2021年5月24日に、SCSK様との協業による「Google Cloud向け移行支援サービス ~お客様のデジタルトランスフォーメーション推進をサポート~」に関するプレス・リリースを発表しました。
記事はこちらからご覧頂けます。
SCSK様と協業による「Google Cloud向け移行支援サービス」の提供開始「システム基盤構築のプロフェッショナル」レック・テクノロジー・コンサルティングJapanese | English


HOME > 技術ブログ > 月別アーカイブ: 2021年5月
2021年5月24日に、SCSK様との協業による「Google Cloud向け移行支援サービス ~お客様のデジタルトランスフォーメーション推進をサポート~」に関するプレス・リリースを発表しました。
記事はこちらからご覧頂けます。
SCSK様と協業による「Google Cloud向け移行支援サービス」の提供開始皆さん、こんにちは。クラウド基盤技術部のT.W.です。
弊社ではGoogle Cloud Platform (以下、GCP)を使ったシステム提案/開発に注力しており、各種イベントやGCPサービスを展開しております。
技術ブログでもGCP関連のネタを随時公開していきますので、是非ご活用下さい。
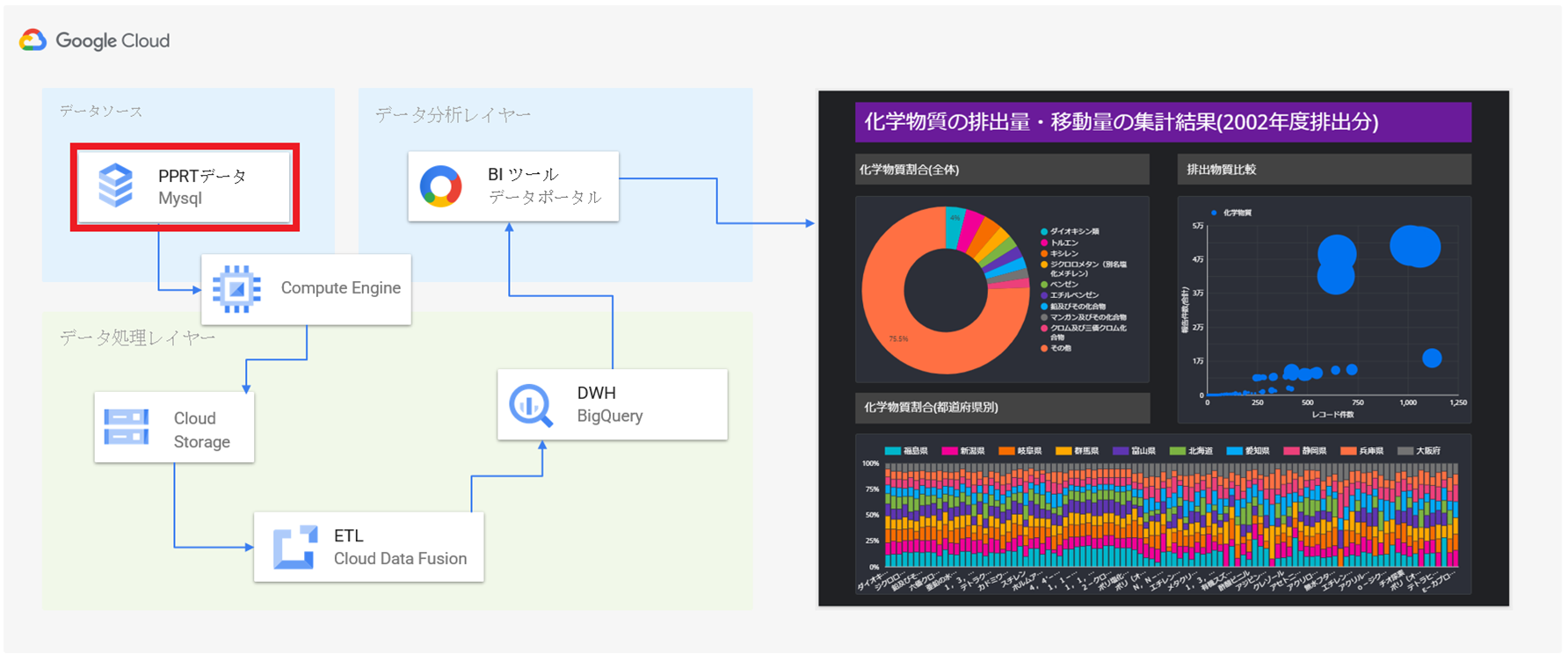
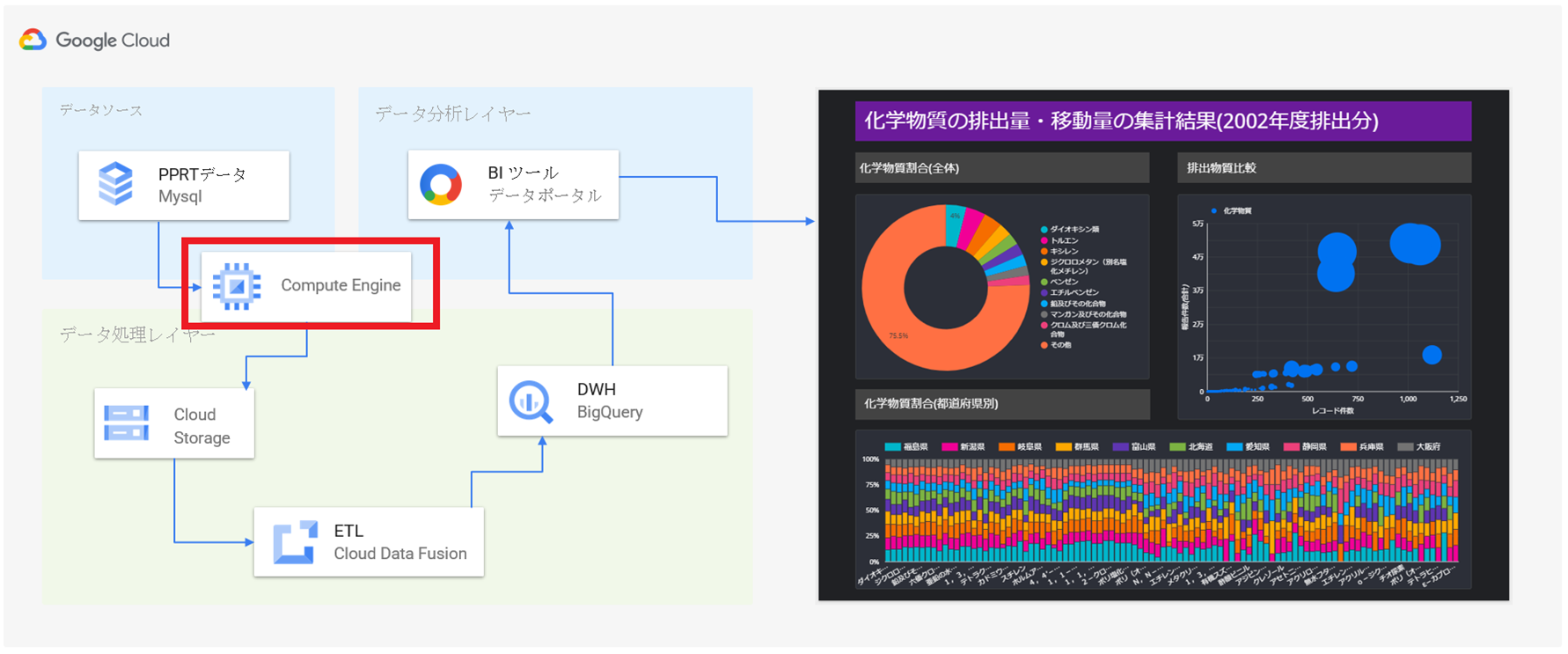
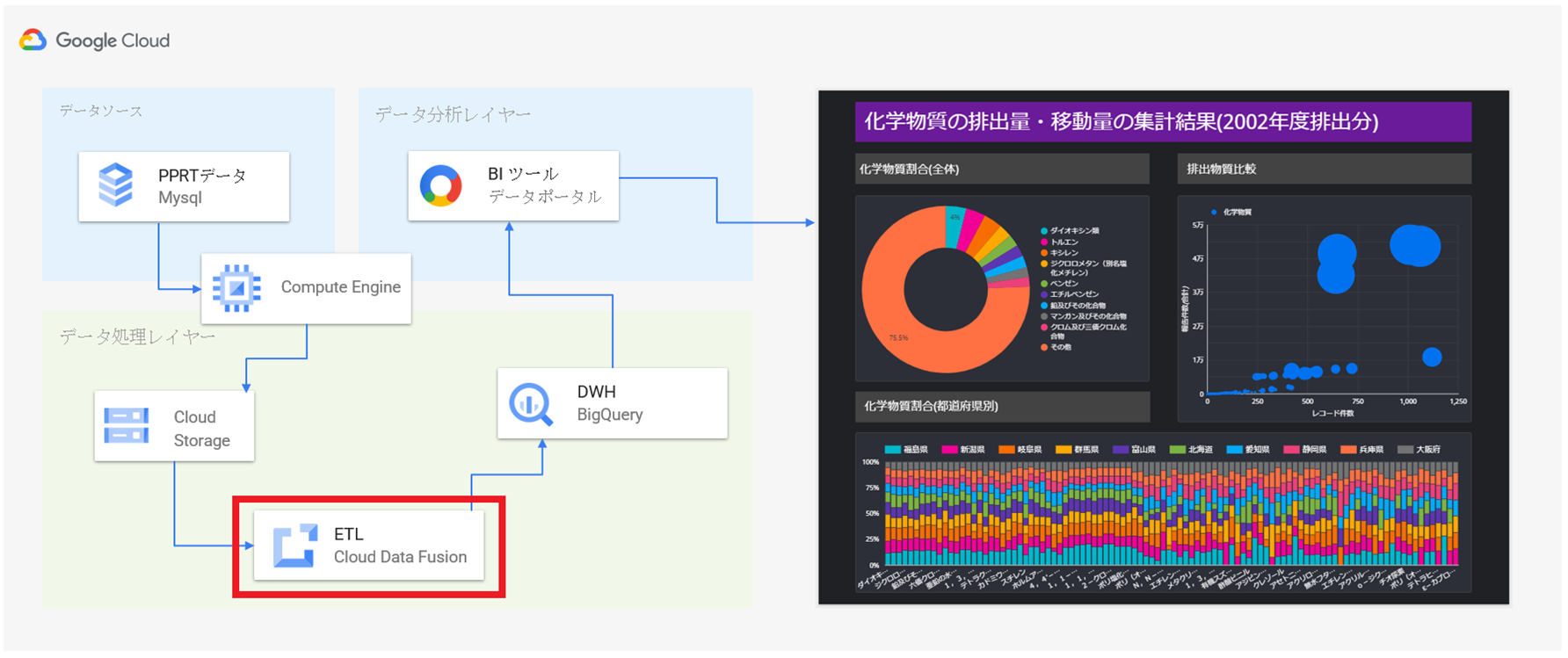
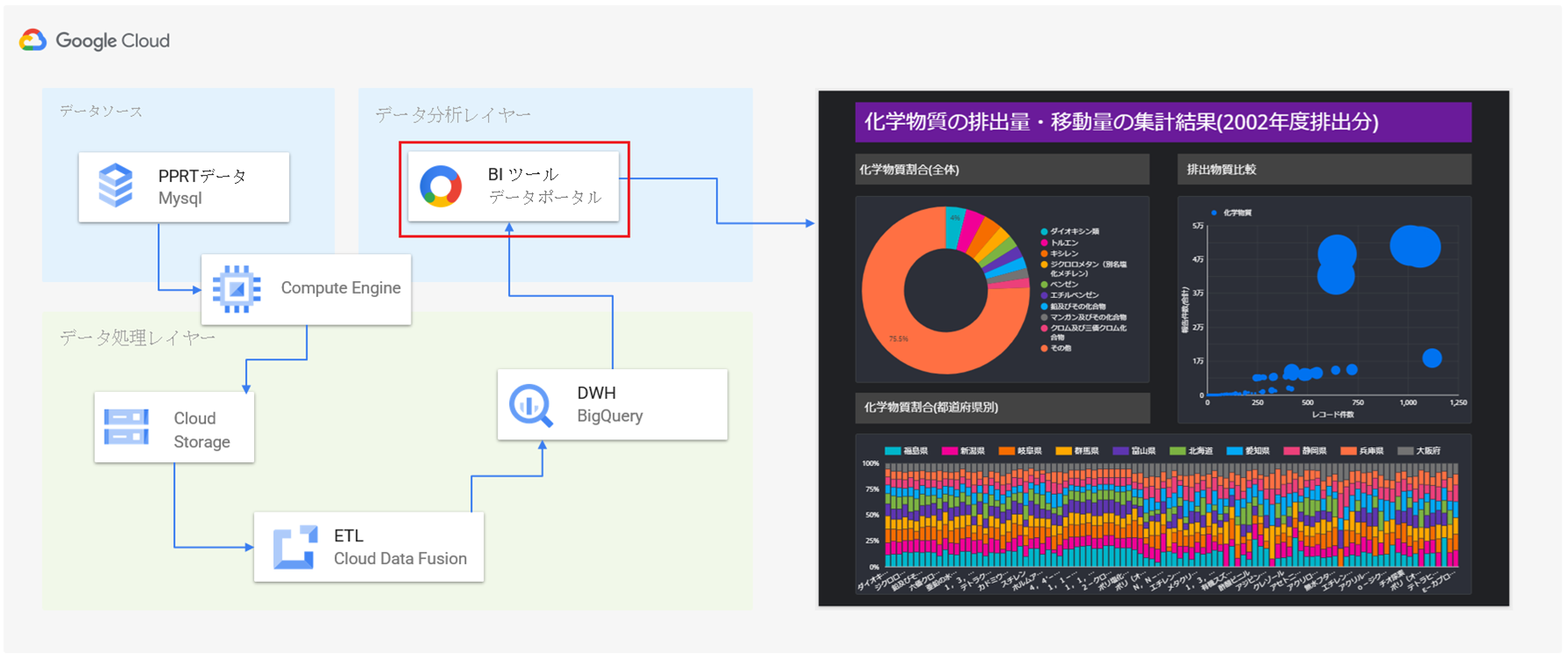
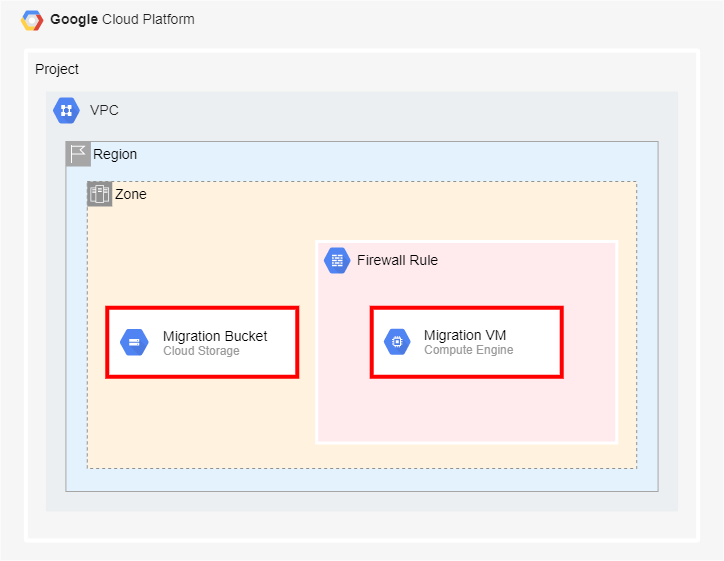
GCP内に閉じた環境で迅速なデータ分析基盤構築と安価に構築できるデータ分析基盤の構築
GCP BigQuery(データウエアハウス)
GCP Cloud Data Fusion(ETL/抽出・変換・格納)
GCP Cloud Storage(データストレージ)
GCP Compute Engine(仮想マシン)
GCP Cloud SQL (データベース MySQL)
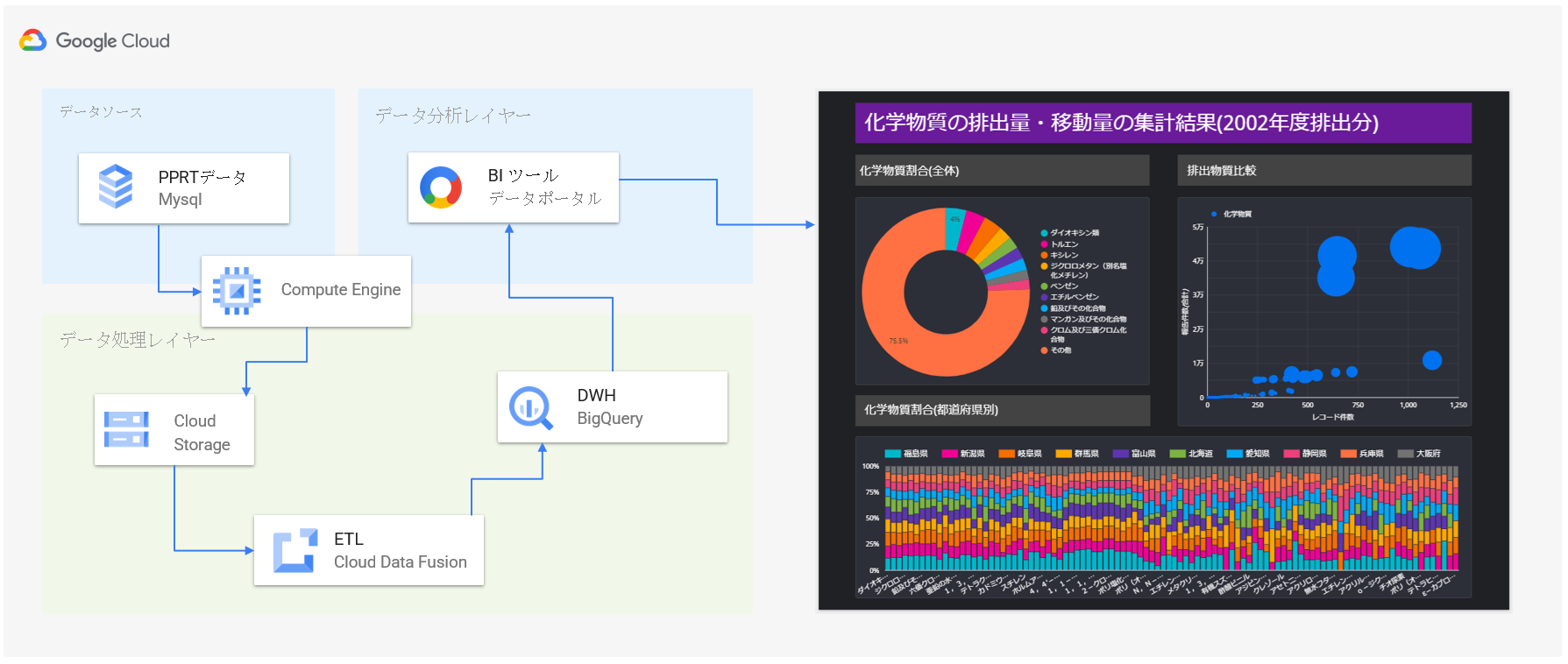
まず初めに、今回の検証におけるデータの一連の流れを軽く説明します。
今回は、検証に利用するデータをデータカタログサイトから取得して、MySQLのデータベースに格納し、これをデータソースとして検証を実施します。
具体的には、データソースからSQLで必要なデータのみを抽出して、CSV形式でCloud Storageに格納し、このデータを取得、解析、加工して、BigQueryに投入します。
BigQueryに格納しているデータを如何に見える化・可視化するかは、Google社が提供する無料のBIツール「データポータル」を利用します。
最終的に、データポータルで作成したグラフなどの分析情報を分析依頼者に共有して完了とします。
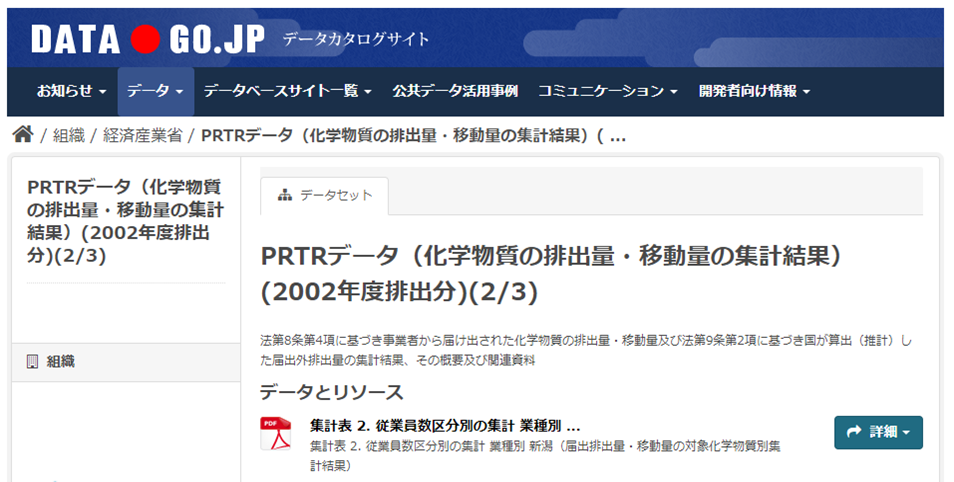
https://www.data.go.jp/data/dataset/meti_20141009_0022
機能検証の段階では、なかなか本番システムのマスタデータを使用するのは難しいと思います。
そこで今回は、日本政府が二次利用が可能な公共データの案内・横断的検索を目的で公開しているオープンデータを利用します。
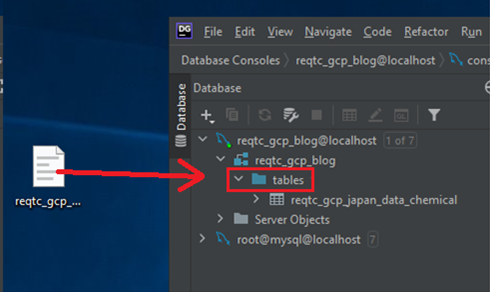
検証で利用するCSV形式のデータを如何にMySQLのデータベースに投入するかは、いろいろやり方があると思います。
長年利用され続けてきたほとんどのRDBMSと一部のNoSQLに対応し、データベース統合開発環境として利用されている、JetBrains社のDataGripを今回は利用して、CSVデータをDBに投入します。
https://www.jetbrains.com/ja-jp/datagrip/
一般的なやり方ですと、テーブルの作成、データ型の指定、場合によっては、エラーハンドリングなどの煩雑なオペレーションを行わないといけないのに対し、DataGripを利用するとほぼ全自動でやってくれる利点があります。
DataGripから対象データベースに接続したら、事前に入手したCSVデータファイルをDataGrip画面の対象データベースにドラッグアンドドロップするだけで、テーブル定義、データ型の定義などが瞬時に作成されます。もちろん、細かい要件に応じて、微調整も行えます。
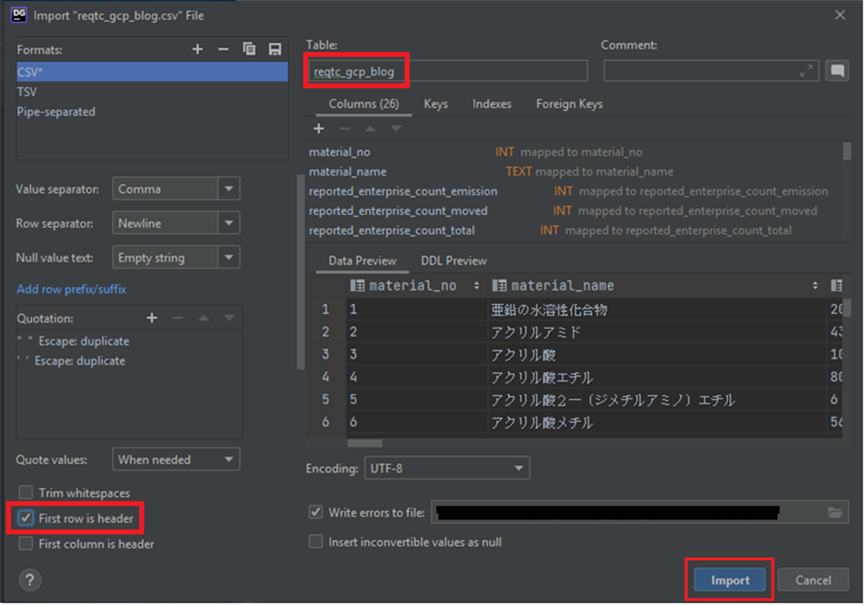
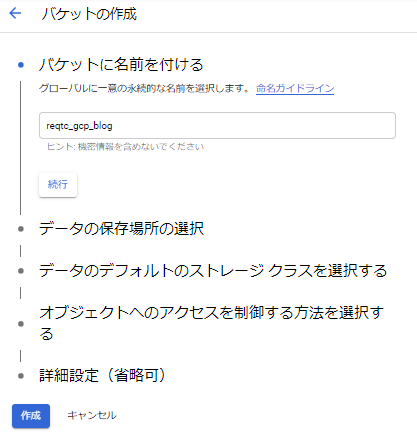
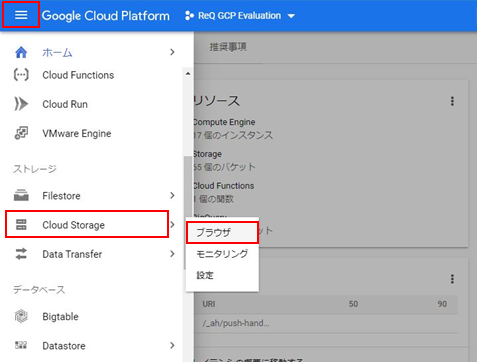
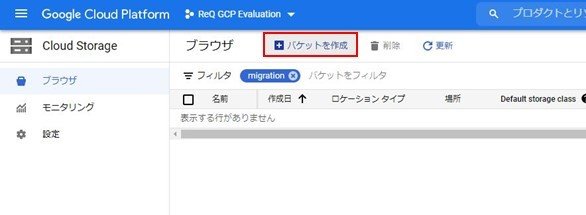
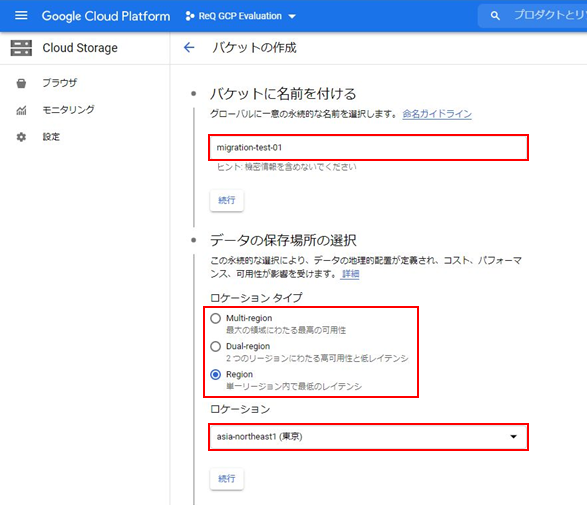
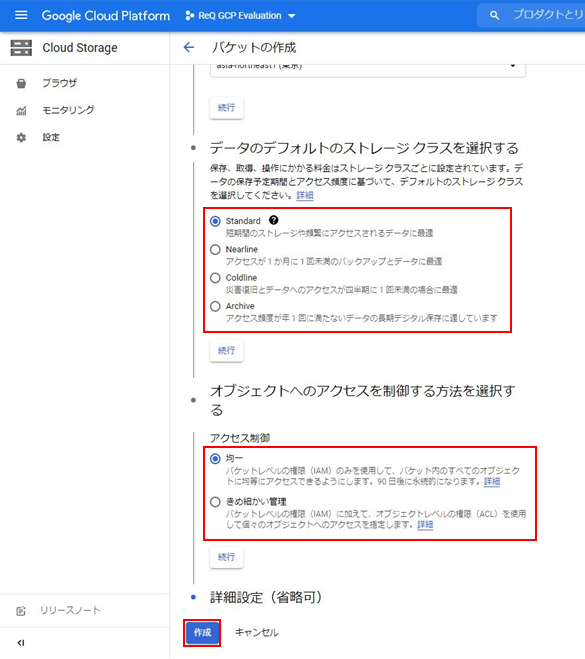
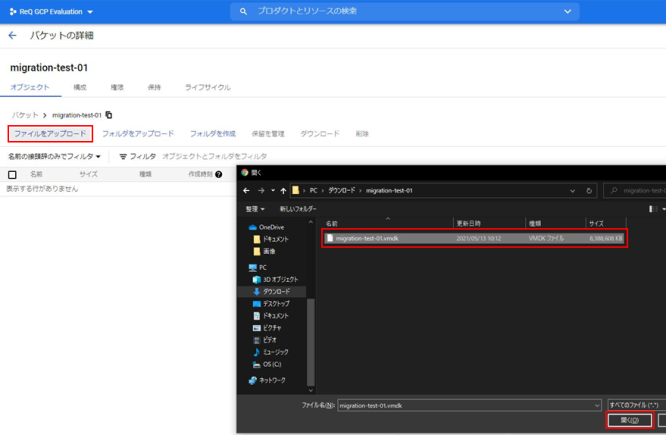
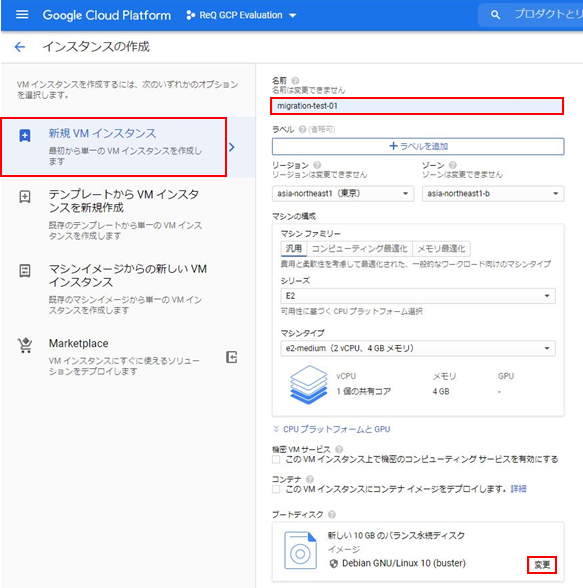
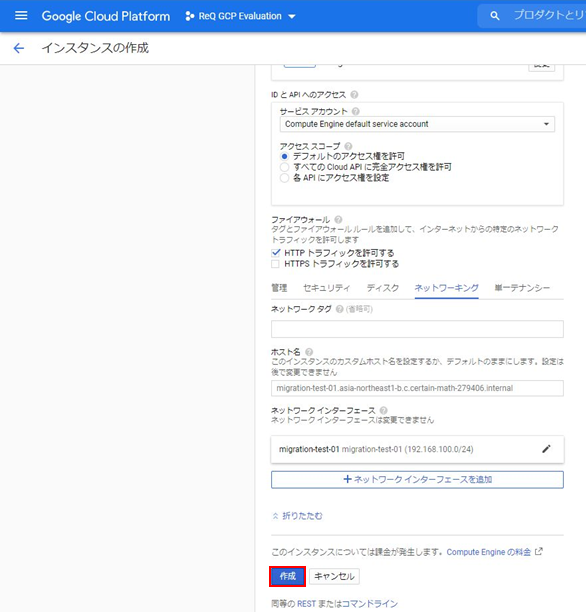
次はGCP Cloud Storageのバケットを作成します。
細かいところを無視して、バケットの名前のみ入力して作成します。
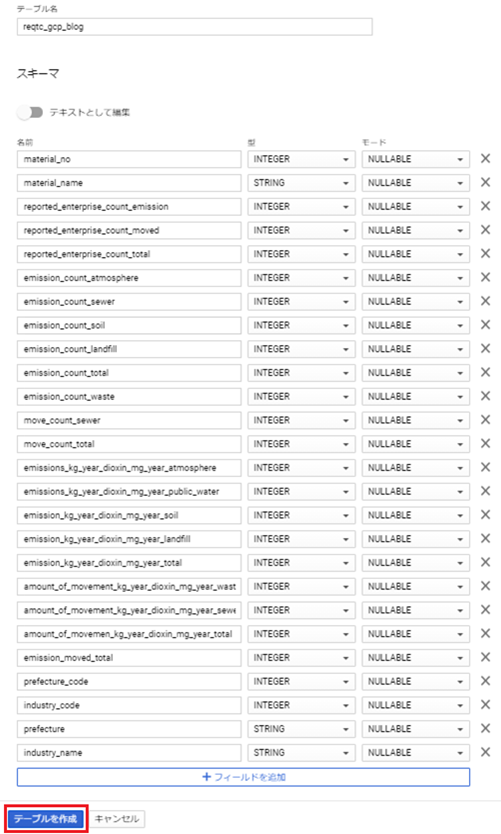
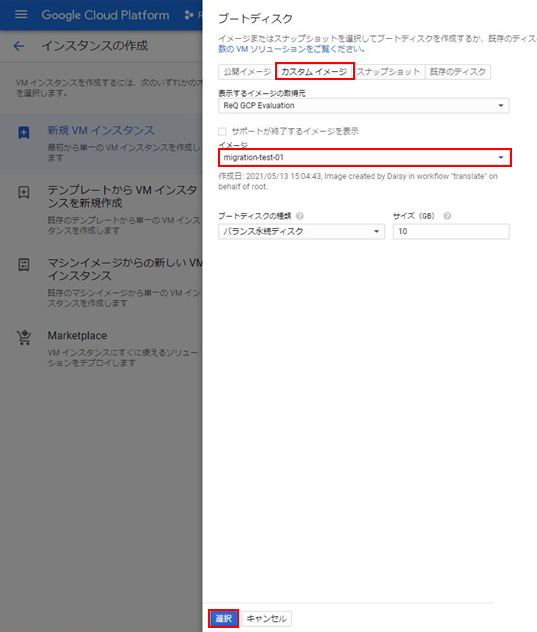
次はBigQueryテーブルを作成します。
自動生成されたカラム名とデータ型が問題ないか確認して、テーブルを作成します。
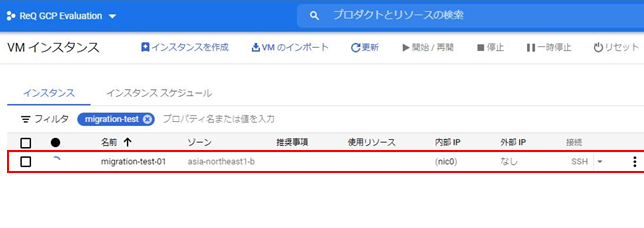
ここでは定期的にデータベースからデータを抽出することを想定してGCP Compute Engineを使用しますが、Cloud Functionでも対応できると思います。MySQLクライアントから、以下のSQL文でデータを抽出し、CSVデータとして一時的にローカルに保存します。
![]()

CSVファイルをCloud Storageへアップロードするには、以下のコマンドで実現します。
# gsuitl cp <CSVデータファイル名> gs://<バケット名>/<パス>

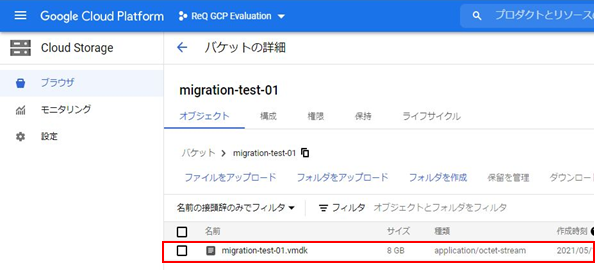
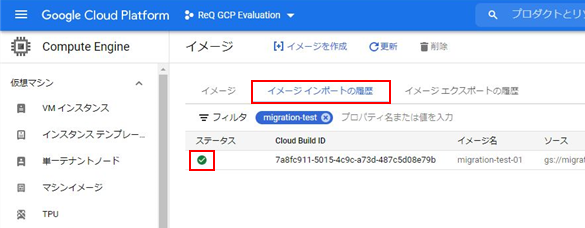
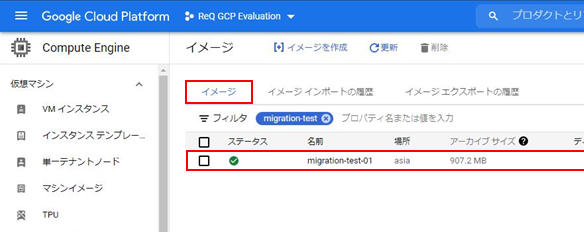
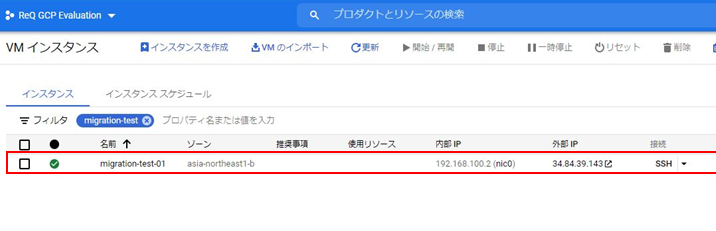
該当ファイルがCloud Storageにアップロードされたことを確認します。
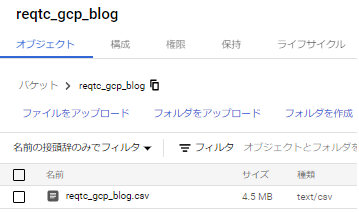
次はGCP Cloud Data Fusionの環境を構築します。
GCP Cloud Data Fusionを簡単で説明しますと、GUI環境でコードを意識せずに ETL / ELT パイプラインが作成できるサービスです。
実態はビックデータ解析・分析として有名はApache Sparkなので、GUIのあるApache Sparkサービスとも言えるでしょう。
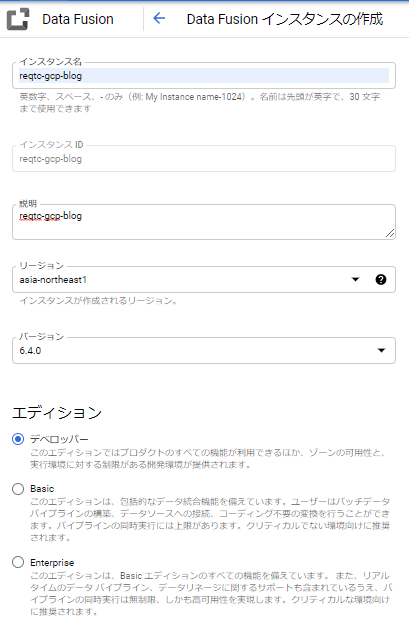
作成が完了するまでは数分かかります。完了したら「インスタンスを表示」をクリックします。
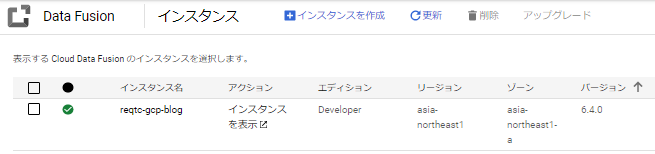
「Wrangler」をクリックします。
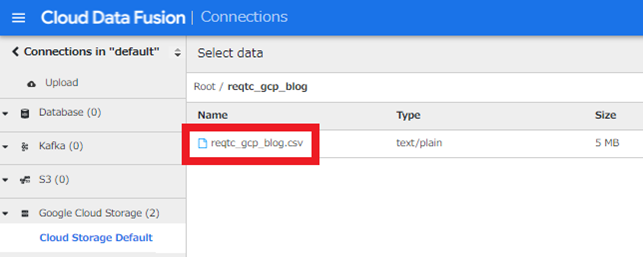
事前にCloud StorageへアップロードしたCSVをクリックします。
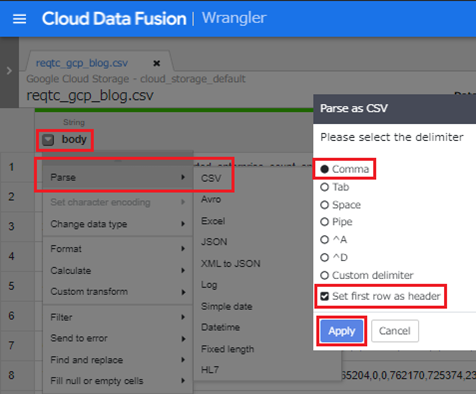
最初はテキストファイルとして認識されていますが、以下のように数回クリックすることで簡単にCSVファイルとして認識させることができます。
今回の検証では利用しない機能ですが、以下のように機密情報などは簡単にマスキングすることもできます。
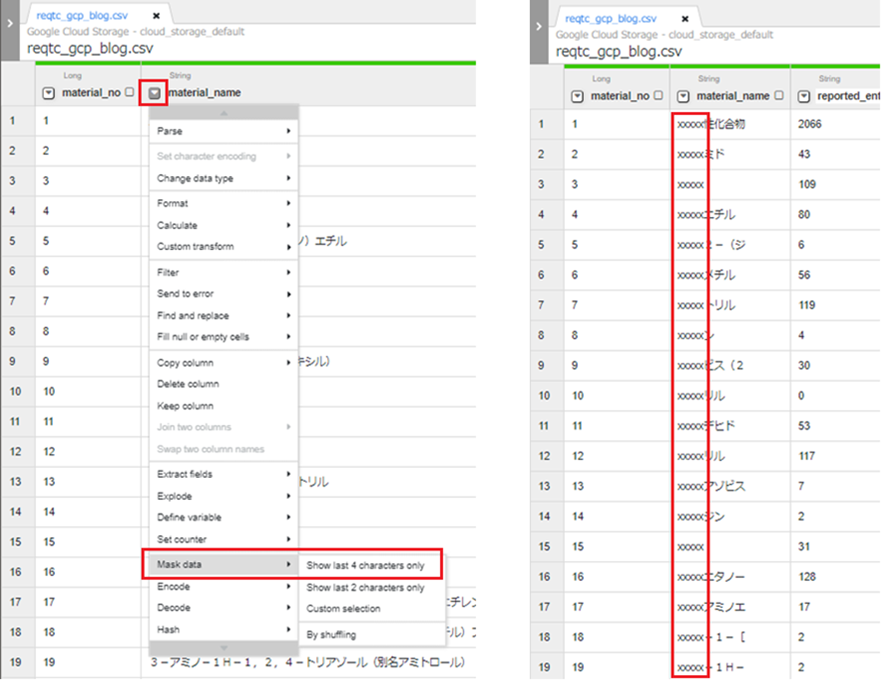
ほかにも、データ加工する機能、計算、変換、フォーマット変更などいろいろあるので、ぜひ触って見てください。CSV認識、カラム削除、データ型変換など合計25ステップのデータトランスフォーメーションが提供されています。
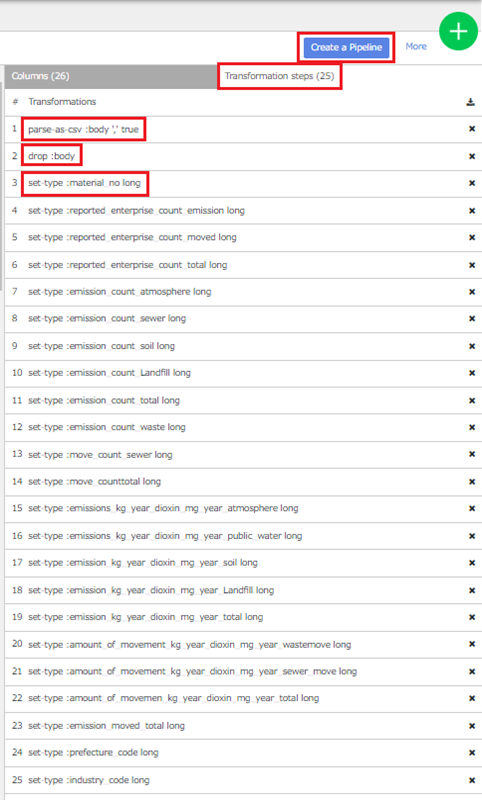
さて、Wranglerの右側にSink機能のBigQueryを追加して、加工したデータの出力先をBigQueryに指定します。あわせて、BigQueryのプロパティの出力先のプロジェクトID、データセット名とテーブル名を入力して保存し、デプロイます。
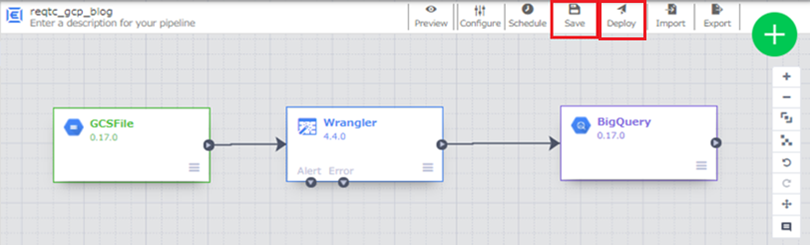
検証なので、クラスターのCPU、メモリ、ノート数などのサイジングはすべてデフォルトのままで実行します。ここで最重要かつ行わなければいけないことは、エラーが発生しないように祈ることです。笑
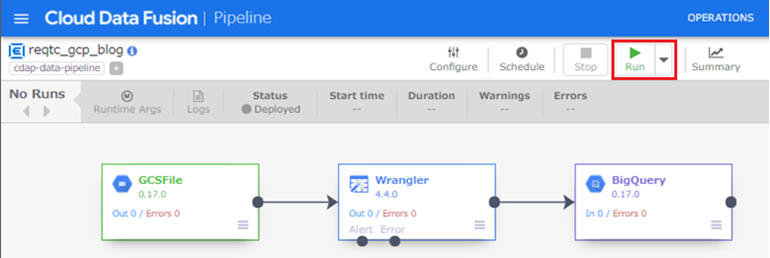
さて、Status箇所で「Succeeded」が確認できました。
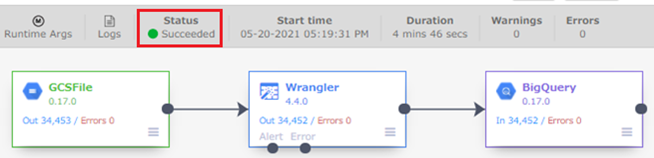
GCP BigQueryにデータが入っているかどうかを確認します。

BigQueryにデータが確認できたら、データの見える化、可視化に移ります。
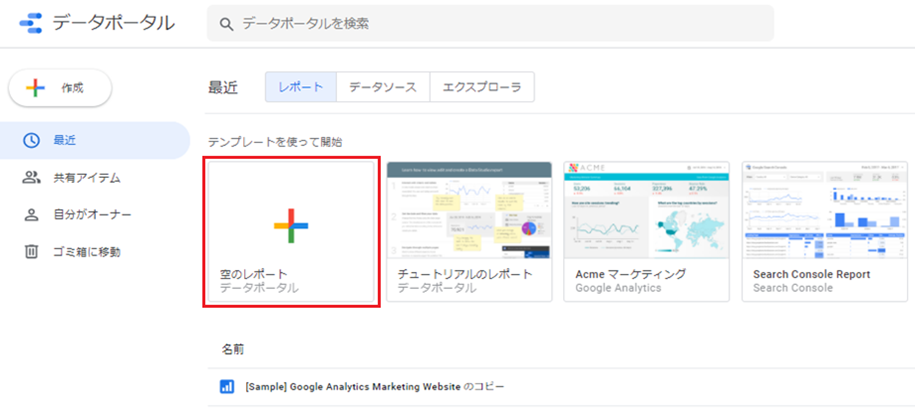
データポータルは、Google社が提供する無料のBIツールです。Googleアカウント同士であれば、簡単にユーザ間で結果を共有することができます。
データポータルのメインページはテンプレートがたくさんありますが、今回は空のレポートを指定します。
https://datastudio.google.com/
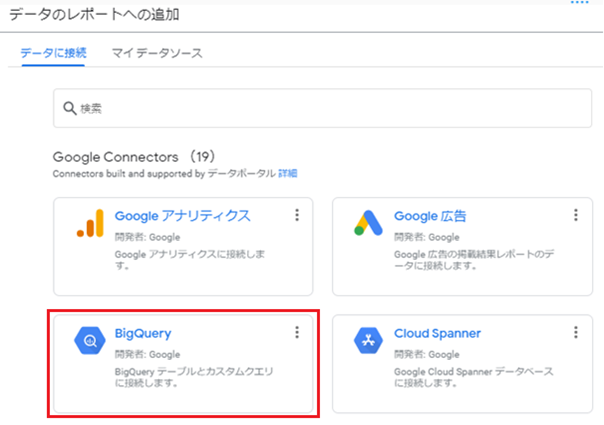
データの接続先として、BigQueryを選択します。
プロジェクト、データセット、テーブルを指定します。
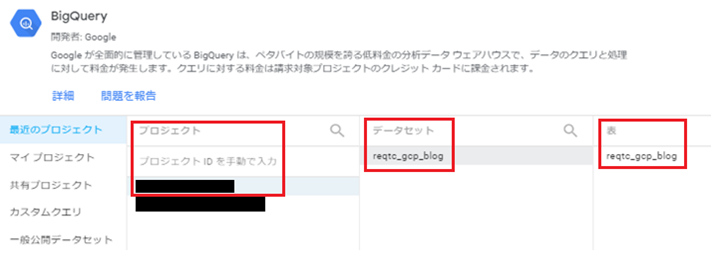
対象テーブルを指定すると、以下のような画面が表示されます。
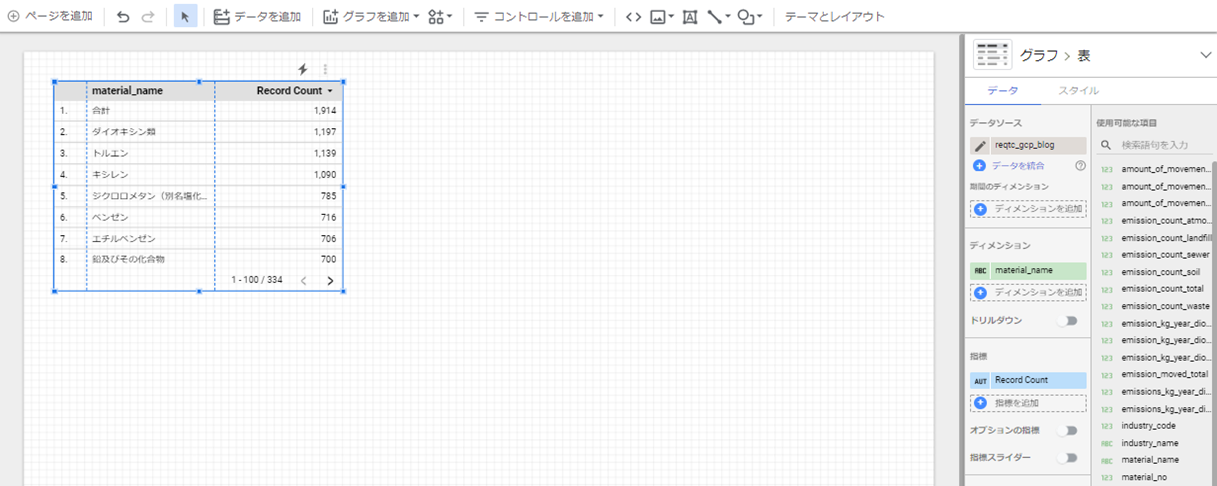
グラフやチャートのタイプを選択するなど数回のクリックと、数分待つことで、以下のような綺麗なダッシュボードになります。
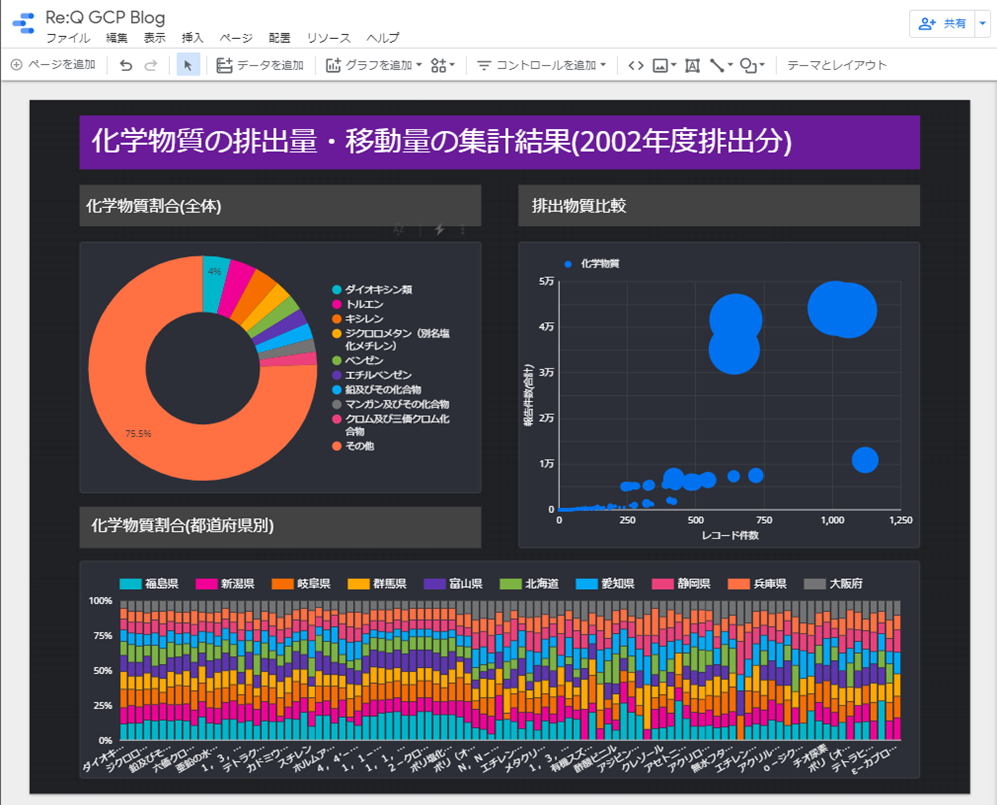
最後、完成した可視化できたデータを依頼者へ共有して完了となります。
検証は以上となります。
1. BigQueryのデフォルト課金はオンデマンド課金のため、対策をせずに大量・不必要なクエリを実行すると、恐ろしい金額で請求される場合がある
2. GCP Cloud Data Fusionで文字列を数字に変換する際、Integer型へ変換失敗した場合はLong型を検討する
3. 現時点では、GCP Cloud Data Fusionのユーザ・インタフェースは英語しかない
4. GCP BigQueryとCloud Data Fusionのテーブルは日本語のカラム名に対応していない
→ 早い段階でカラムを英語へ変換したほうが楽ですね。
今後については、以下の3点をブログで公開予定です。
1. ソースとなるデータベースをAWSのRDSと連携
2. AWS Lambda・GCP Cloud Functionsでデータを抽出して、CloudStorageにアップロードする部分を自動化
3. マルチクラウド環境で、如何に効率よく、かつ、セキュアなデータ連携を実現できるか、を考察
今後も是非、弊社の技術ブログを見守ってください!
最後までお読みいただきありがとうございます。
このように、小規模から大規模なデータセットを簡単かつ迅速に安価なデータ分析基盤を作成できました。蓄積したデータを有効に活用できていないなと感じている方、ぜひお試しください!!!
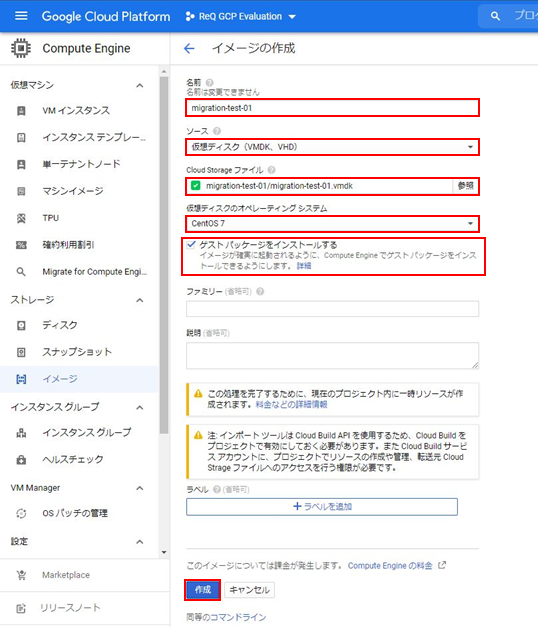
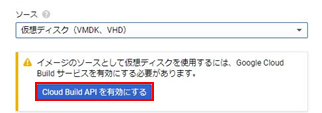
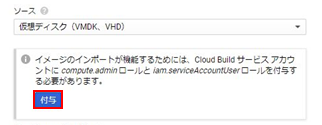
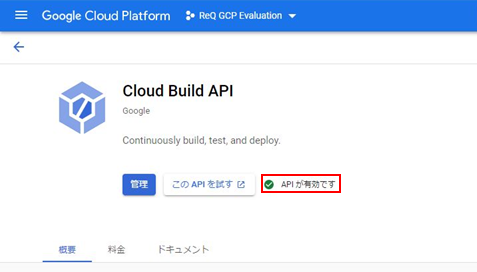
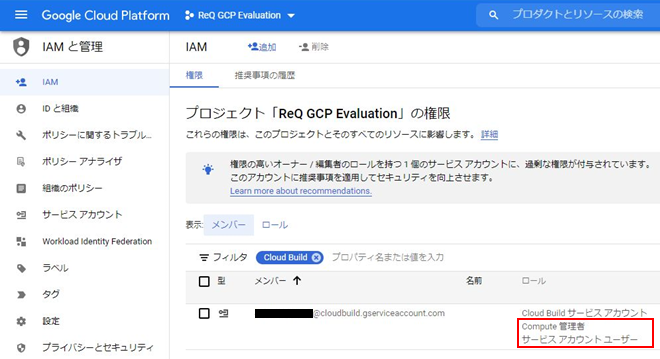
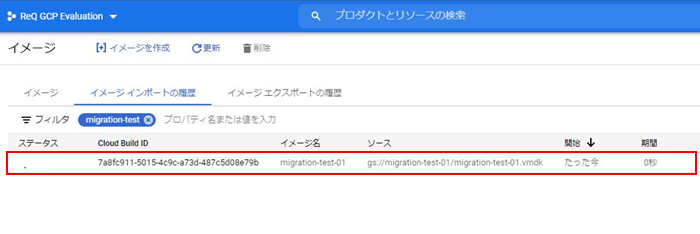
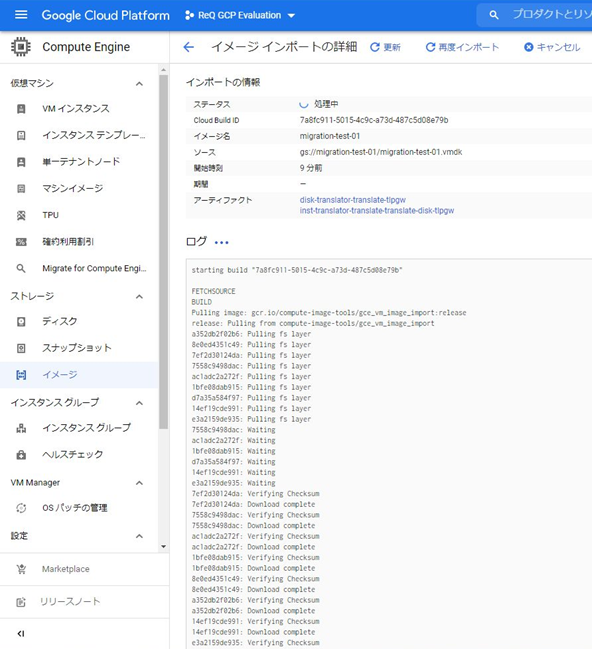
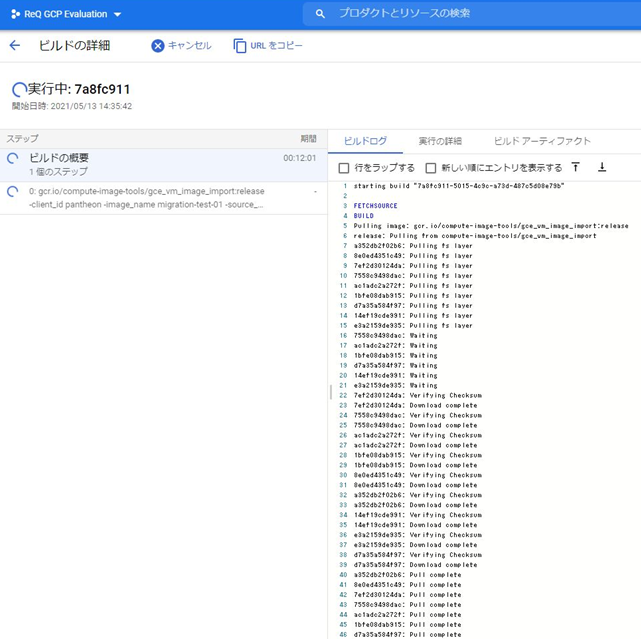
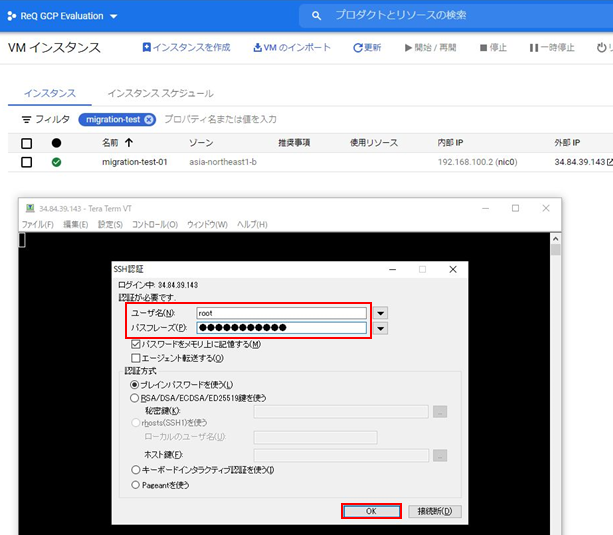
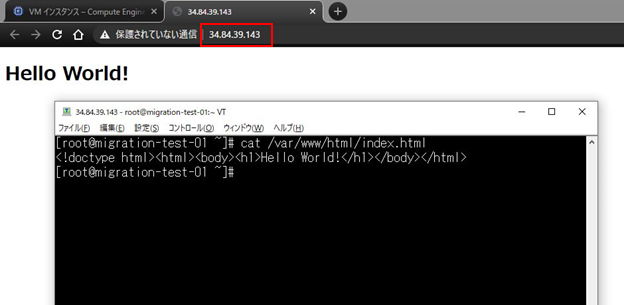
・ip a
・ip a
・/etc/sysconfig/network-scripts/ifcfg-eth0
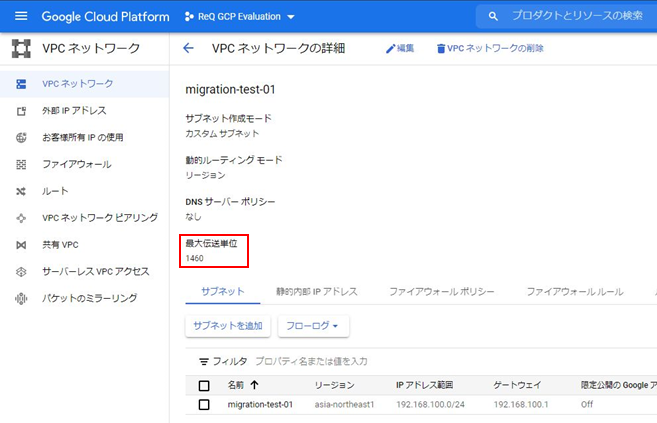
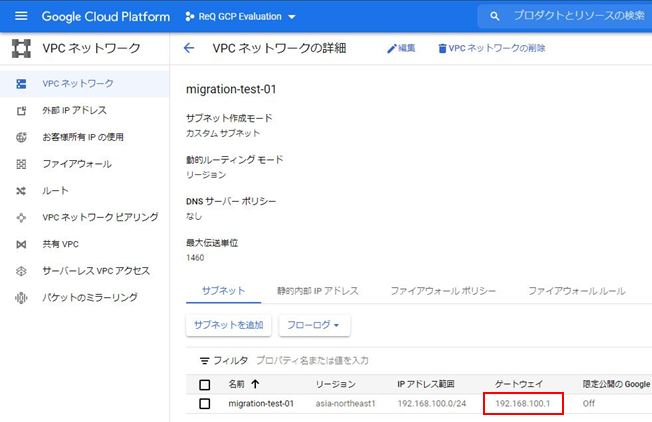
・ip route
・ip route

| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
|---|---|---|---|---|---|---|
| « 2月 | 9月 » | |||||
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 | |||||
