2021年9月17日に、ITmediaにホワイトペーパー「オンプレOracle DBからAmazon AuroraへのDB移行 困難が予想されるプロジェクトを成功させるには」を掲載しました。
ホワイトペーパーはこちらからダウンロード頂けます。
https://wp.techtarget.itmedia.co.jp/contents/58286
「システム基盤構築のプロフェッショナル」レック・テクノロジー・コンサルティングJapanese | English


HOME > 技術ブログ > 月別アーカイブ: 2021年9月
2021年9月17日に、ITmediaにホワイトペーパー「オンプレOracle DBからAmazon AuroraへのDB移行 困難が予想されるプロジェクトを成功させるには」を掲載しました。
ホワイトペーパーはこちらからダウンロード頂けます。
https://wp.techtarget.itmedia.co.jp/contents/58286
皆さん、こんにちは。クラウド基盤技術部のT.W.です。
少し遅くなりましたが、今回は2020年末にAWSが発表した新しいETLサービスAWS Glue DataBrewを検証してみました。 内容は少し長いので、パート1とパート2を分けて投稿しようと思います。
パート1で「AWS Glue DataBrewとは何か」を軽く紹介させて頂き、パート2で実際に検証した内容とその感想を皆さんにお届けしようと思います。
AWS Glue DataBrewを紹介する前に、今までのデータ分析や機会学習の一般的な流れを振り返りましょう。 まず、大規模なデータ抽出・ロードを行い、そのデータをクリーニング・加工変換して、データウェアハウス・データレイクに準備したデータを流し込みます。 更に、データ量が多くになるにつれて、スケールアウトができるようにオーケストレーションの仕組みを実装するのが一般的です。
このとき、ETL開発者やデータエンジニア、そして場合によりインフラエンジニアが、基盤および大規模かつ複雑なデータパイプラインを構築することになります。 言い換えると、データクリーニングやデータ統合にコーディングが必要となり、専門的なスキルがないとなかなか対応が難しいのが現状です。
その後、データパイプラインで処理したデータはデータ分析や機会学習に利用されますが、データエンジニア、ETL開発者、データアナリスト、データサイエンティストなどチーム間でデータが行き来する過程でさらに細かい要件が追加され、さらに大規模なデータ処理をすることで、膨大な工数やリソースが消費され、結果としてゴールがなかなか見えないという状況に陥りがちです。
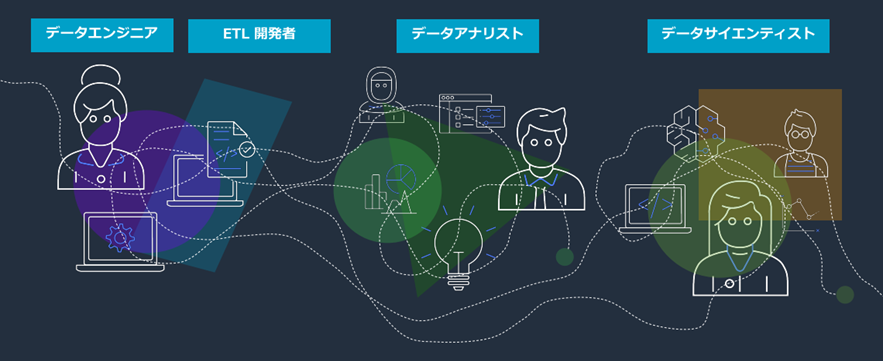
ということで、これまでの伝統的なデータ準備の課題をまとめると以下の通りです。
前述の様々な課題を解決するために誕生したのが、AWS Glue DataBrewというフルマネジメントETLサービスになります。 一言で言うと、「データのクリーンアップおよび正規化を最大80%高速化する、簡単なビジュアルデータ準備ツール」とも言えます。 AWS Glue DataBrewの特徴としては、データ準備をノンコーディングで高速に行えるほか、以下の4つの利点があります。
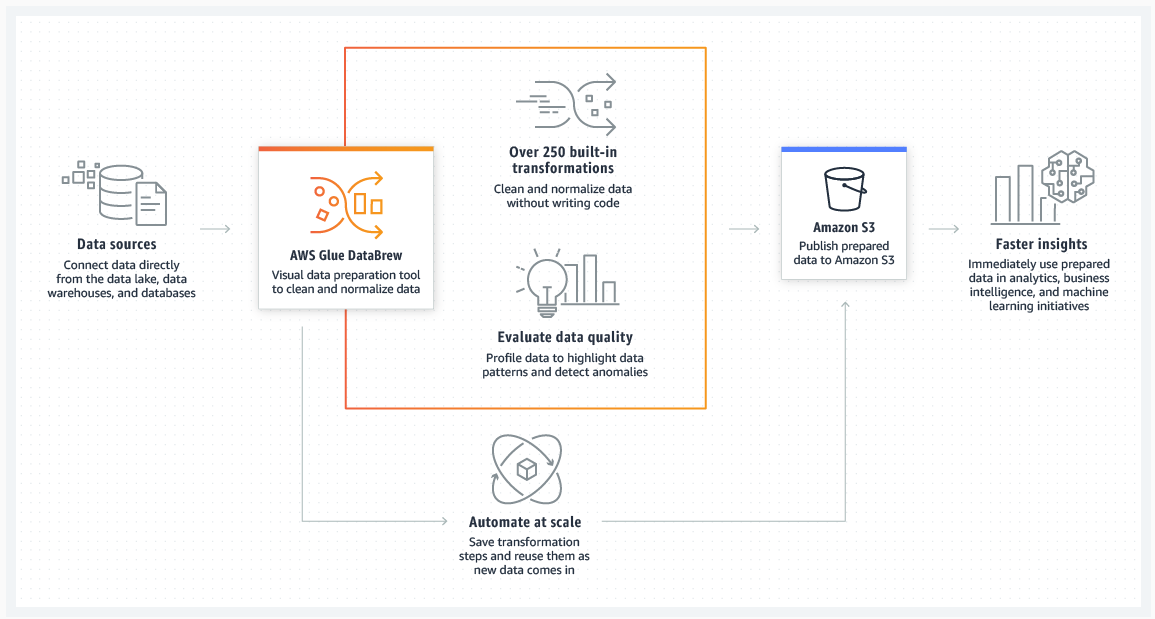
AWS Glue DataBrewを使用するにあたり、最低限、以下の4つのキーワードを覚えておくといいでしょう。
データを変換する際の一連の"ステップ"を指します。
データのクリーンアップや正規化などの変換に関するステップをまとめたレシピを作成するためのワークスペースを指します。
AWS Glue DataBrewが利用するテーブルのように構造化されたデータの集合体です。
ジョブはレシピジョブとプロフィールジョブの2種類があります。
レシピジョブ:データセットに対してレシピで設定した命令を実行してデータ変換を実行する。 プロフィールジョブ:データの現状を示す概要と統計を生成する。
今回の検証はレシピジョブを中心に行っていきます。
AWS Glue DataBrewによるデータ変換ステップは、以下の3ステップです。
まず最初に、データをAWS Glue DataBrewに認識させる必要があります。 方法は、データセットへの接続と、データベースへの接続の2パターンがあります。
データセットへの接続は、主にAmazon S3に格納しているCSV、TSV、JSON、Apache Parquetのファイル/フォルダを示す「S3パス」か、正規表現を用いた「パラメータ化されたS3パス」を指定します。
データベースへの接続は、GlueデータカタログやAWS Glue Database connections・JDBCなどで接続可能です。
AWS Glue DataBrewの最も重要な機能は、データ変換です。 現在の代表的な変換処理は下記の通りですが、今後、対応可能な処理は増えていくと思います。
今回は上記の変換処理を一つずつは説明しませんが、可能な限り、次回の検証時に説明できればと思います。
AWS Glue DataBrewで処理したデータは基本的にはS3へ出力されますが、その際、ォーマットの指定が可能です。 本ブログを執筆時点でサポートされているフォーマットは、CSV、Apache Avro、XML、JSONなどです。
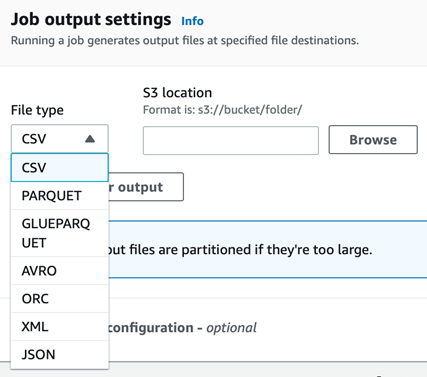
詳細は以下のURLをご覧ください。 https://docs.aws.amazon.com/databrew/latest/dg/jobs.html
ETLツールはライセンス費用が非常に高額で、予算がないとなかなか手付けられない...と考える方もいらっしゃると思います。 しかし、AWS Glue DataBrewは、ほとんどのAWSサービスと同じく従量課金(pay-as-you-go)で、使った分だけが課金対象になります。 ですので、ライセンス費用やインフラ設備などの初期投資が必要ありません。
AWS EC2でのDataBrewジョブ課金の例を紹介します。 ジョブの実行に使用されるAWS Glue DataBrewのノードに対して1時間ごとに発生する料金は、現時点で$0.48になります。 ジョブ実行処理が完了すると自動的に停止してくれます。 1ノードのスペックは、4vCPUs、16GBメモリです。
それと別に、AWS Glue DataBrewを操作するための画面の利用料金が発生します。 DataBrewインタラクティブセッションと呼ばれるもので、料金は$1/30分です。 DataBrewプロジェクトを開くとセッションが開始され、未操作の時間が続いた場合は自動的にサスペンドとなります。 サーバの起動停止の操作はありません。
料金の詳細については、以下のURLにてご確認ください。
https://aws.amazon.com/jp/glue/pricing/
AWS Glue DataBrewは、データのクリーンアップ、およびわかりやすいビジュアルインターフェースにより、データの整形・正規化を最大 80%高速化するビジュアルデータ準備ツールです。 250種類以上の組込変換処理を使うことで、データアナリストやサイエンティストがコーディングを行うことなく、簡単にデータを整形できます。 更には、アドホックなデータ探索、データの品質チェック、機械学習モデル構築の前処理、データ分析パイプラインの構築など、さまざまな用途にあわせたデータセットを作成できます。
いかがでしたか? 次回は、実際にAWS Glue DataBrew環境を使ったデータ処理について皆さんにお届けしたいと思います。
お楽しみに。
AWS Glue DataBrewの紹介(1)2021年9月7日に、「レック、クラウド基盤サービスを強化」
2021年9月1日に、ITmediaにホワイトペーパー「
ホワイトペーパーはこちらからダウンロード頂けます。
https://wp.techtarget.itmedia.

| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
|---|---|---|---|---|---|---|
| « 5月 | 10月 » | |||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | ||
