触って学ぶ SageMaker Lakehouse の概要と機能
2025.07.03
- AWS
- クラウド
- データエンジニアリング
SageMaker Lakehouse は、Amazon SageMaker でデータを扱ううえで中心的な役割を果たす機能です。
SageMaker Lakehouse は、データレイクである S3 とデータウェアハウスである Redshift を統合することにより、様々なデータソースからの横断的なデータの参照と分析を可能にしています。
Iceberg REST APIを通じて、AWSサービスだけでなく、ゼロETL統合やデータフェデレーションで取り込んだサードパーティのデータソースにもアクセスすることができます。
以降で、実際のデータ取り込みやデータソースの設定について詳しく見ていきましょう。
ノートブック
ノートブックから Lakehouse 上のデータにアクセスしたり、データを加工してテーブルに書き込んだりすることができます。
作成
プロジェクトの「New」→「Notebook」からノートブックを新規作成します。
「Notebook」の「Python 3」をクリックします。
以下のようにノートブックの画面が開きます。操作感は通常の Jupyter Notebook とほぼ同じです。
セル操作
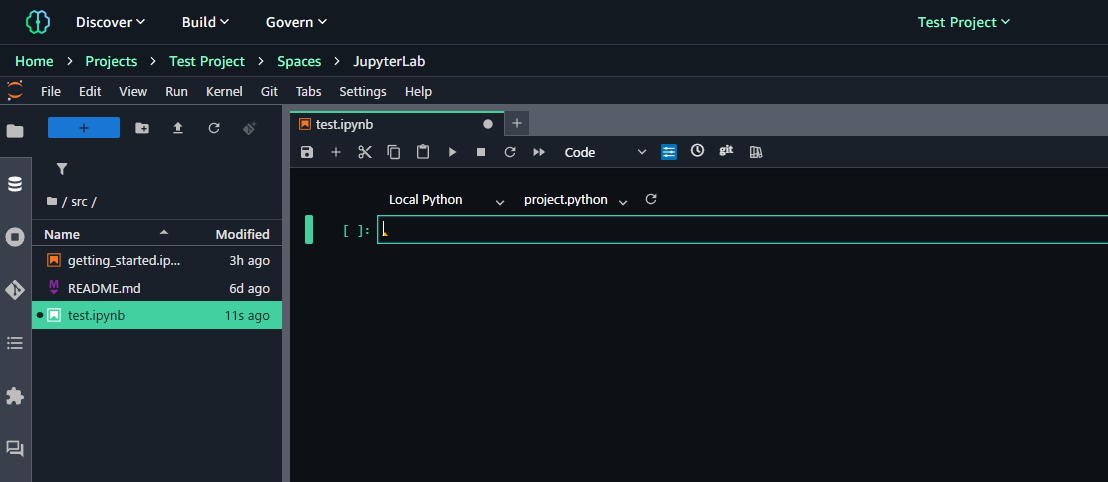
SageMaker では、セル単位で接続タイプ(言語)と実行環境を切り替えることができます。

左側が接続タイプで、PySpark, ScalaSpark, SQL, Local Python の4種類から選択可能です。右側は実行環境で、選択した接続タイプに対応するものを選択することが可能です。Local Pythonの場合、デフォルトはproject.pythonとなっています。
※PySpark を利用したい場合、明示的に切り替えておく必要があるため注意が必要です。
また、ノートブック上部のメニューバーからセルの種類を変更することができます。
データ取り込み
S3
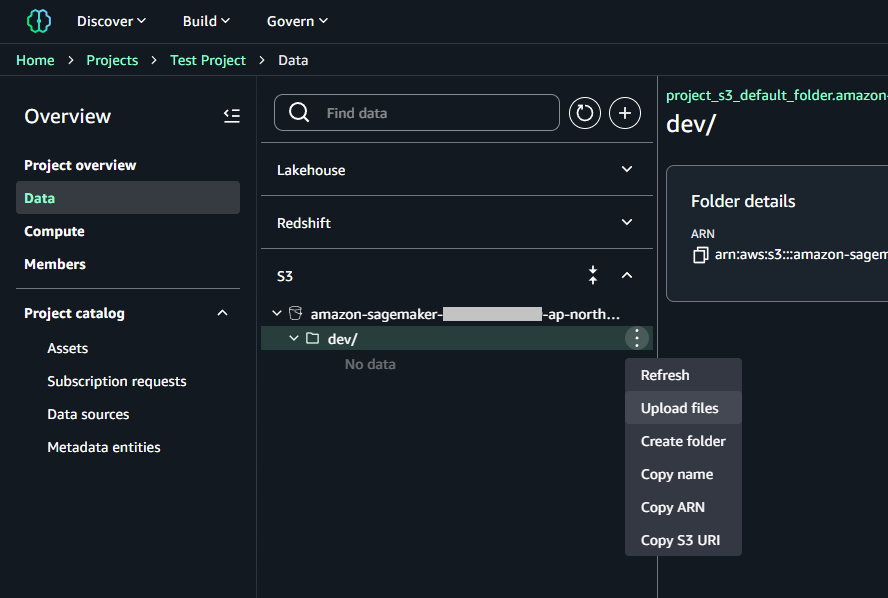
メニューの「Data」→「S3」→「Upload files」でファイルを直接アップロードすることが可能です。
検証にあたりこちらのファイルを使用します。中身は以下のような人口統計データです。
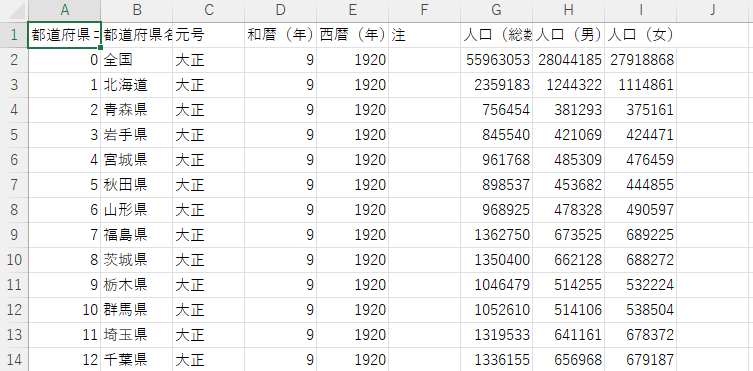
ファイルをアップロードし、ノートブックのセルで以下を実行します。接続タイプを PySpark に切り替えておきます。
from pyspark.sql import SparkSession
from pyspark.sql.types import *
# Sparkセッション作成
spark = SparkSession.builder \
.appName("connection") \
.getOrCreate()
# スキーマ指定
schema = StructType([
StructField("都道府県コード",StringType(), False),
StructField("都道府県名",StringType(), False),
StructField("元号",StringType(), False),
StructField("和暦(年)",StringType(), False),
StructField("西暦(年)",StringType(), False),
StructField("注",StringType(), False),
StructField("人口(総数)",IntegerType(), False),
StructField("人口(男)",IntegerType(), False),
StructField("人口(女)",IntegerType(), False),
])
s3_path = 's3://.../dev/c01.csv'
# データの読み込み
df = spark.read \
.format("csv") \
.options(header="true") \
.option('charset', 'shift-jis') \
.load(s3_path, schema=schema)
df.show()
結果は以下の通りです。S3のパスから直接データフレームに取り込めていることが確認できました。
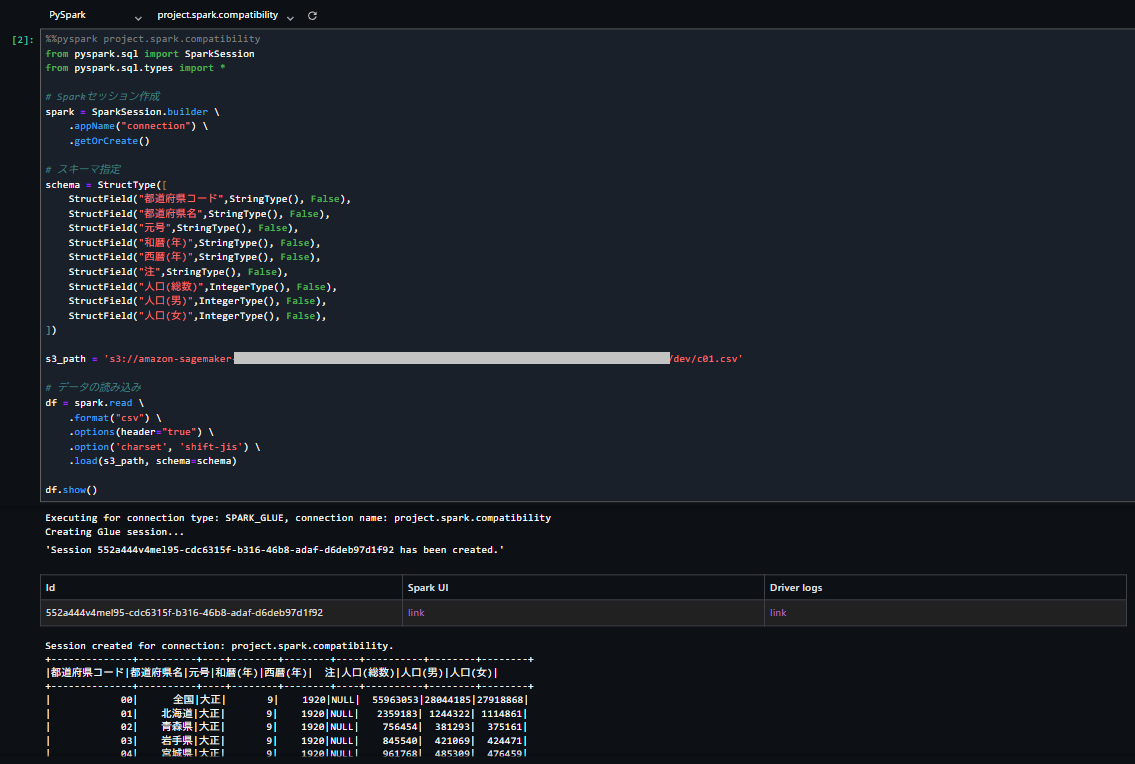
次に以下のコードを実行し、カラム名の変更とデータの整形を行います。
# カラム名変更
df = df.withColumnRenamed("都道府県コード","prefectures_code") \
.withColumnRenamed("都道府県名","prefectures") \
.withColumnRenamed("元号","era") \
.withColumnRenamed("和暦(年)","year_jp") \
.withColumnRenamed("西暦(年)","year") \
.withColumnRenamed("注","note") \
.withColumnRenamed("人口(総数)","population") \
.withColumnRenamed("人口(男)","man_population") \
.withColumnRenamed("人口(女)","woman_population")
df.show()
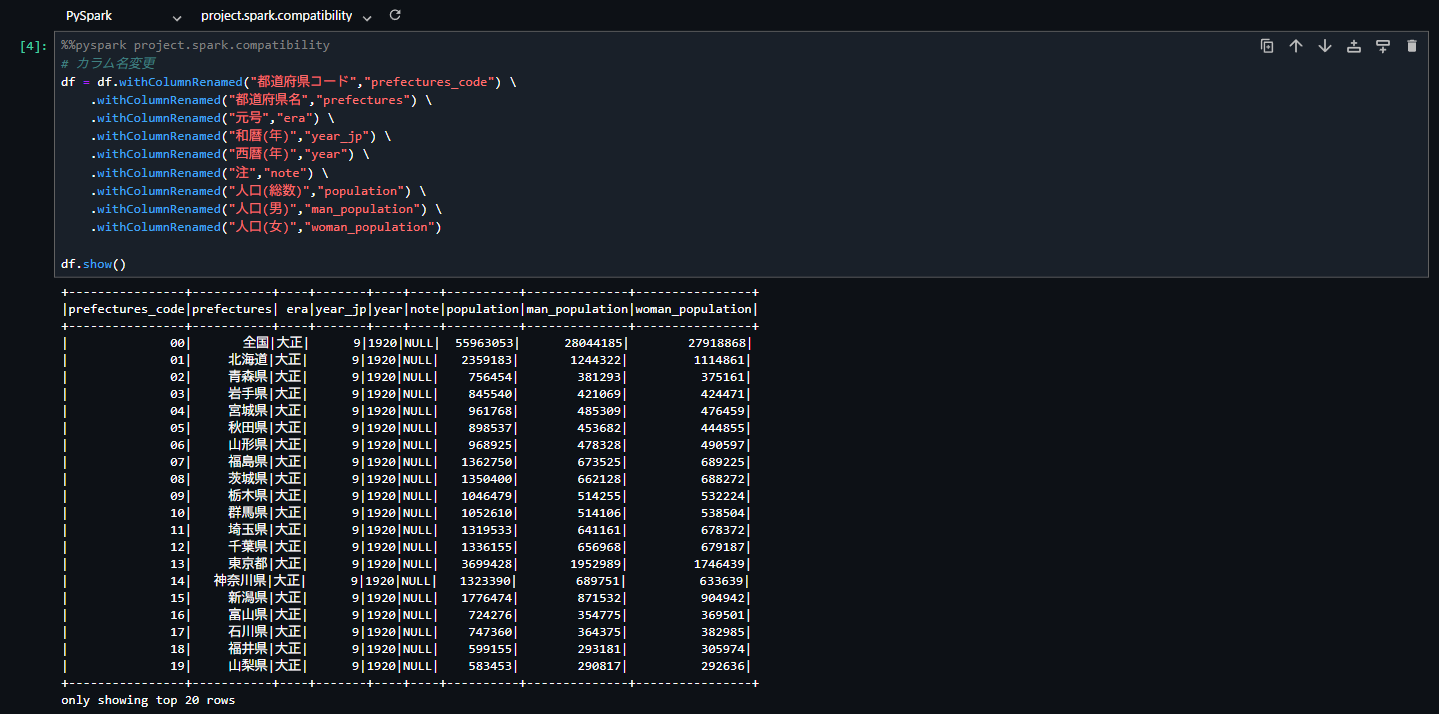
上記のデータフレームのデータを、以下のコマンドでテーブルに書き出すことができます。
from sagemaker_studio import Project
# プロジェクトデータ取得
project = Project()
catalog = project.connection().catalog()
project_database = catalog.databases[0].name
# データフレームのデータをテーブルに書き出す
df.write.saveAsTable(f"{project_database}.population_table", format="parquet", mode="overwrite")
作成されたテーブルは左側のメニューのデータベースアイコン→「Lakehouse」から確認可能です。
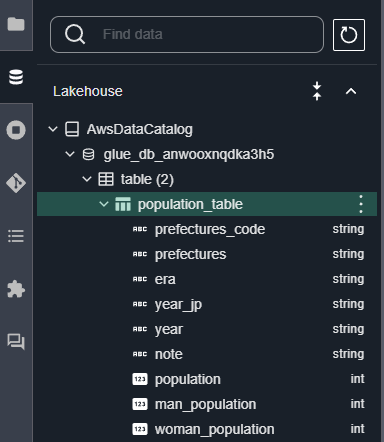
補足
PySpark は通常と同様にSQLを実行し、その結果をデータフレームとして取得することができます。
# 年ごとの全国の人口データを取得
sql = f"""
SELECT year, population, man_population, woman_population
FROM {project_database}.population_table
WHERE prefectures = '全国'
ORDER BY year
"""
df = spark.sql(sql)
df.show()

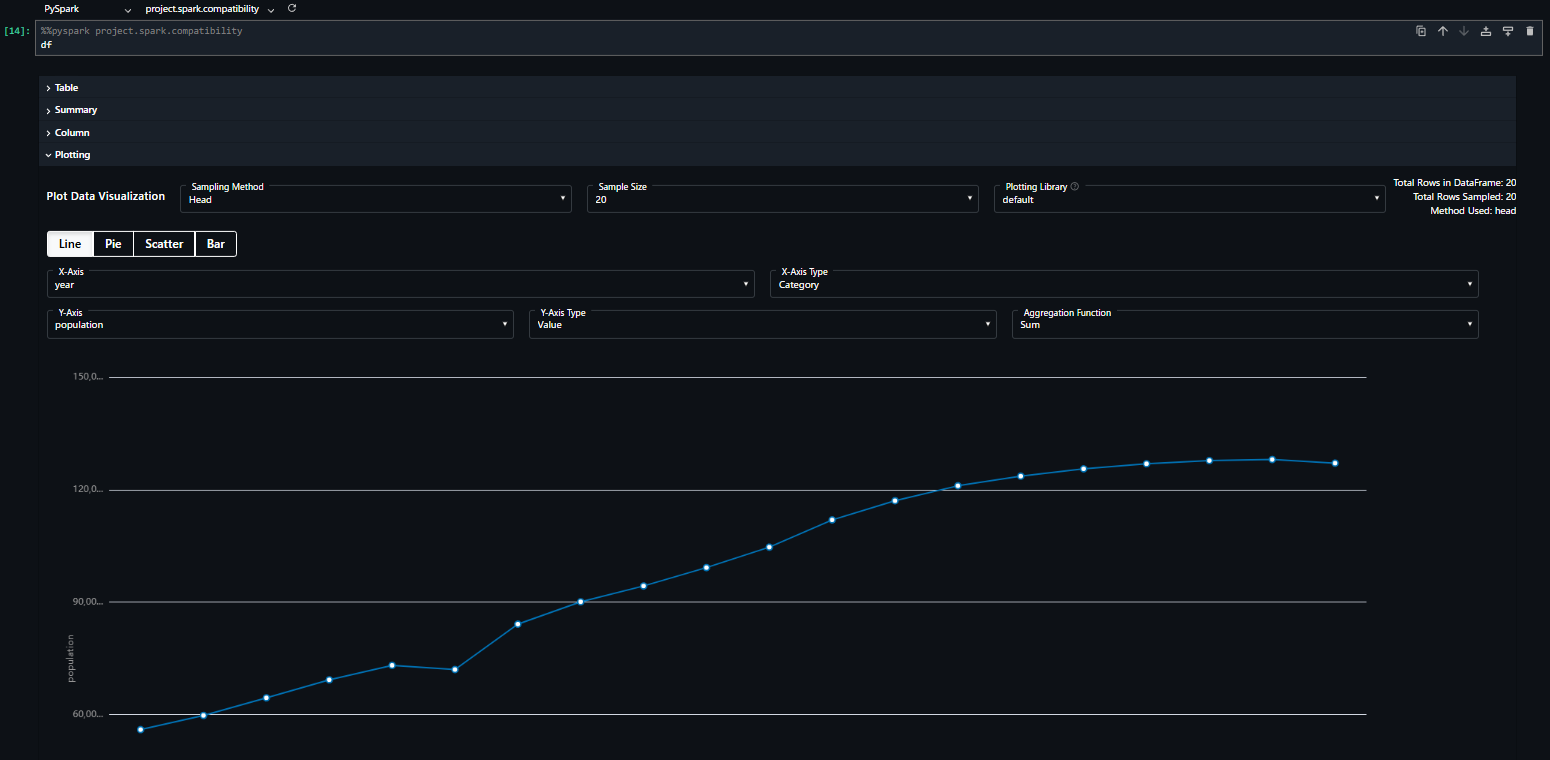
また、dfとしてデータフレームを表示させると、その場でデータの可視化を行うこともできます。表示結果の「Plotting」から設定を行うことで、以下のようにリアルタイムでグラフが表示されます。
Redshift
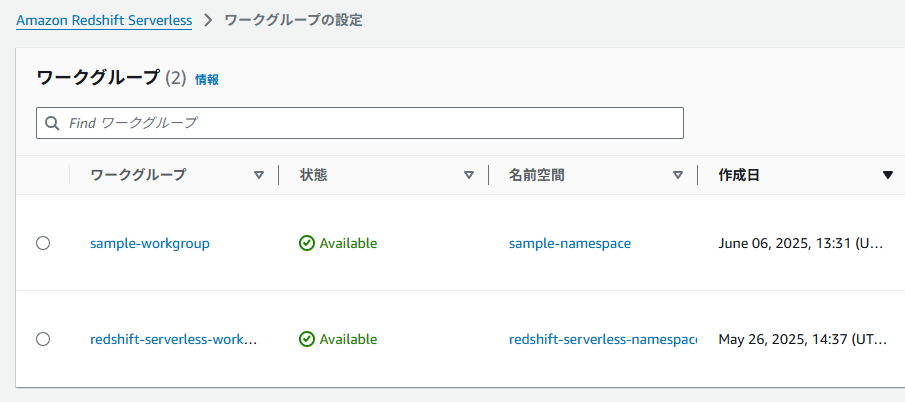
SageMaker のプロジェクト作成時にすでに Redshift ワークスペースが作成されていますが、それとは別に既存の Redshift ワークスペースを統合する場合についても検証してみます。
今回、検証用にワークグループsample-workgroupと名前空間sample-namespaceを新規作成します。
そのままではデータが何も入っていない状態のため、クエリエディタを開いて Federated User として接続し、サンプルのtickitデータを取得します。
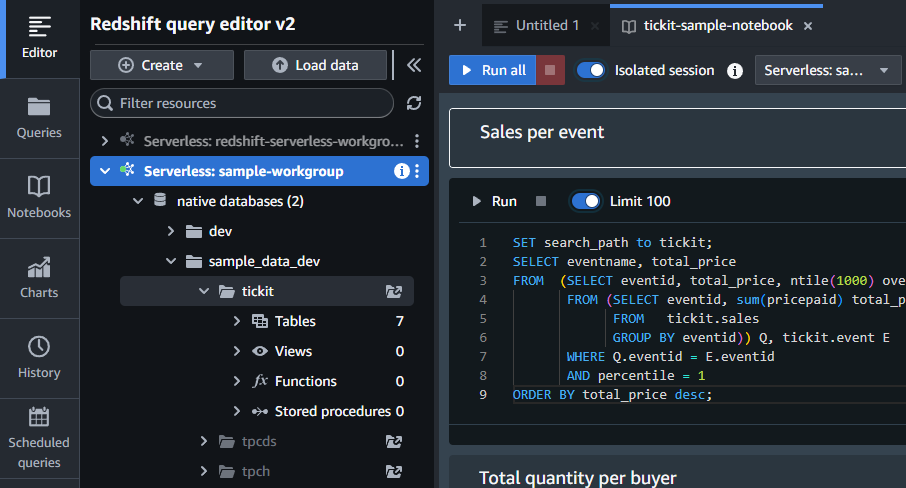
以降はこちらの記事を参考にフェデレーテッドカタログの作成と権限設定を行います。
カタログ作成と権限設定が完了すると Lakehouse に認識され、外部データソースとしてアクセスできるようになります。テーブルをクリックし、Athena や Redshift でクエリをかけることが可能です。
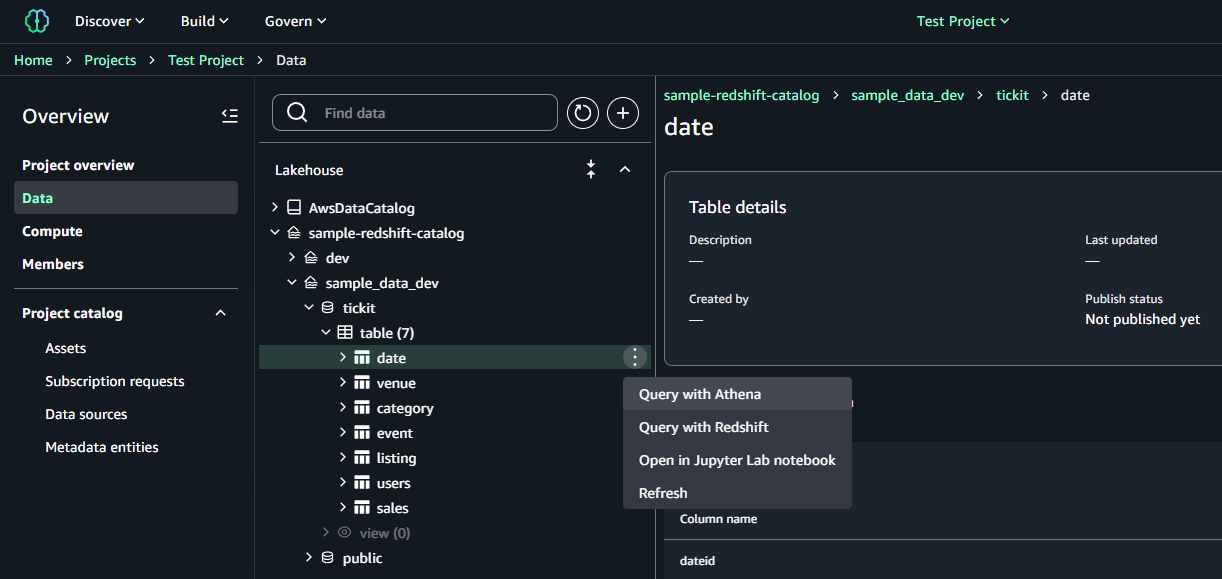
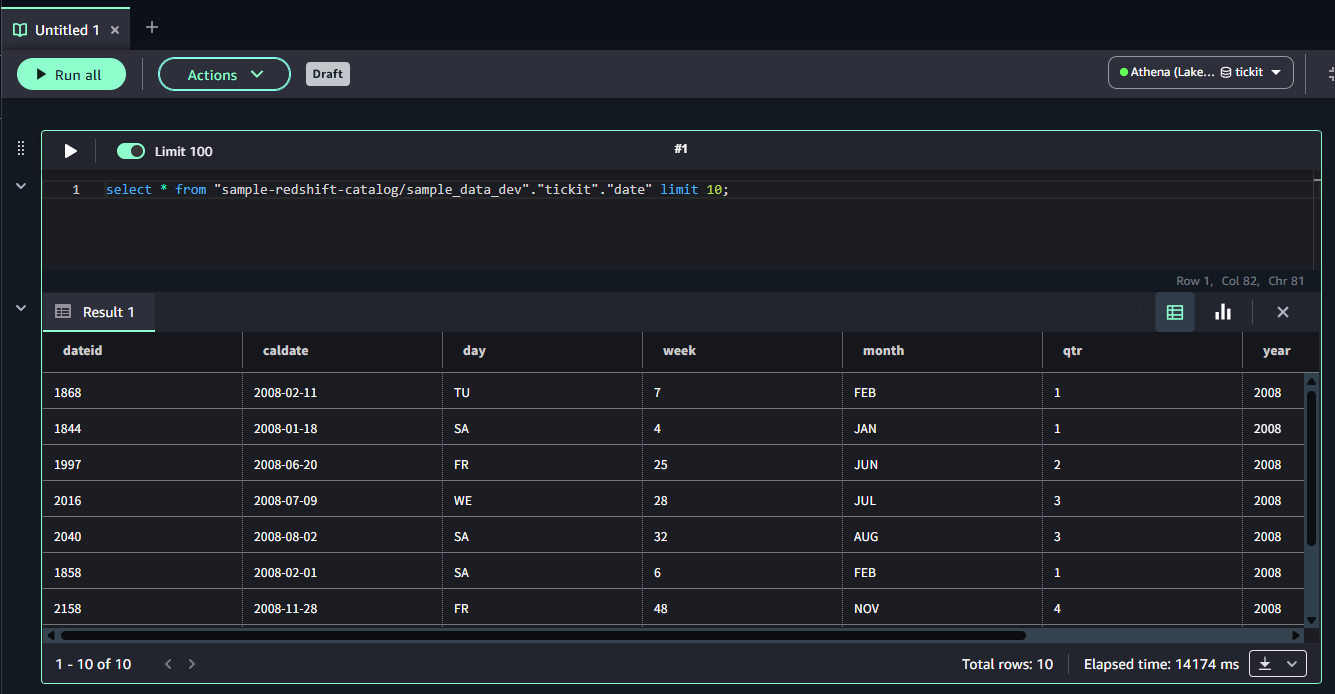
「Query with Athena」をクリックすると、SQLが自動的に生成され実行されます。
BigQuery
SageMaker Lakehouse では、BigQuery もデータソースとしてサポートされています。データソース追加の手順は以下の通りです。
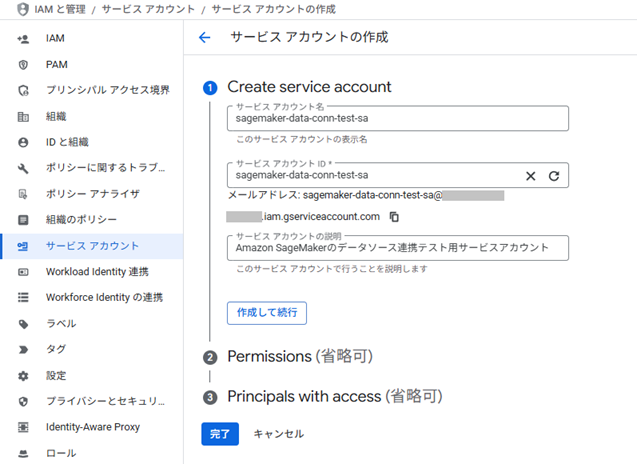
はじめに、GCP側でデータソース連携用のサービスアカウントを作成します。
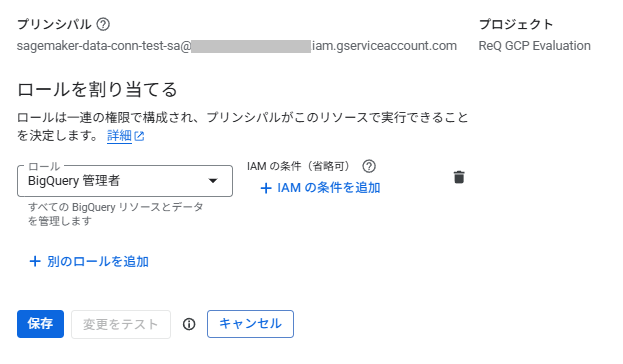
BigQuery のデータを参照できるよう、IAMで適切なロールを付与します。今回の検証では「BigQuery管理者」ロールを付与しました。
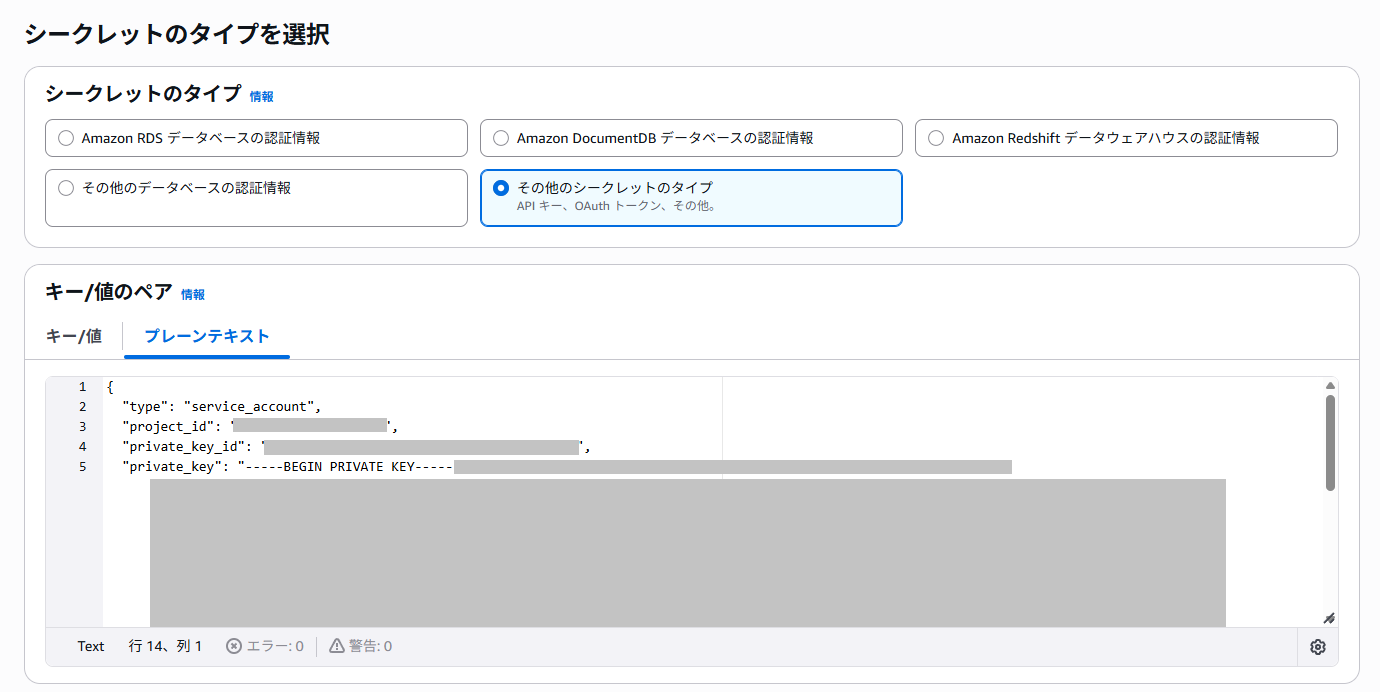
サービスアカウントを作成したら、「鍵」→「キーを追加」→「新しい鍵を作成」でキー(JSONファイル)を作成します。

作成しダウンロードしたJSONファイルのデータを Secrets Manager に登録します。
- シークレットのタイプ:その他のシークレットタイプ
- キー/値のペア:JSONファイルの中身
Unified Studio の Data タブを開き、「+」をクリックします。「Add data」が表示されるため、その中の「Add connection」を選択し次に進みます。
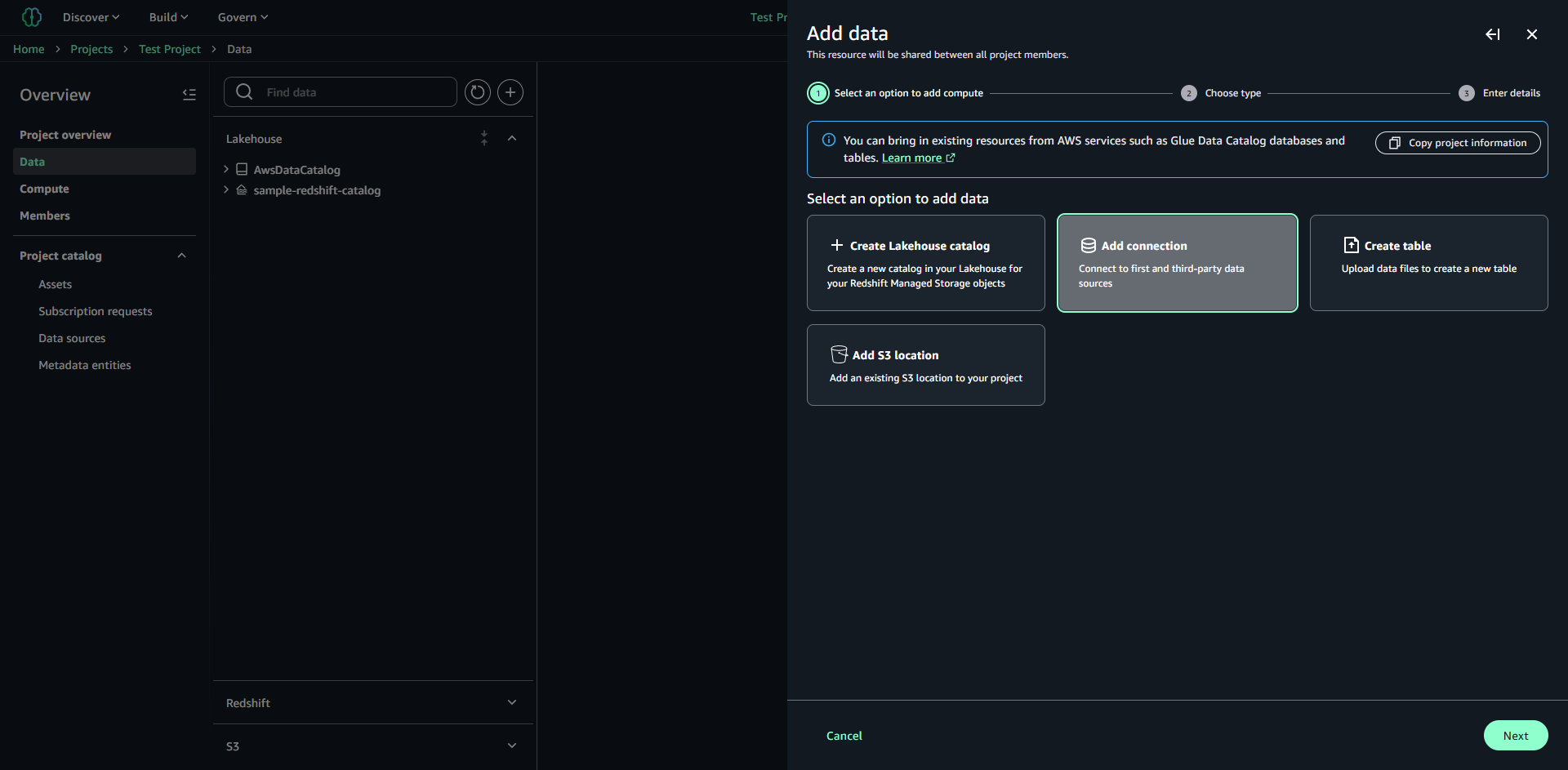
利用可能な接続タイプが表示されているため、「Google BigQuery」を選択します。
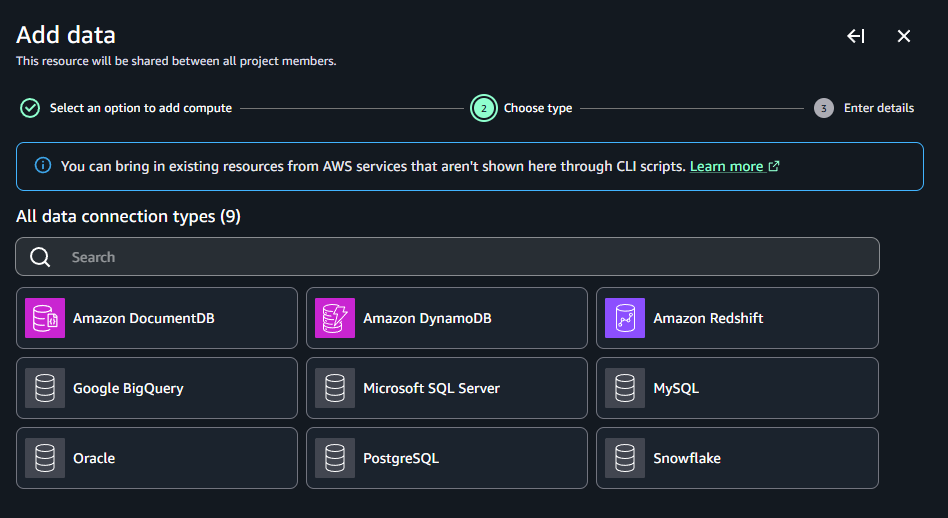
Secrets Manager の権限が必要となるため、ポリシー「SecretsManagerReadWrite」を以下のロールにアタッチしておきます。
- AmazonSageMakerProvisioning-xxxxxxxxxxxx
- datazone_usr_role_xxxxxxxxxxxxxx_xxxxxxxxxxxxxx
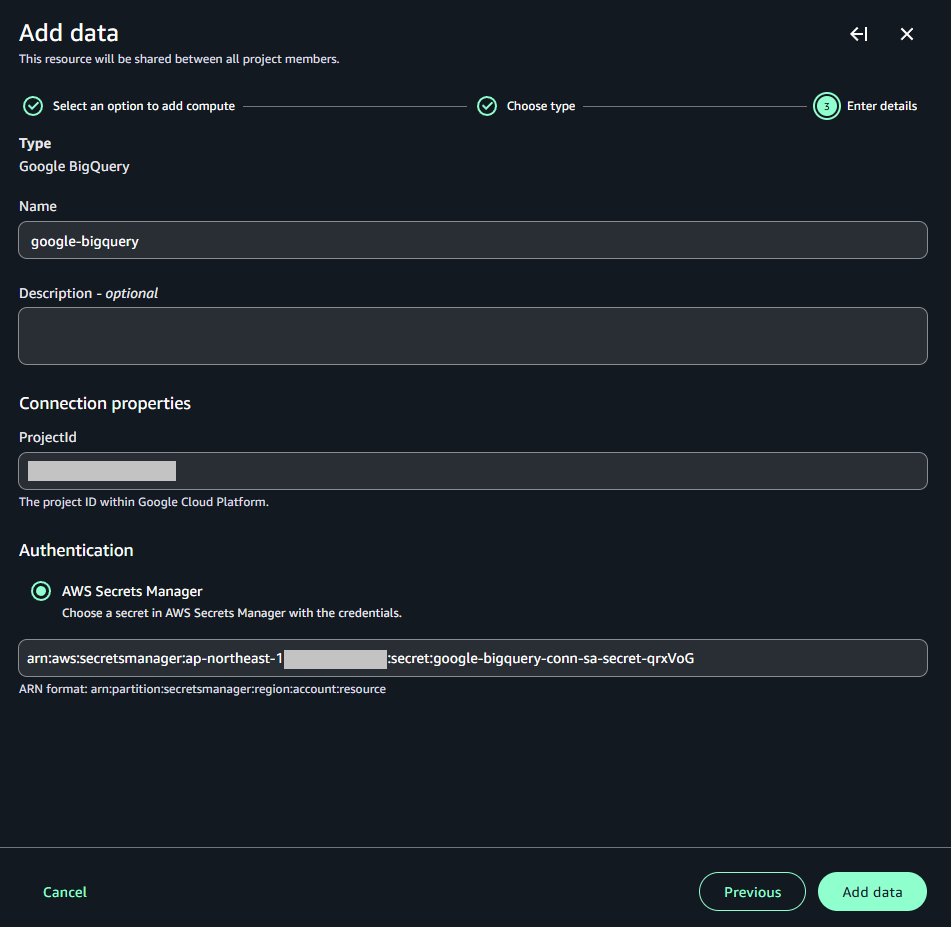
以下の設定を行い、「Add data」をクリックします。
- Name:データ名
- ProjectId:接続対象のGCPプロジェクトID
- AWS Secrets Manager:上記でJSONファイルのデータを登録したシークレットのARN
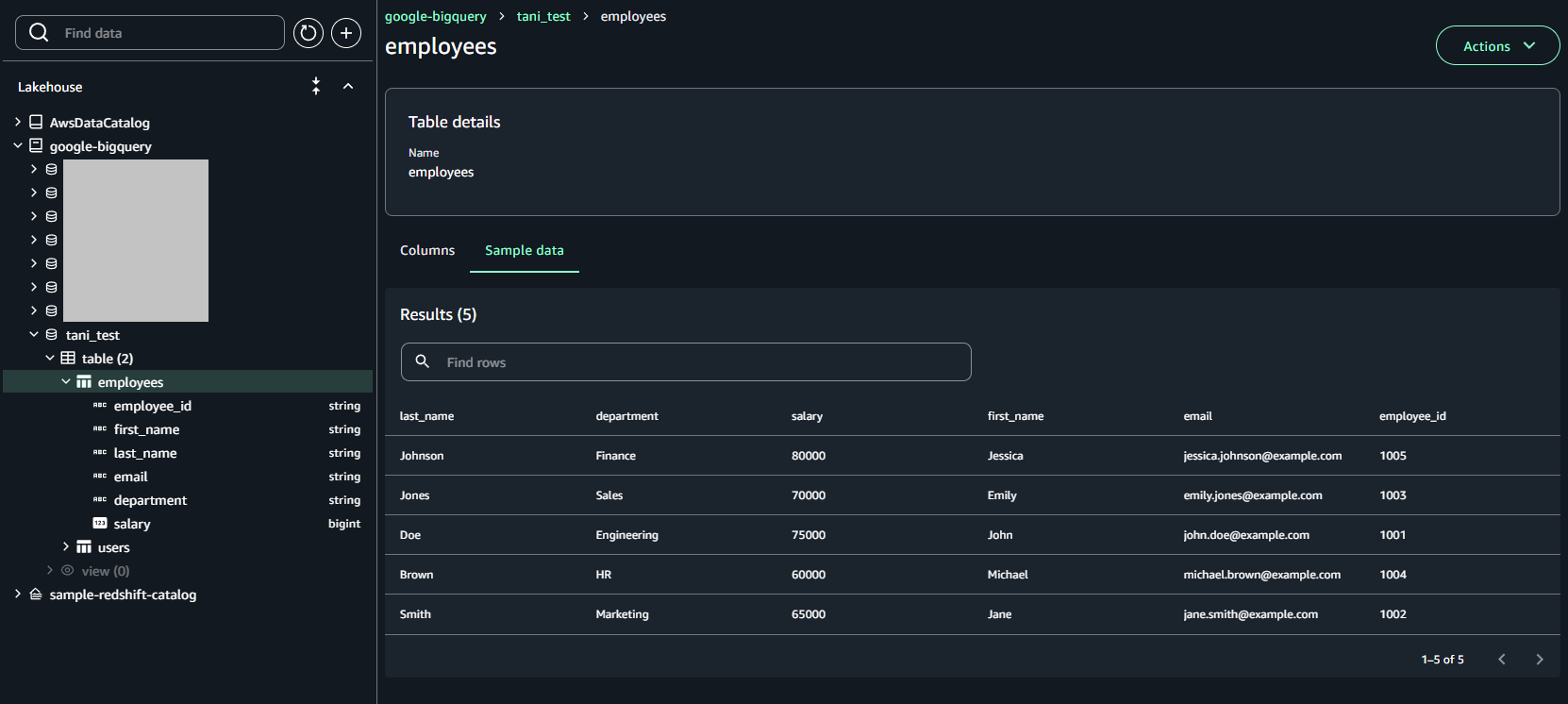
数分待つと、Lakehouse に BigQuery のデータソースが表示されます。データソースを開くと、データセットとテーブルを BigQuery 上と同じように確認することができます。
その他
上記以外に連携可能な外部データソースは下記ページに記載の通りです。
Data connections in Amazon SageMaker Lakehouse - Amazon SageMaker Unified Studio
ゼロETL統合
ゼロETL統合を通じて、様々なデータソースから Lakehouse にデータを取り込むことが可能です。ゼロETLという名前の通り、対象データソースからETL処理をはさまずに指定した形式で直接データを取り込むことができます。
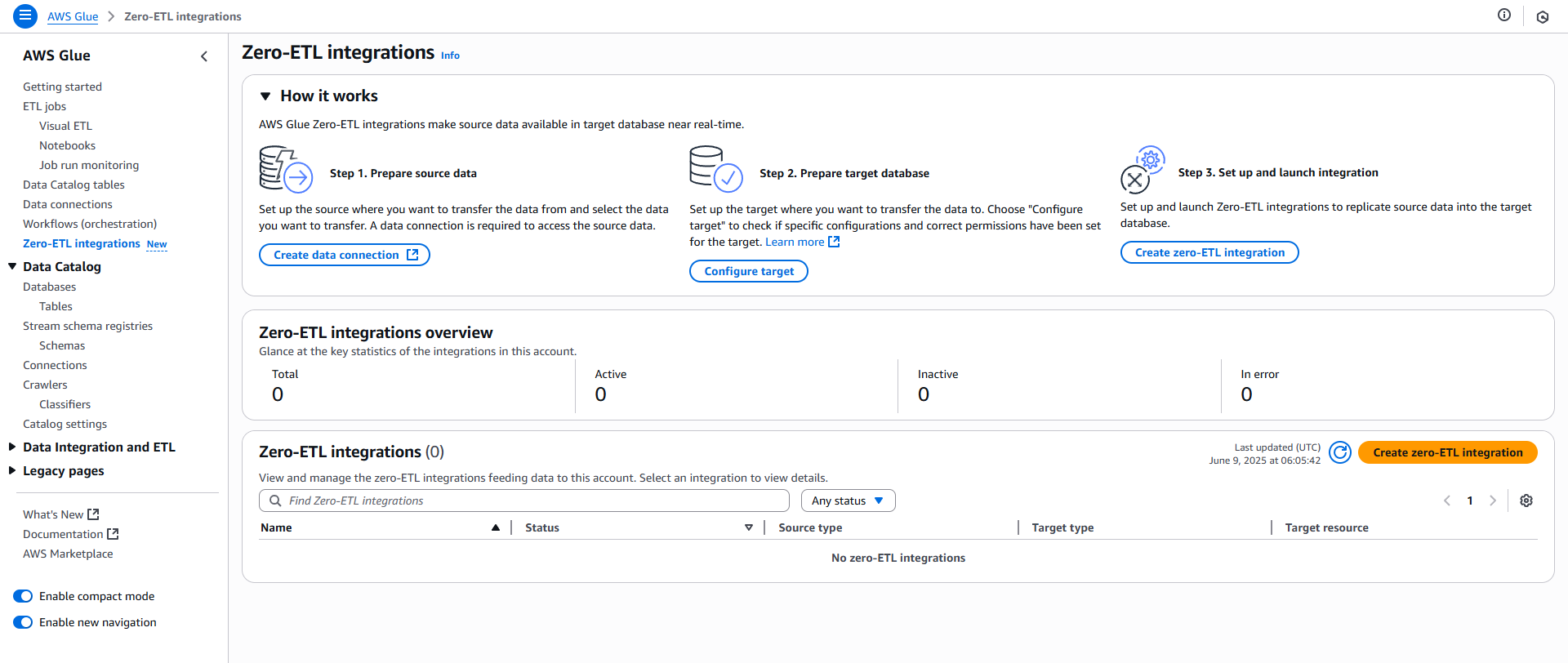
AWS Glue の Zero-ETL integrations から設定可能です。以下の3ステップで設定を行います。
- ソースデータへのデータ接続を作成
- ターゲットデータベースを設定
- ゼロETL統合の作成
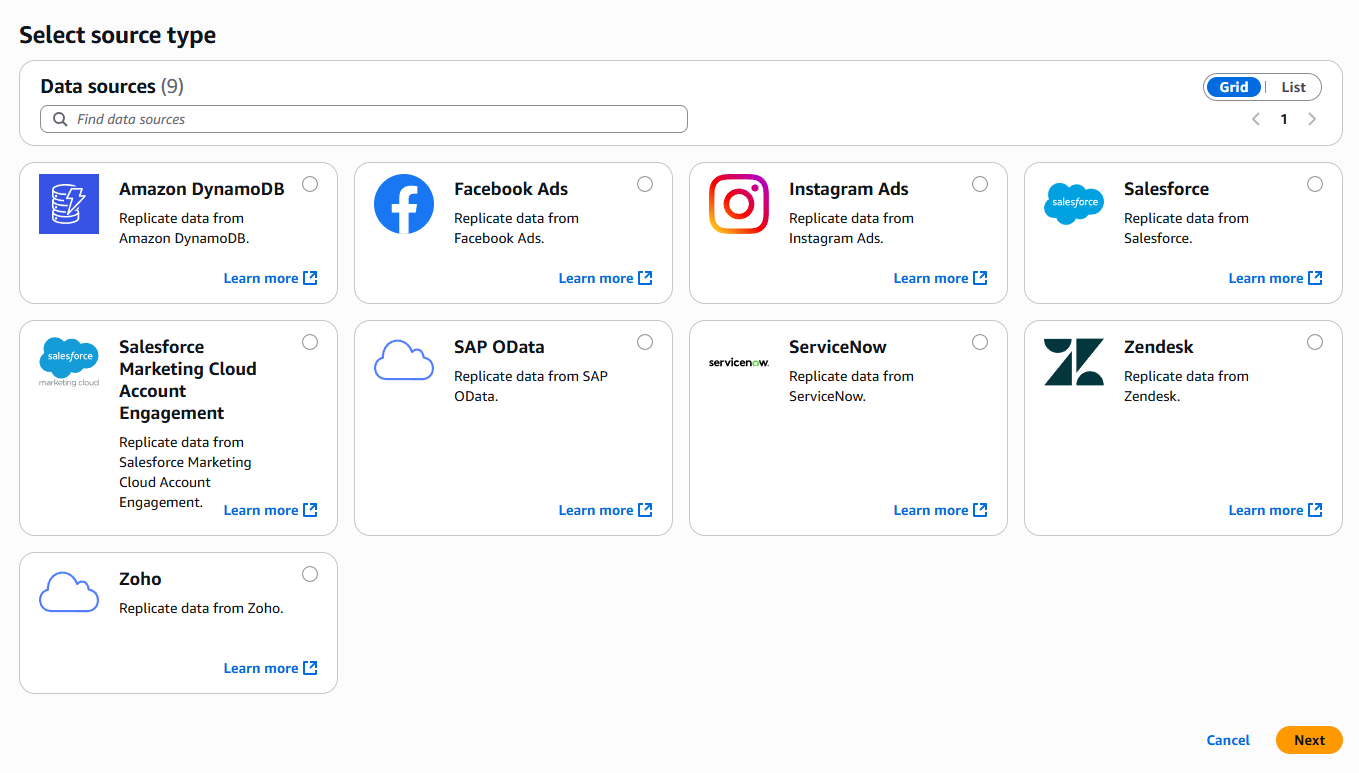
現時点でサポートされているソースは以下の通りです。
補足
SageMaker Lakehouse は Glue Data Catalog と Lake Formation を基盤として構築されています。そのため Lake Formation でカタログの作成と権限設定を行うことで、SageMaker Lakehouse から対象データソースにアクセスできるようになります。
データソースの設定は対象によって少し違いますが、以下の基本的な流れは同じです。
- データソース接続設定
- データソースに対する権限設定
さいごに
SageMaker Lakehouse とはどのようなものか、実際にデータ取り込みやデータソースの設定を行いながら見てきました。最初はどこか漠然としていてイメージが掴みにくいと思いますが、本記事を通して少しでも実感を持てていただけたら幸いです。
参考
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

