Snowflake Snowpark の概要と使い方の基本
2025.04.25
- Snowflake
- クラウド
- データエンジニアリング
Snowpark は Snowflake が提供する開発フレームワークです。Snowflake の処理エンジン内でSQL以外の開発言語のコードを実行することができます。現時点で Python, Java, Scala をサポートしています。
Snowpark の語源は Snowflake + Spark であり、大量のデータを分散処理によって効率的に処理可能な Apache Spark の仕組みを Snowflake 上で実現したものです。そのため、Spark と同じ感覚でデータフレーム等の操作を行うことができます。
Snowpark 活用のメリットとして、大きく以下の3点が挙げられます:
- 統一されたマネージド環境のため、スムーズな開発が可能
- Snowflake 内部で処理が完結し、データに対するガバナンスとセキュリティが担保される
- データ処理のために Snowflake 以外の場所にデータを移す必要がなく、運用が効率化される
Snowpark はクライアントライブラリとコード実行環境を提供しており、ユーザは Snowpark API を利用してデータを DataFrame 形式で処理したり、Snowpark ML API を利用して機械学習の一連のタスクを実行したりすることができます。
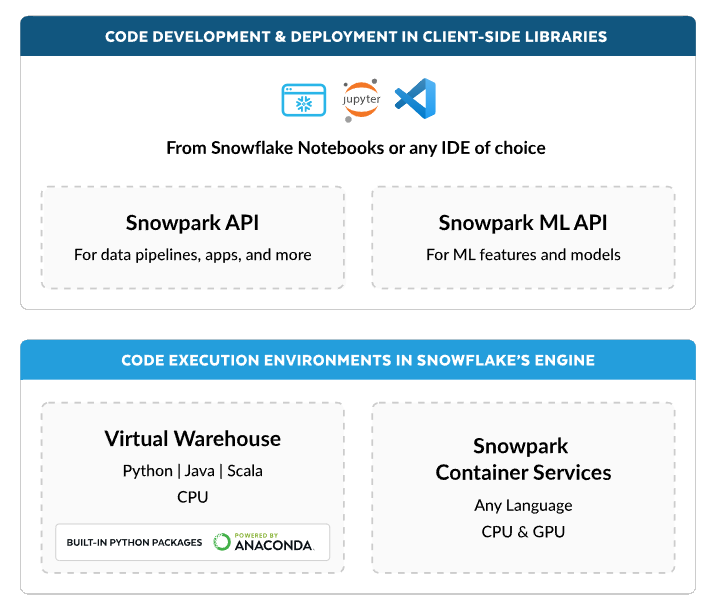
※Snowpark:Python、Java、Scalaなど、任意の言語での構築を実現より引用
使い方
さっそく、実際の使い方について見てみましょう。
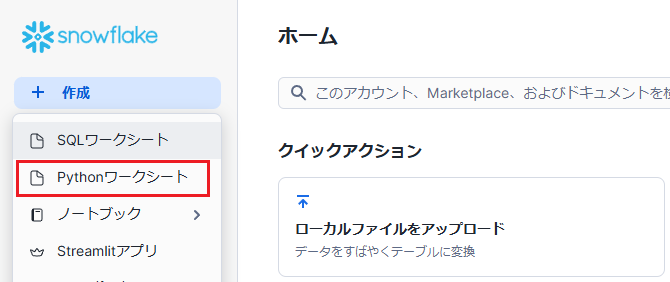
メニューの「作成」→「Pythonワークシート」をクリックします。
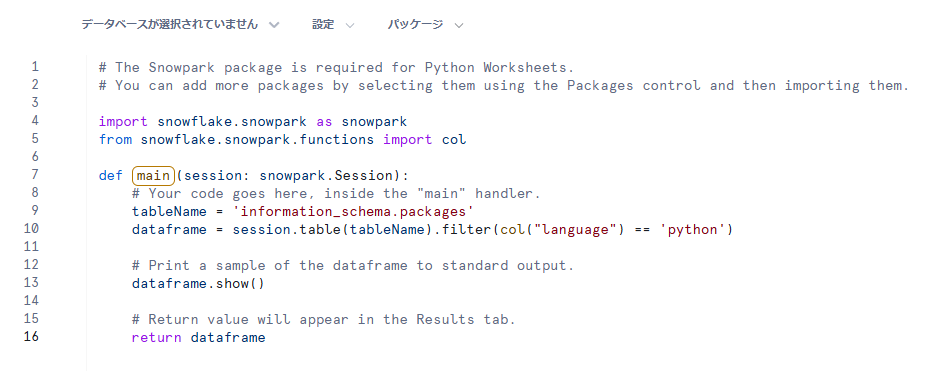
以下のようにサンプルコードが記載されたワークシートが作成されます。
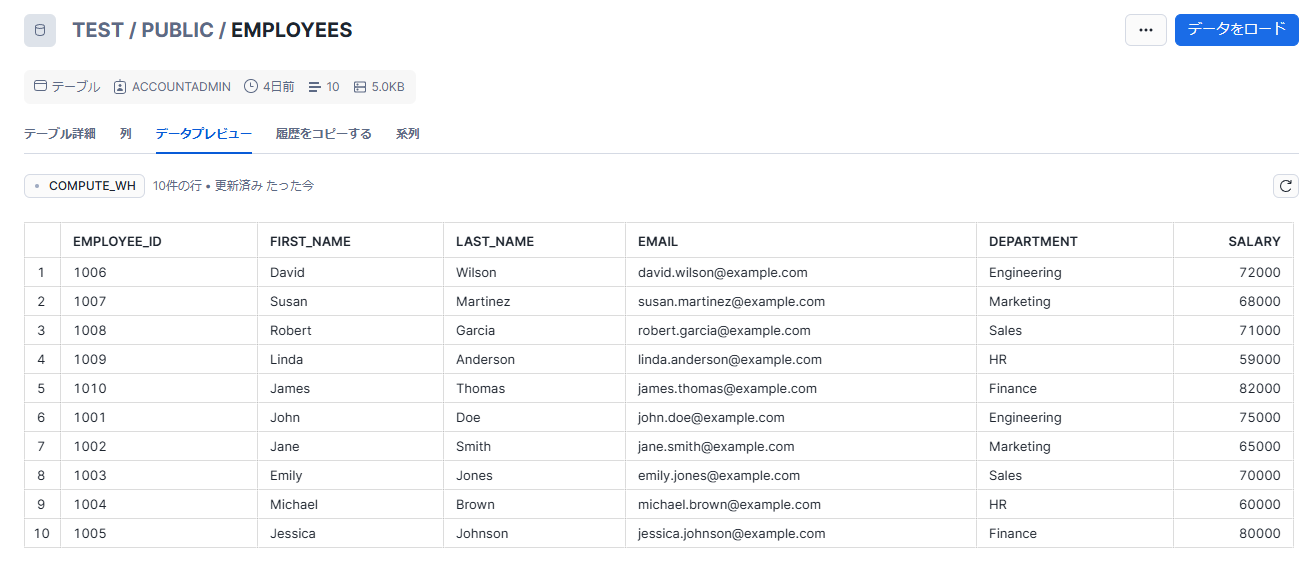
今回はサンプルコードをもとに、以下のemployeesテーブルに対して処理を行うコードを作成してみます。
作成したコードは以下の通りです。
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import avg
def main(session: snowpark.Session):
# 部門ごとの平均給与を算出
df = session.table('employees')\
.group_by("department")\
.agg(avg("salary").alias("avg_salary"))\
.select("department", "avg_salary")
# 途中結果を出力
df.show()
# 結果をテーブルに書き込む
df.write.mode('overwrite').save_as_table('salary_by_department')
return df
部門ごとの平均給与を算出した結果をデータフレームdfとして取得し、それをもとにテーブルsalary_by_departmentを作成します。
show()というのはデータフレームの内容を出力するためのデバッグ用の関数です。
上記を実行すると以下の結果が得られます。
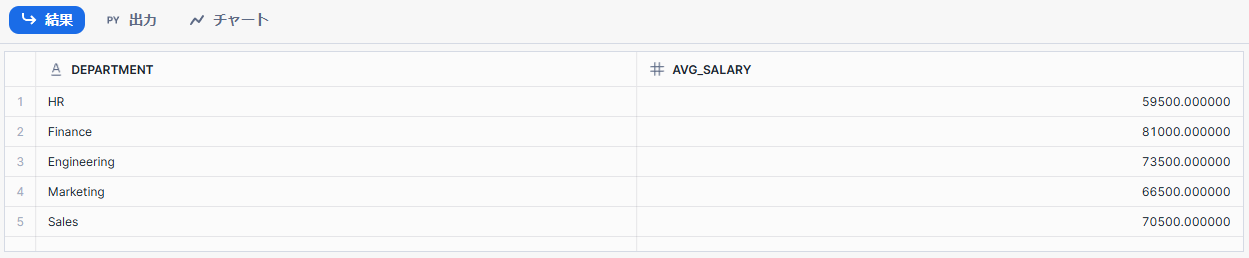
想定通りの結果が得られていることを確認できました。
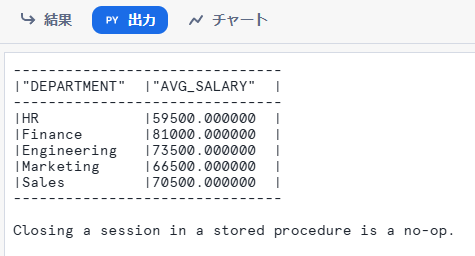
また、「出力」タブで処理の出力を確認することが可能です。show()の内容はここに表示されます。
補足
main関数が処理のエントリポイントとなっており、ワークシートを実行するとmain関数内の処理が実行されます。
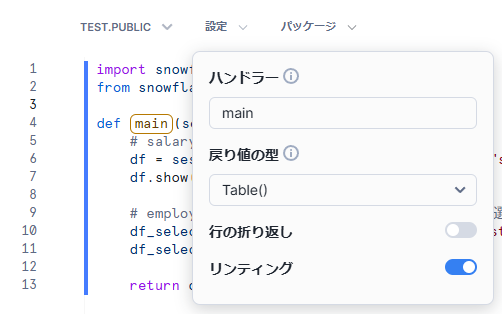
エントリポイントはワークシートの「設定」タブの「ハンドラー」から変更可能です。helloという関数を作成し、ハンドラーをhelloにすればその関数が実行されます。
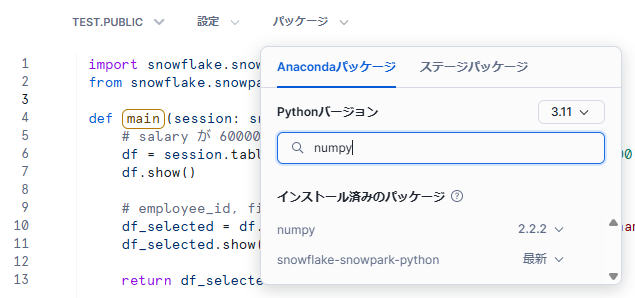
また、「パッケージ」タブから Python のバージョン変更やパッケージの追加を行うことが可能です。「ステージパッケージ」で独自のパッケージをインポートして利用することもできます。
その他、Snowpark API で使用されるオブジェクトや関数の詳細については Snowpark APIs のドキュメントをご参照ください。
まとめ
Snowpark は Snowflake が提供する開発フレームワークであり、Snowpark を活用することで統一された環境でスムーズな開発ができるだけでなく、必要なデータ処理が Snowflake 内部で完結することでセキュリティと運用効率を向上させることができます。
また、Snowpark は Apache Spark と同様の仕組みで実現されており、Pandas などの通常のデータフレームと違い大規模データに対しても効率的に処理を実行することが可能です。
Snowpark について初めて知ったという方や、今まで Snowflake 外部のサービスを使ってデータ処理を行っていたという方は、この機会に Snowpark の利用も検討してみてください。
参考
RELATED ARTICLE関連記事
RELATED SERVICES関連サービス


Careersキャリア採用


この記事をシェアする

