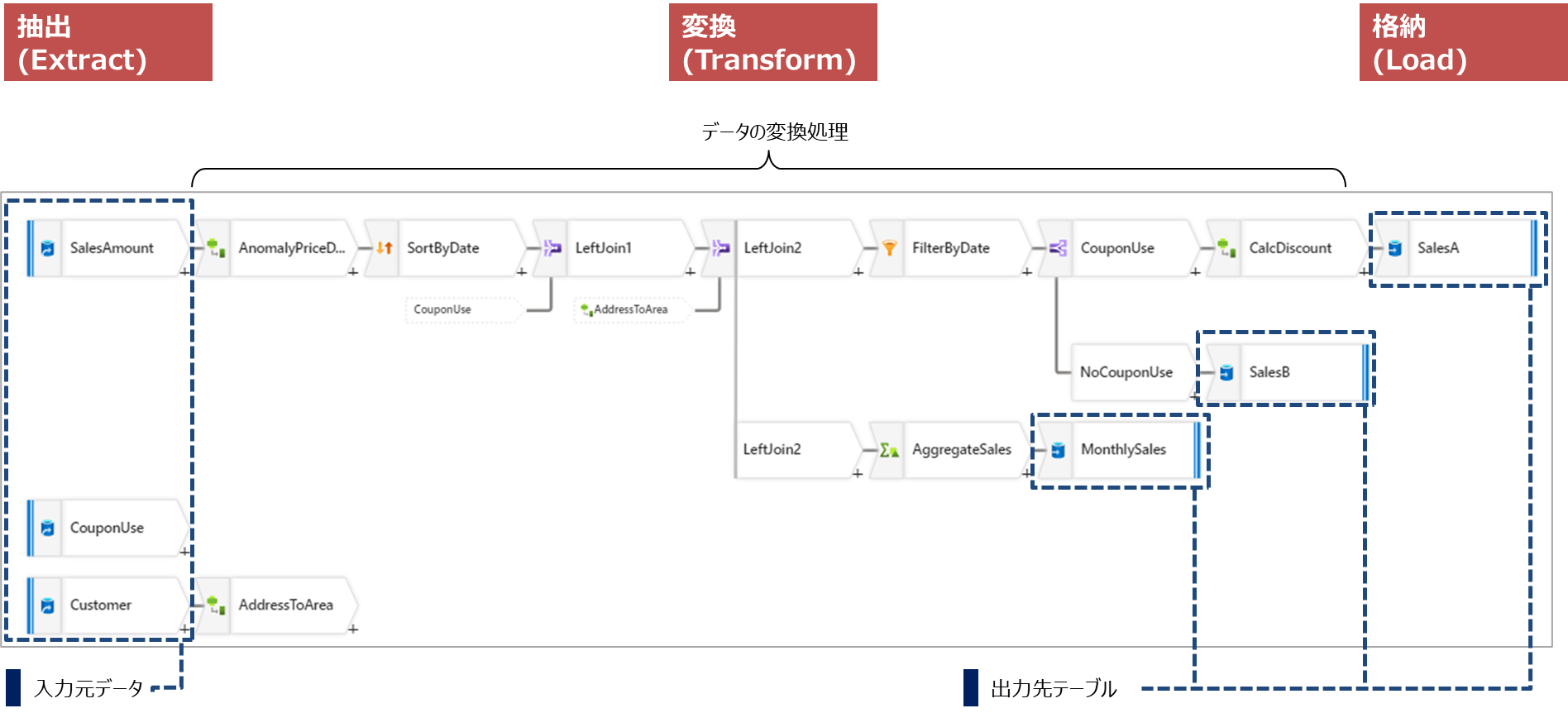
抽出(Extract)
- データソースからのデータの読み込み
- データベースクエリの実行
- APIを通じたデータの収集
- フラットファイル(CSV、Excelなど)の読み込み
- ウェブスクレイピングによるデータの収集
- ストリーミングデータのキャプチャ
- データレプリケーション
変換 (Transform)
- 欠損値の処理
- 重複データの削除
- 異常値の検出と修正
- データの型変換(例:文字列から日付型への変換)
- データの正規化/非正規化
- データのフィルタリング
- データの集約(グループ化、合計、平均など)
- データの結合(異なるソースからのデータのマージ)
- データの分割(単一のソースから複数のターゲットへの分配)
- データの並び替え(ソート)
- ビジネスルールや計算の適用
- データのマスキングや匿名化(プライバシー保護)
- データの検証と品質チェック
- データのデータピボット(行列の転置)
データ変換の例
(データ結合)
(データの並び替えなど)
格納 (Load)
- データウェアハウスやデータベースへのデータの書き込み
- データマートへのデータのロード
- オンライン分析処理(OLAP)キューブへのデータのロード
- データのインデックス付け
- ストリーミングデータのリアルタイムロード
- データのバルクロード
- データのインクリメンタルロード(差分更新)
- データの履歴管理(スナップショット、バージョニング)
- データのリフレッシュと同期
参考:ETLとELT
ETLと順序の異なる処理として、ELTという処理もあります。
Extract(抽出)→Load(格納)→Transform(変換)の順に実施することになります。
ELTは処理データ量が多い場合や、データウェアハウスに一度格納したデータを後で必要に応じて変換していくユースケースなどで適用されます。
クラウドベースで大規模なストレージを利用し、計算処理を分離して構築する場合などにも適しています。
他方、セキュリティやコンプライアンスが厳しく、データウェアハウスに保存する前に匿名化の処理が必要だったり、データ品質や整合性が求められる場合などはETL処理が適しています。
まとめ
ここまで説明してきたことのポイントは以下の通りです。
- データ活用の第一歩として、活用対象のデータを表形式の構造化データにすることが求められる
- 構造化データに求められる条件を満たすため、集計や正確さを担保するための処理が必要となる
- これらの処理を実施するのがETL処理で、これにより生データがDWHやデータマートとして整理され、活用できるようになる
- ETL処理にはデータの 抽出(Extract)・変換 (Transform)・格納 (Load) のための多くの処理作業が含まれる
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス

Careersキャリア採用


この記事をシェアする

